Top 9 Open-Source DataFrame-Bibliotheken für Python

Python hat sich als die bevorzugte Sprache für Entwickler und Datenbegeisterte etabliert. Ein Hauptgrund für seine Popularität im Bereich der Datenverarbeitung ist sein umfangreiches Ökosystem von Bibliotheken, insbesondere jene, die sich auf DataFrames konzentrieren. Diese leistungsstarken, tabellenartigen Strukturen ermöglichen eine einfache Manipulation und Analyse strukturierter Daten und sind für jeden, der mit Datensätzen arbeitet, unverzichtbar.
Falls Sie jemals Python für die Datenanalyse verwendet haben, sind Ihnen wahrscheinlich Pandas begegnet, die bekannteste und beliebteste DataFrame-Bibliothek. Doch mit zunehmender Größe und Komplexität der Daten sind neue Bibliotheken entstanden, um die Herausforderungen von Skalierung, Geschwindigkeit und Leistung zu bewältigen. In diesem Artikel unternehmen wir eine Reise durch einige der beliebtesten Open-Source-DataFrame-Bibliotheken in Python, die jeweils einzigartige Funktionen bieten, um Ihnen zu helfen, das Beste aus Ihren Daten herauszuholen.
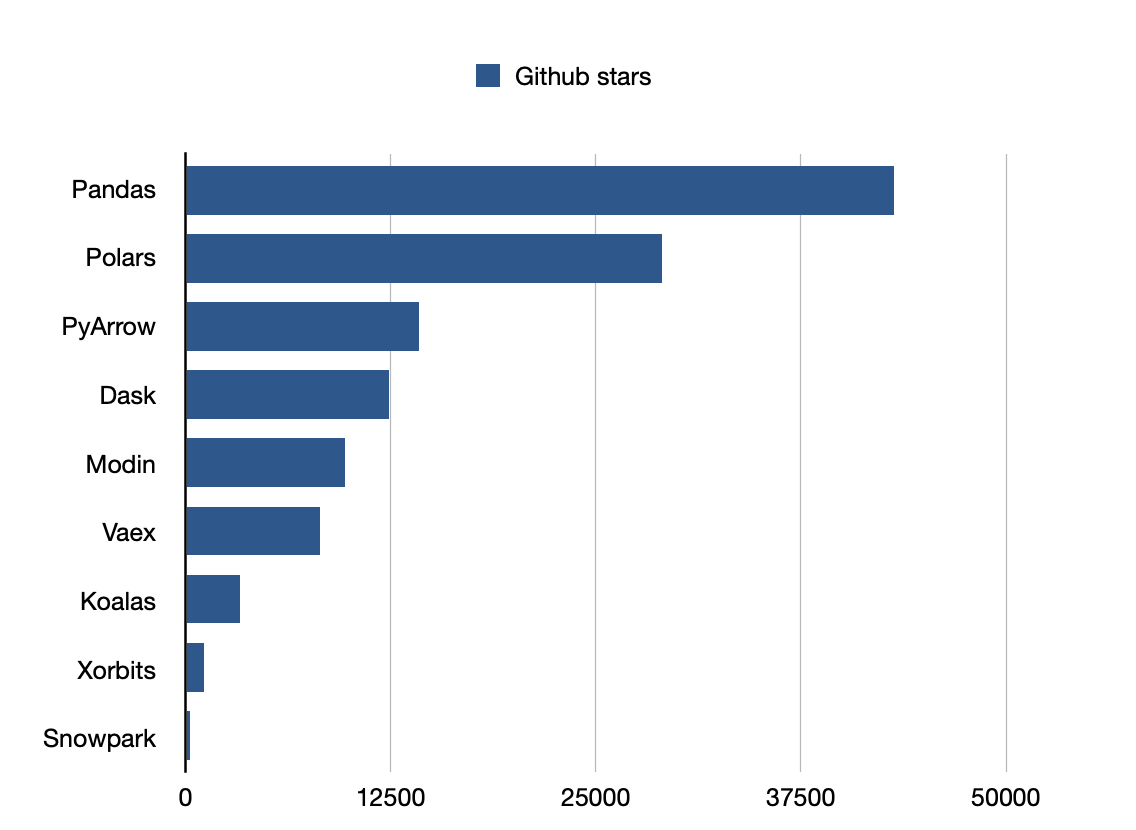
Pandas ist die beliebteste Bibliothek.
1. Pandas: Der Veteran der Datenwissenschaft
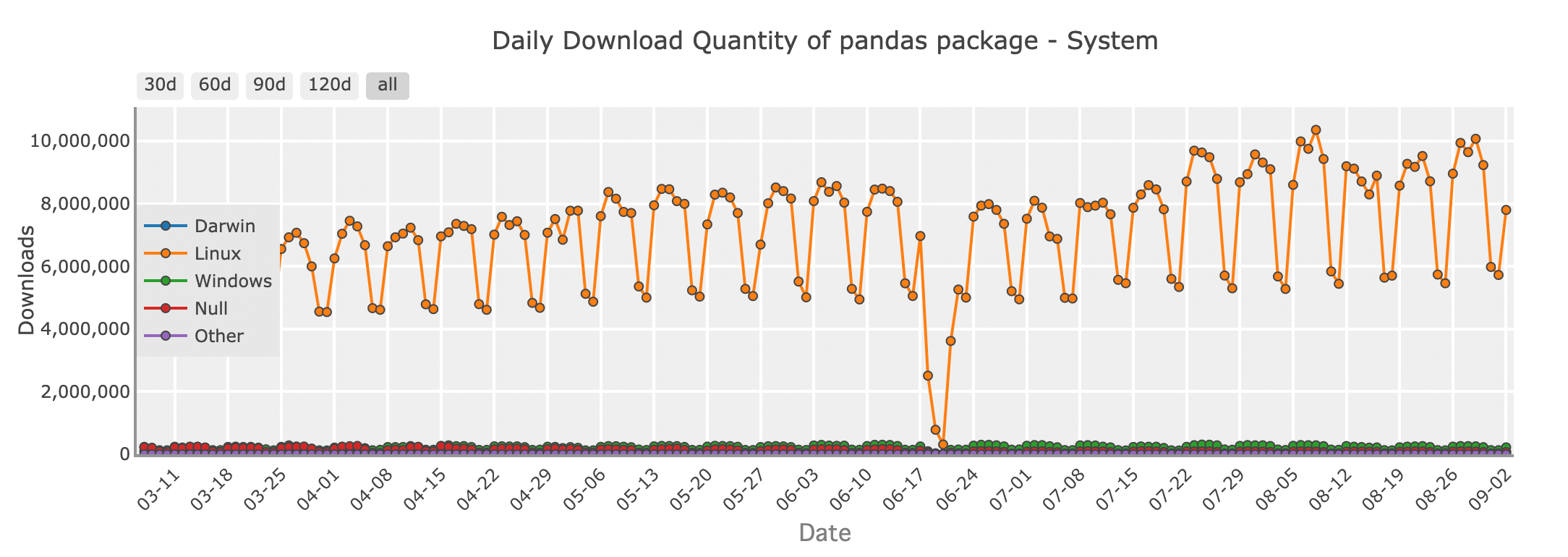
Tägliche Download-Menge des Pandas-Pakets - System
Für viele Python-Entwickler ist Pandas die erste Bibliothek, die einem in den Sinn kommt, wenn man mit DataFrames arbeitet. Ihr reichhaltiger Funktionsumfang und die intuitive API machen das Laden, Manipulieren und Analysieren von Daten einfach. Ob Sie ein unordentliches Dataset aufräumen, Daten aus mehreren Quellen zusammenführen oder statistische Analysen durchführen, Pandas bietet alle Werkzeuge, die Sie in einem vertrauten, tabellenartigen Format benötigen.
Pandas ist hervorragend geeignet für die Handhabung kleiner bis mittlerer Datensätze, die bequem in den Arbeitsspeicher Ihres Computers passen. Es ist perfekt für alltägliche Datenaufgaben, vom Erkunden der Daten in Jupyter-Notebooks bis hin zum Aufbau komplexerer Pipelines in der Produktion. Aber wenn Ihre Datensätze wachsen, kann Pandas seine Grenzen zeigen. An dieser Stelle kommen andere DataFrame-Bibliotheken ins Spiel.
Github-Sterne: 43200
2. Modin: Pandas auf neue Höhen skalieren
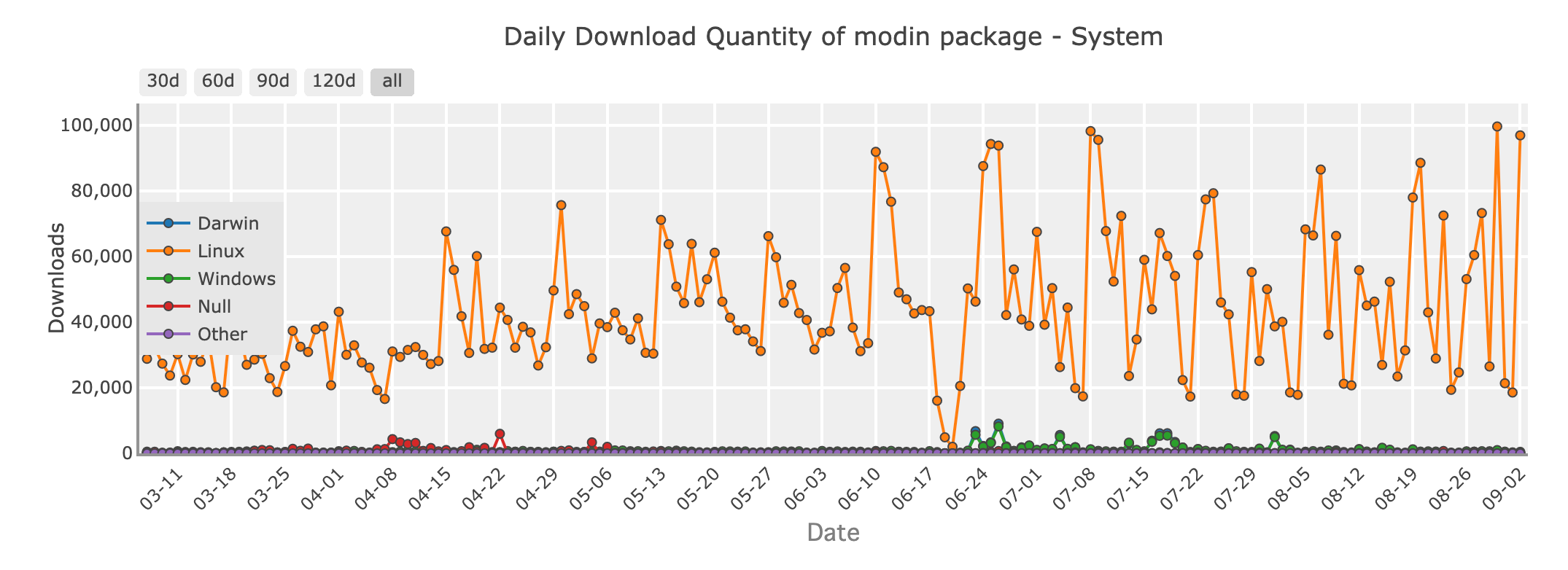
Tägliche Download-Menge des Modin-Pakets - System
Stellen Sie sich vor, Sie arbeiten mit einem Datensatz, der zu groß ist, als dass Pandas ihn effizient verarbeiten könnte. Sie möchten Ihren gesamten Code nicht neu schreiben, aber Sie benötigen mehr Geschwindigkeit und Skalierbarkeit. Hier kommt Modin ins Spiel, eine Bibliothek, die darauf ausgelegt ist, Ihren Pandas-Code schneller laufen zu lassen, ohne dass größere Änderungen erforderlich sind.
Modin ist ein direkter Ersatz für Pandas, was bedeutet, dass Sie Ihren vorhandenen Pandas-Code einfach parallelisieren können, indem Sie die Importanweisung ändern. Im Hintergrund verwendet Modin leistungsstarke Frameworks wie Ray oder Dask, um Ihre Berechnungen auf mehrere Kerne oder sogar einen Cluster von Maschinen zu verteilen. Dies bringt schnellere Verarbeitungszeiten für Ihre Datenoperationen.
Mit Modin erhalten Sie die vertraute Pandas-API, die Sie kennen und lieben, aber mit der Fähigkeit, größere Datensätze zu handhaben und die volle Leistung Ihrer Hardware zu nutzen.
Github-Sterne: 9700
3. Polars: Geschwindigkeit und Effizienz neu definiert
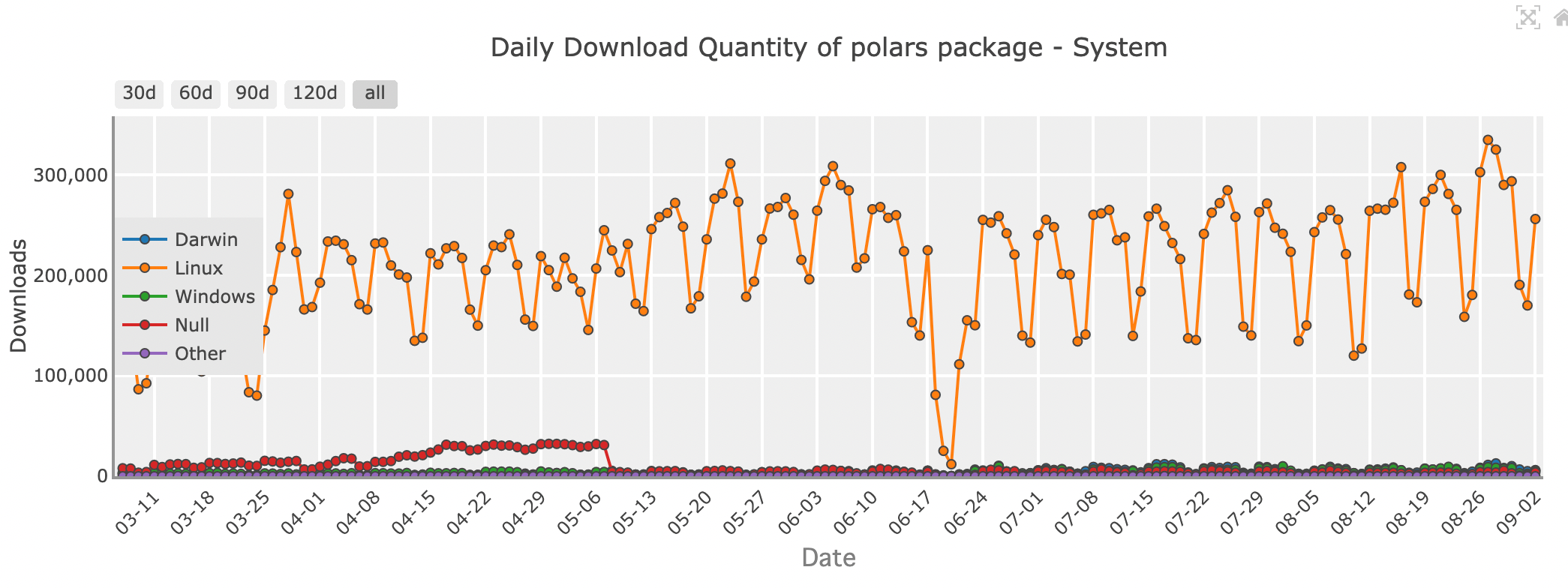
Tägliche Download-Menge des Polars-Pakets - System
Wenn es um rohe Geschwindigkeit und Effizienz geht, sorgt Polars in der Datenwissenschafts-Community für Aufsehen. In Rust geschrieben, einer Programmiersprache, die für ihre Leistung und Sicherheit bekannt ist, ist Polars darauf ausgelegt, schnell zu sein – wirklich schnell. Wenn Sie mit großen Datensätzen arbeiten oder komplexe Operationen schnell durchführen müssen, könnte Polars die richtige Bibliothek für Sie sein.
Polars verwendet eine Technik namens Lazy Evaluation, bei der Operationen nur ausgeführt werden, wenn es absolut notwendig ist. Dies ermöglicht es, den gesamten Berechnungsprozess zu optimieren und die erforderliche Zeit und Ressourcen zu minimieren. Darüber hinaus ist Polars für Multithreading ausgelegt, sodass es alle Kerne Ihres Rechners effizient nutzen kann, was es zu einer idealen Wahl für leistungskritische Aufgaben macht.
Obwohl Polars beeindruckende Geschwindigkeit bietet, ist es mit einer Lernkurve verbunden. Seine API unterscheidet sich von der von Pandas, daher kann es einige Zeit dauern, sich daran zu gewöhnen. Für diejenigen, die bereit sind, die Zeit zu investieren, bietet Polars jedoch unvergleichliche Leistung und die Fähigkeit, Datensätze zu handhaben, die mit anderen Bibliotheken einfach nicht machbar wären.
Github-Sterne: 29000
| Merkmal/Aspekt | Pandas | Modin | Polars |
|---|---|---|---|
| Architektur | Single-threaded, Python/Cython | Multi-threaded, verteilt (Ray/Dask) | Multi-threaded, in Rust geschrieben |
| Leistung | Gut für kleine bis mittlere Datensätze | Skalierbar über mehrere Kerne oder Cluster | Extrem schnell, handhabt große Datensätze |
| Speicherverbrauch | Hoher Speicherverbrauch | Ähnlich wie Pandas | Geringerer Speicherverbrauch, Out-of-Core-Unterstützung |
| Benutzerfreundlichkeit | Sehr einfach, umfangreiche Community-Unterstützung | Einfache Umstellung von Pandas | Intuitive, aber unterschiedliche API |
| Ökosystem | Ausgereift, gut integriert mit anderen Bibliotheken | Kompatibel mit Pandas-Ökosystem | Kleineres Ökosystem, wächst jedoch |
| Anwendungsfälle | Kleine bis mittlere Datensätze, Datenmanipulation | Größere Datensätze, Skalierung von Pandas-Operationen | Hochleistungsrechnen, große Datensätze |
| Installation | pip install pandas | pip install modin[all] | pip install polars |
4. Dask: Ein verteilter DataFrame für Big Data
Tägliche Download-Menge des Dask-Pakets - System
Wenn Ihre Daten so groß werden, dass sie nicht mehr in den Speicher passen, kann Dask als leistungsstarker Assistent dienen. Dask ist eine Parallel-Computing-Bibliothek, die die Pandas-API erweitert, um Datensätze zu handhaben, die für eine einzelne Maschine zu groß sind.
Dask funktioniert, indem es Ihr großes DataFrame in kleinere Stücke zerlegt und diese parallel verarbeitet, entweder auf Ihrem lokalen Rechner oder über einen Cluster verteilt. Dies ermöglicht es Ihnen, Ihre Berechnungen zu skalieren, ohne sich Sorgen machen zu müssen, dass Ihnen der Speicher ausgeht. Ob Sie mit Big Data arbeiten oder Datenpipelines aufbauen, die auf Tausende von Aufgaben skalierbar sein müssen, Dask bietet die Flexibilität und Leistung, die Sie benötigen.
Github-Sterne: 12400
5. PyArrow: Schneller Datenaustausch mit Apache Arrow
Tägliche Download-Menge des PyArrow-Pakets - System
Im Bereich des Daten-Engineerings glänzt PyArrow als eine entscheidende Bibliothek für den effizienten Datenaustausch zwischen verschiedenen Systemen. Auf dem Apache Arrow-Format aufgebaut, bietet PyArrow ein wunderbares, spaltenorientiertes Speicherformat, das Zero-Copy-Reads für große Datensätze ermöglicht. Dies macht es zu einer perfekten Wahl für Szenarien, in denen Leistung und Interoperabilität entscheidend sind.
PyArrow wird weit verbreitet eingesetzt, um schnellen Datentransfer zwischen Sprachen wie Python, R und Java zu ermöglichen und spielt eine entscheidende Rolle in vielen Big Data-Verarbeitungsframeworks. Wenn Sie große Datenpipelines verwalten, insbesondere wenn Daten zwischen verschiedenen Werkzeugen oder Plattformen ausgetauscht werden müssen, ist PyArrow ein wertvolles Werkzeug in Ihrem Arsenal.
Github-Sterne: 14200
6. Snowpark: DataFrames in der Cloud mit Snowflake
Tägliche Download-Menge des Snowpark-Pakets - System
Da immer mehr Organisationen ihre Datenoperationen in die Cloud verlagern, erweist sich Snowpark als innovative Lösung für Python-Entwickler. Snowpark ist ein Feature von Snowflake, einem cloudbasierten Data Warehouse, das Ihnen erlaubt, DataFrame-ähnliche Operationen direkt innerhalb der Snowflake-Umgebung durchzuführen. Das bedeutet, dass Sie komplexe Daten-Transformationen und Analysen durchführen können, ohne Ihre Daten aus Snowflake herauszubewegen, wodurch die Latenz reduziert und die Effizienz erhöht wird.
Mit Snowpark können Sie Python-Code schreiben, der nativ auf der Snowflake-Infrastruktur ausgeführt wird und die Leistungsfähigkeit der Cloud nutzt, um massive Datensätze problemlos zu verarbeiten. Es ist eine ausgezeichnete Wahl für Teams, die bereits Snowflake verwenden und ihre Datenverarbeitungs-Workflows optimieren möchten.
Github-Sterne: 253
7. Xorbits: Eine einheitliche Lösung für skalierbare Datenwissenschaft
Tägliche Download-Menge des Xorbits-Pakets - System
Xorbits ist ein leistungsstarkes Framework, das entwickelt wurde, um Datenwissenschaftsoperationen über verteilte Umgebungen hinweg zu skalieren. Es bietet eine einheitliche API, die die Komplexitäten des verteilten Rechnens abstrahiert und es Ihnen ermöglicht, Ihre DataFrame-Operationen über mehrere Knoten hinweg zu skalieren, ohne sich um die zugrunde liegende Infrastruktur kümmern zu müssen.
Xorbits integriert sich problemlos mit bestehenden Tools wie Pandas, Dask und PyTorch, was es zu einer idealen Wahl für maschinelles Lernen und Datenwissenschaftsanwendungen macht, die Flexibilität erfordern. Ob Sie große Modelle trainieren oder riesige Datenmengen verarbeiten, Xorbits bietet die Flexibilität und Leistung, die erforderlich ist, um die Aufgabe zu bewältigen.
Github-Sterne: 1100
8. Vaex: Out-of-Core-DataFrames für effiziente Analysen
Tägliche Download-Menge des Vaex-Pakets - System
Wenn Sie mit riesigen Datensätzen arbeiten, die den Arbeitsspeicher Ihres Systems überschreiten, aber dennoch die Einfachheit von Pandas wünschen, ist Vaex eine Erkundung wert. Vaex ist für Out-of-Core-Berechnungen konzipiert, was bedeutet, dass es Datensätze, die größer als Ihr RAM sind, verarbeiten kann, indem es die Daten in Stücke zerlegt und verarbeitet, ohne alles gleichzeitig in den Speicher zu laden.
Vaex ist auf Geschwindigkeit optimiert und bietet Funktionen wie schnelles Filtern, Gruppieren und Aggregieren, wobei der Speicherverbrauch minimiert wird. Es ist besonders nützlich für Aufgaben wie Datenexploration, statistische Analyse und sogar maschinelles Lernen auf großen Datensätzen.
Github-Sterne: 8200
9. Koalas: Pandas für Big Data mit Apache Spark
Tägliche Download-Menge des Koalas-Pakets - System
Für Python-Entwickler, die in der Welt von Big Data arbeiten, ist Apache Spark ein vertrauter Name. Koalas ist eine Bibliothek, die Pandas mit Spark verbindet, sodass Sie Pandas-ähnliche Syntax auf verteilten Datensätzen anwenden können, die von Spark verwaltet werden. Das bedeutet, dass Sie die Skalierbarkeit von Spark nutzen können, während Sie Code schreiben, der sich wie Pandas anfühlt.
Koalas ist eine großartige Option, wenn Sie von Pandas zu Big-Data-Umgebungen wechseln, da es die Lernkurve für Spark minimiert und Ihnen erlaubt, Code zu schreiben, der skaliert, ohne die Einfachheit von Pandas zu verlieren.
Github-Sterne: 3300
Das richtige Werkzeug für den Job auswählen
Bei so vielen verfügbaren Optionen, wie wählt man die richtige DataFrame-Bibliothek für sein Projekt? Hier sind einige Richtlinien:
- Kleine bis mittlere Datensätze: Wenn Ihre Daten bequem in den Speicher passen, ist Pandas immer noch die beste Wahl aufgrund seiner Benutzerfreundlichkeit und reichhaltigen Funktionalität.
- Skalierung von Pandas: Wenn Sie bei Pandas auf Leistungsengpässe stoßen, aber Ihren Code nicht ändern möchten, bietet Modin einen einfachen Weg zu schnellerer Ausführung.
- Leistungskritische Aufgaben: Für Hochleistungsbedarfe und große Datensätze bietet Polars beeindruckende Geschwindigkeit und Effizienz dank seines schlanken Designs, was es besonders auf lokalen Geräten effektiv macht. Es ist jedoch wichtig zu beachten, dass Polars nicht primär für verteilte, großangelegte Datenverarbeitung entwickelt wurde, wo Lösungen wie Modin möglicherweise geeigneter sind.
- Big Data und verteiltes Rechnen: Bei der Arbeit mit Big Data sind Dask, Koalas und Xorbits hervorragende Optionen, um Ihre Berechnungen über mehrere Maschinen hinweg zu skalieren.
- Interoperabilität und Datenaustausch: Wenn Sie effizienten Datenaustausch zwischen verschiedenen Systemen oder Sprachen benötigen, ist PyArrow die beste Wahl.
- Cloud-basierte Operationen: Für diejenigen, die Cloud-Infrastruktur nutzen, bietet Snowpark eine einfache Integration mit Snowflake und ermöglicht leistungsstarke In-Datenbank-Berechnungen.
Ob Sie nun mit kleinen Datensätzen oder massiven, verteilten Datenpipelines arbeiten, es gibt eine Python-Bibliothek, die Ihren Bedürfnissen entspricht.