Como o Claude Code analisa notebooks Jupyter em Data Science: capacidade real, limites e alternativa melhor

O Claude Code consegue ler um notebook Jupyter, resumir seu conteúdo e reescrever células. Mas ele não funciona como um agente realmente integrado ao Jupyter que enxerga o kernel ativo, as variáveis atuais ou o estado vivo da execução. Na prática, ele trata um .ipynb principalmente como um arquivo estruturado.
Para desenvolvimento geral, isso pode ser suficiente. Para ciência de dados, muitas vezes não é. Em notebooks, importam a ordem de execução, os DataFrames, os outputs, os gráficos e o contexto do experimento.
Para complementar a leitura, vale ver também Python Notebook, JupyterLab vs Notebook e Jupyter AI com RunCell.
Resposta rápida
| Pergunta | Resposta |
|---|---|
| O Claude Code pode abrir um notebook Jupyter? | Sim |
| Pode resumir células e outputs salvos? | Sim |
| Pode editar células? | Sim |
| Pode executar células ou controlar o kernel? | Não |
| Pode ver variáveis vivas e DataFrames atuais? | Não como ferramenta runtime de verdade |
| Serve para um fluxo completo de Data Science? | Em geral não |
Onde o Claude Code ajuda de verdade
O Claude Code é útil quando o notebook é tratado como um artefato a ser revisado ou reorganizado.
- resumir a estrutura do notebook
- explicar o papel de cada célula
- reescrever código pandas bagunçado
- melhorar blocos markdown
- remover ou dividir células redundantes
Isso o torna útil para review, limpeza e reorganização. Mas não o transforma em um agente ideal para continuar um fluxo vivo dentro do Jupyter.
Como ele realmente trabalha com notebooks
O Claude Code tem duas capacidades importantes aqui:
- leitura especializada de
.ipynb - edição orientada a células
Mesmo assim, o limite continua sendo o arquivo.
1. Ele lê o JSON do notebook, não o runtime vivo
O Claude Code faz o parse do .ipynb, extrai células e outputs salvos e reorganiza esse conteúdo para o modelo.
O que ele não faz:
- não controla o kernel
- não orquestra o servidor Jupyter
- não inspeciona variáveis live
- não executa células
- não conduz um ciclo real de rerun
2. Ele edita células, mas continua regravando o arquivo
A edição é melhor do que um patch de texto bruto. O Claude Code consegue inserir, substituir e apagar células, além de limpar outputs antigos quando o código muda.
Isso mostra que ele entende o formato notebook, não que ele entenda o Jupyter como ambiente vivo.
O Claude Code entende a estrutura do arquivo notebook, não o runtime real do Jupyter.
Por que isso importa em ciência de dados
Em ciência de dados, o difícil não é apenas escrever Python correto. O difícil é manter o contexto certo:
- quais células já rodaram
- qual DataFrame é o atual
- se um gráfico veio de dados antigos ou novos
- se uma mudança upstream quebrou etapas posteriores
É por isso que agentes de código genéricos costumam parecer incompletos em notebooks.
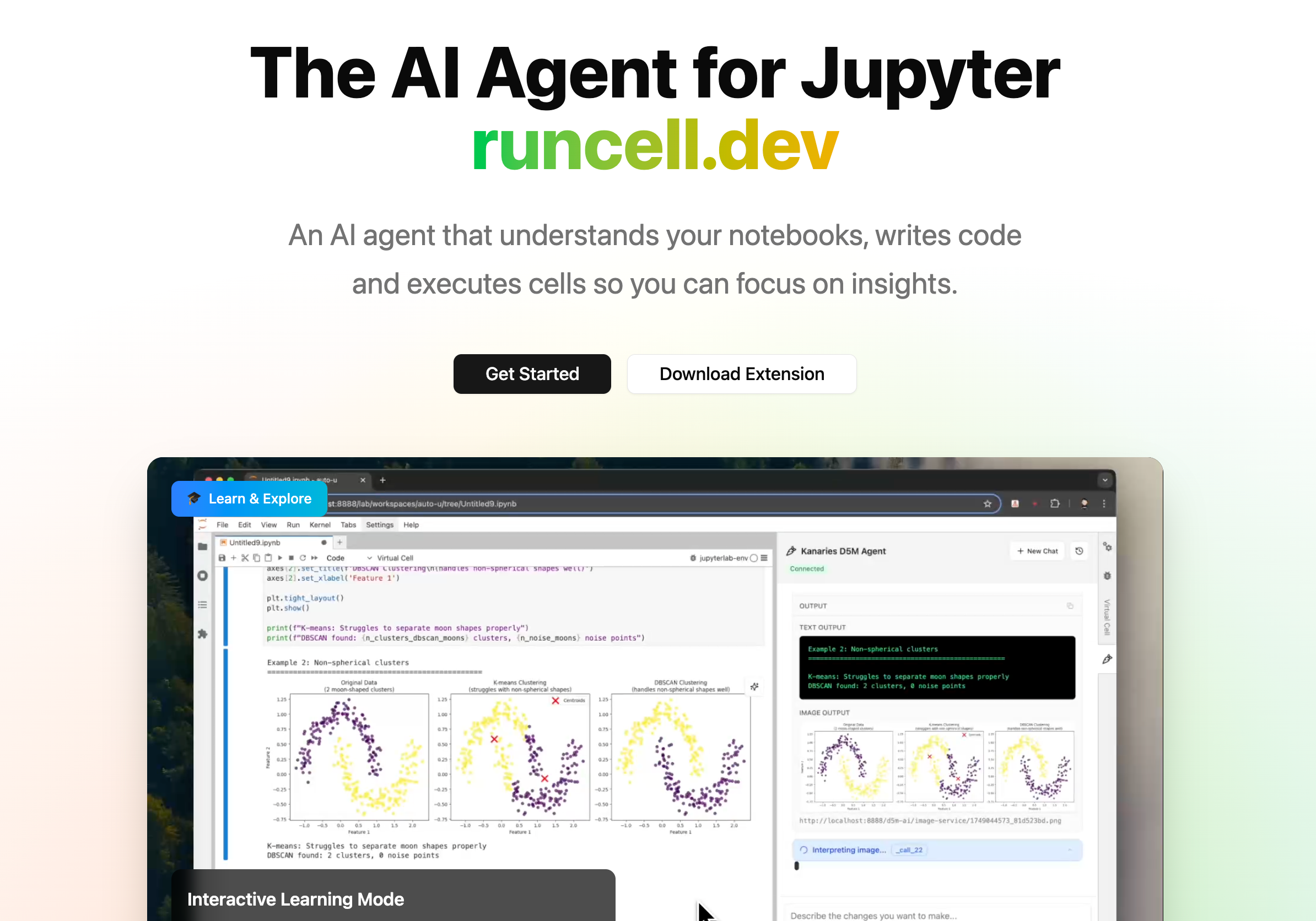
Por que o RunCell faz mais sentido em Jupyter
RunCell (opens in a new tab) fica interessante aqui por um motivo simples: para muita gente que trabalha com notebook, o problema nunca foi só “a IA consegue mexer no código?”.
O que costuma atrapalhar de verdade é isto:
- o notebook já foi executado até a metade e fica difícil lembrar quais células ainda são confiáveis
- o gráfico na tela pode não refletir mais os dados mais recentes
- uma mudança pequena no schema lá em cima pode quebrar várias células adiante
- o agente até reescreve o código, mas não necessariamente entende em que ponto da análise você está
É por isso que agentes genéricos de código parecem quase suficientes em Jupyter, mas não totalmente. Eles leem o arquivo, mas nem sempre entendem o que está acontecendo no notebook naquele momento.
RunCell não é apenas uma ferramenta genérica que também abre .ipynb. Ele é um agente de IA para Jupyter e ciência de dados. Na prática, isso significa menos troca de contexto, menos necessidade de voltar manualmente célula por célula e menos adivinhação para decidir se o output ainda corresponde ao estado atual da análise.
| Necessidade | Claude Code | RunCell |
|---|---|---|
| Ler e editar notebooks | Sim | Sim |
| Trabalhar com o estado do notebook | Limitado | Nativo |
| Tratar DataFrames e células como sinal principal | Limitado | Mais forte |
| Iterar a partir dos outputs | Indireto | Direto |
| Foco em workflows de Data Science | Geral | Especializado |
Se o seu trabalho é revisar ou limpar notebooks, Claude Code pode bastar.
Mas se o seu dia a dia parece mais com isto:
- EDA
- limpeza de dados
- feature engineering
- tuning de modelo
- olhar gráficos e depurar o notebook enquanto trabalha
então o RunCell costuma encaixar melhor. O objetivo não é só “arrumar um pedaço de código”, mas continuar a análise sem perder o fio.
Se você já passou por isso, a diferença aparece rápido: o agente ajuda a editar o .ipynb, mas depois você ainda precisa voltar, conferir outputs, checar variáveis e rerodar células antes de confiar no resultado. É justamente aí que RunCell (opens in a new tab) vira o próximo passo mais natural.