판다스로 데이터 시각화하기: 아름다운 인사이트 플랏 만들기
데이터 사이언스에 있어서 데이터 시각화는 복잡한 데이터셋의 인사이트를 도출하는데 매우 중요한 역할을 합니다. 그 중에서도, 파이썬의 판다스 플랏 라이브러리는 몇 줄의 코드만으로 멋진 인터랙티브 플랏을 만들어내는 강력한 도구입니다.
이번 기사에서는, 바 차트, 산점도, 파이 차트를 비롯한 다양한 유형의 시각화를 판다스 플랏을 이용해 만드는 방법을 알아보겠습니다. 또한, Pandas Plot을 구동하는 라이브러리인 Matplotlib을 설치하는 방법과, 파이썬 판다스와 통합되는 오픈소스 데이터 시각화 도구인 PyGWalker도 간단히 살펴볼 것입니다.
판다스 플랏으로 데이터 시각화하기
Matplotlib 설치하기
판다스 플랏을 이용해 시각화를 시작하기 전에, 우선 Matplotlib이 파이썬 환경에 설치되어 있는지 확인해야 합니다. 판다스 플랏은 그림을 그리는데 사용되는 데이터 시각화 라이브러리인 Matplotlib을 기반으로 작동합니다.
Matplotlib을 설치하기 위해서는 pip 패키지 매니저를 이용할 수 있습니다:
pip install matplotlib그리고 나서 Matplotlib을 import 합니다:
import matplotlib.pyplot as plt판다스 플랏으로 바 차트 만들기
판다스 플랏을 이용해 간단한 바 차트를 만들어봅시다. 방대한 기업의 월간 매출 데이터셋을 사용하겠습니다.
sales = {'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun'],
'Sales': [10000, 20000, 30000, 25000, 15000, 18000]}
df = pd.DataFrame(sales)
df.plot(kind='bar', x='Month', y='Sales')
plt.show()위 코드에서, 먼저 월간 매출 데이터를 딕셔너리로 만들고, 이를 판다스 데이터프레임으로 변환합니다. 그리고 나서, 데이터프레임의 plot 메소드를 이용해 x축과 y축을 지정해 바 차트를 만듭니다.
이렇게 생성된 바 차트는 월별 매출액을 막대형태로 시각화하고 있으며, x축에는 월 이름, y축에는 매출액이 라벨링되어 표시됩니다.
판다스 플랏으로 산점도 만들기
다음으로, 산점도를 만들어봅시다. 학생들의 시험 성적 데이터셋을 사용하겠습니다.
students = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emma', 'Frank'],
'Math': [70, 80, 90, 60, 75, 85],
'Science': [80, 70, 85, 65, 90, 75]}df = pd.DataFrame(students) df.plot(kind='scatter', x='Math', y='Science') plt.show()
위 코드에서는 먼저 학생 시험 점수 사전을 만들고 이를 Pandas DataFrame으로 변환합니다. 그런 다음 DataFrame의 plot 메서드를 사용하여 산점도를 만들어 x축과 y축을 지정합니다.
나타나는 산점도는 학생의 수학과 과학 점수 관계를 보여줍니다.
Pandas Plot을 사용하여 막대 차트 만들기
막대 차트는 데이터를 직사각형 그래프 형식으로 시각화하는 데 유용합니다. 이 섹션에서는 Pandas Plot을 사용하여 웹 사이트 트래픽 소스 샘플 데이터 집합을 사용하여 막대 차트를 만듭니다.
# Create bar chart
df['source'].value_counts().plot(kind='bar')
# Add title and axis labels
plt.title('Website Traffic Sources')
plt.xlabel('Traffic Source')
plt.ylabel('Number of Visits')위 코드에서는 value_counts() 함수를 사용하여 각 웹 사이트 트래픽 소스의 발생 횟수를 계산합니다. 그런 다음 plot() 함수에 kind='bar' 매개 변수를 전달하여 막대 차트를 만듭니다.
plt.title(), plt.xlabel(), plt.ylabel()를 사용하여 각각 타이틀, x축 라벨 및 y축 라벨을 추가하여 그림을 사용자 정의합니다.
Pandas Plot을 사용하여 파이 차트 만들기
마지막으로, Pandas Plot을 사용하여 파이 차트를 만들어 보겠습니다. 웹 사이트 트래픽 소스의 샘플 데이터 집합을 사용합니다.
traffic = {'Source': ['Search Engines', 'Direct Traffic', 'Referral Traffic', 'Social Media'],
'Traffic': [40, 20, 30, 10]}
df = pd.DataFrame(traffic)
df.set_index('Source', inplace=True)
df.plot(kind='pie', y='Traffic', autopct='%1.1f%%')
plt.show()색상, 크기 및 레이블과 같은 매개 변수를 사용하여 플롯 사용자 정의하기
Pandas Plot은 플롯의 모양을 사용자 정의하기 위한 다양한 매개 변수를 제공합니다. 이러한 매개 변수 중 일부를 살펴보겠습니다.
색상(color) : 플롯의 색상을 변경합니다. fontsize : 플롯의 글꼴 크기를 변경합니다. title : 플롯에 제목을 추가합니다. xlabel 및 ylabel : x축 및 y축에 레이블을 추가합니다. legend : 플롯에 범례를 추가합니다. grid : 그리드 선을 플롯에 추가합니다.
예를 들어, 이전에 만든 막대 차트의 색상을 빨강색으로 변경하려면 color='red' 매개 변수를 plot() 함수에 추가할 수 있습니다.
df['source'].value_counts().plot(kind='bar', color='red')플롯에 범례를 추가하려면 plot() 함수에 legend=True 매개 변수를 추가할 수 있습니다.
df['source'].value_counts().plot(kind='bar', legend=True)판다스 플롯 대안: Jupyter Notebook에서 PyGWalker 사용하기
PyGWalker는 데이터 분석 및 시각화 작업을 단순화하며 pandas dataframe(및 polars dataframe)을 시각적 탐색을 위한 tableau-alternative 사용자 인터페이스로 변환하여 Jupyter Notebook(또는 다른 jupyter 기반 노트북)을 Graphic Walker와 통합하여 Tableau의 오픈소스 대안을 제공합니다. 이를 통해 데이터 과학자는 간단한 드래그 앤 드롭 작업으로 데이터를 분석하고 패턴을 시각화할 수 있습니다.
| Kaggle에서 실행 (opens in a new tab) | Colab에서 실행 (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) |  (opens in a new tab) (opens in a new tab) |
PyGWalker는 오픈소스입니다. 꼭 PyGWalker GitHub (opens in a new tab)을 확인하고 ⭐️을 남겨주세요!
Jupyter Notebook에서 PyGWalker 사용하기
시작하려면 PyGWalker와 pandas를 Jupyter Notebook에 가져옵니다.
import pandas as pd
import PyGWalker as pyg기존 작업을 손상시키지 않고 PyGWalker를 사용할 수 있습니다. 예를 들어, Pandas Dataframe을 시각적 UI로 로드할 수 있습니다.
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)(polars의 경우 PyGWalker >= 0.1.4.7a0 이상에서도 사용 가능합니다):
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)Binder(https://mybinder.org/v2/gh/Kanaries/PyGWalker/main?labpath=tests%2Fmain.ipynb (opens in a new tab)), Google Colab(https://colab.research.google.com/drive/171QUQeq-uTLgSj1u-P9DQig7Md1kpXQ2?usp=sharing (opens in a new tab)) 또는 Kaggle Code(https://www.kaggle.com/asmdef/PyGWalker-test)를 (opens in a new tab) 방문하여 온라인에서도 사용해 볼 수 있습니다.
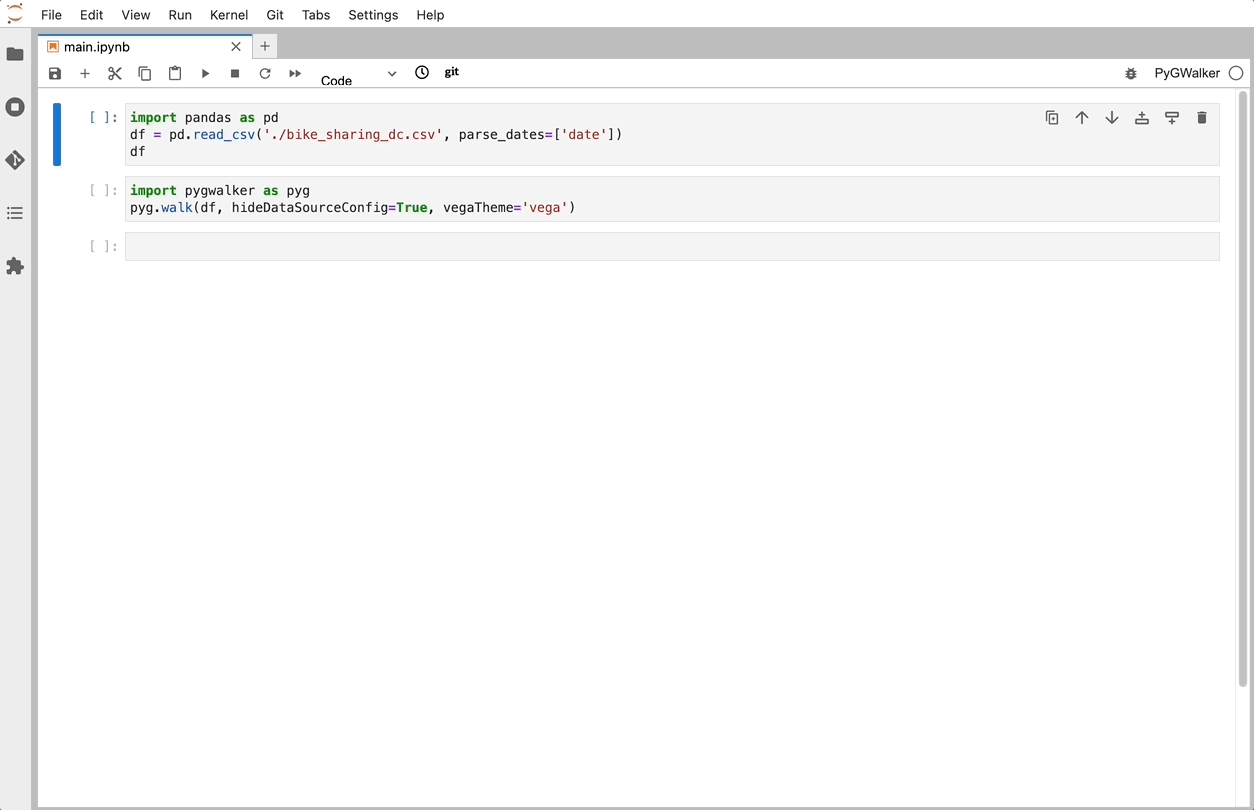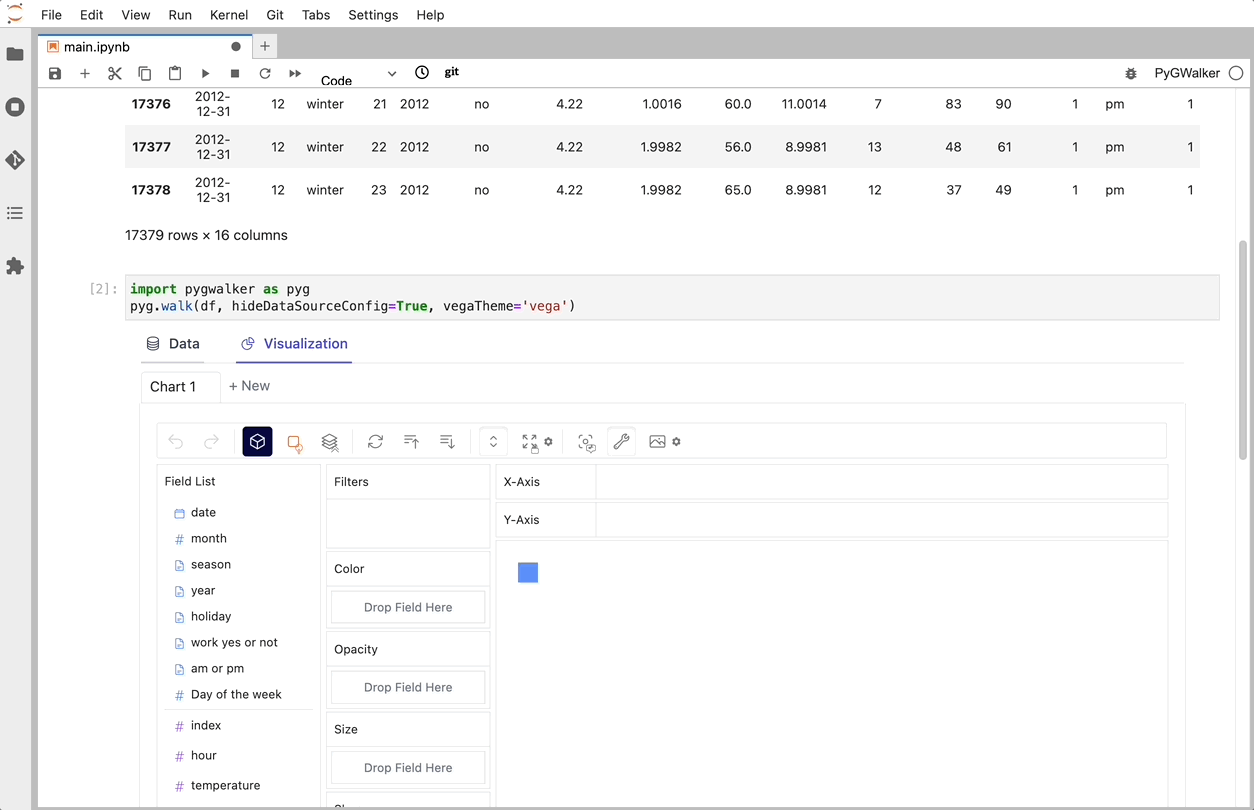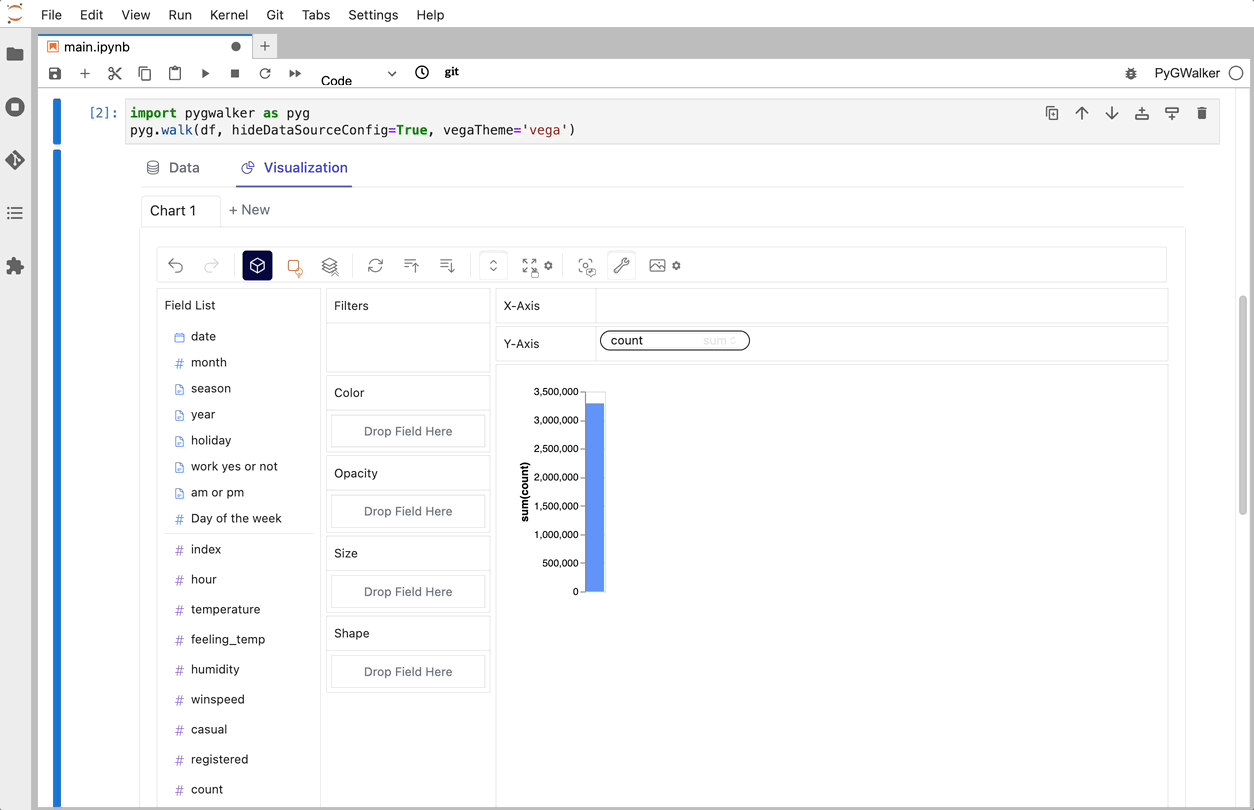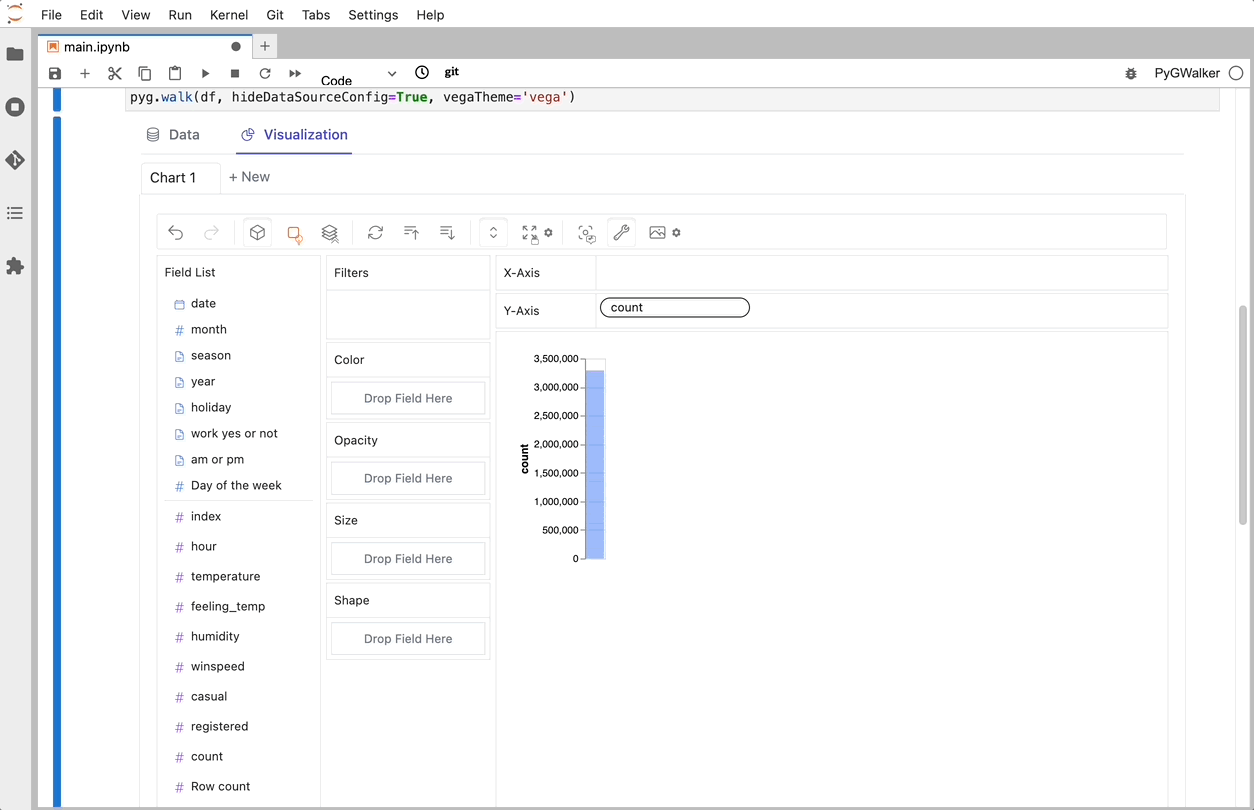
이제 변수를 드래그 앤 드롭하여 데이터를 분석하고 시각화하는 tableau-alternative UI가 있습니다.
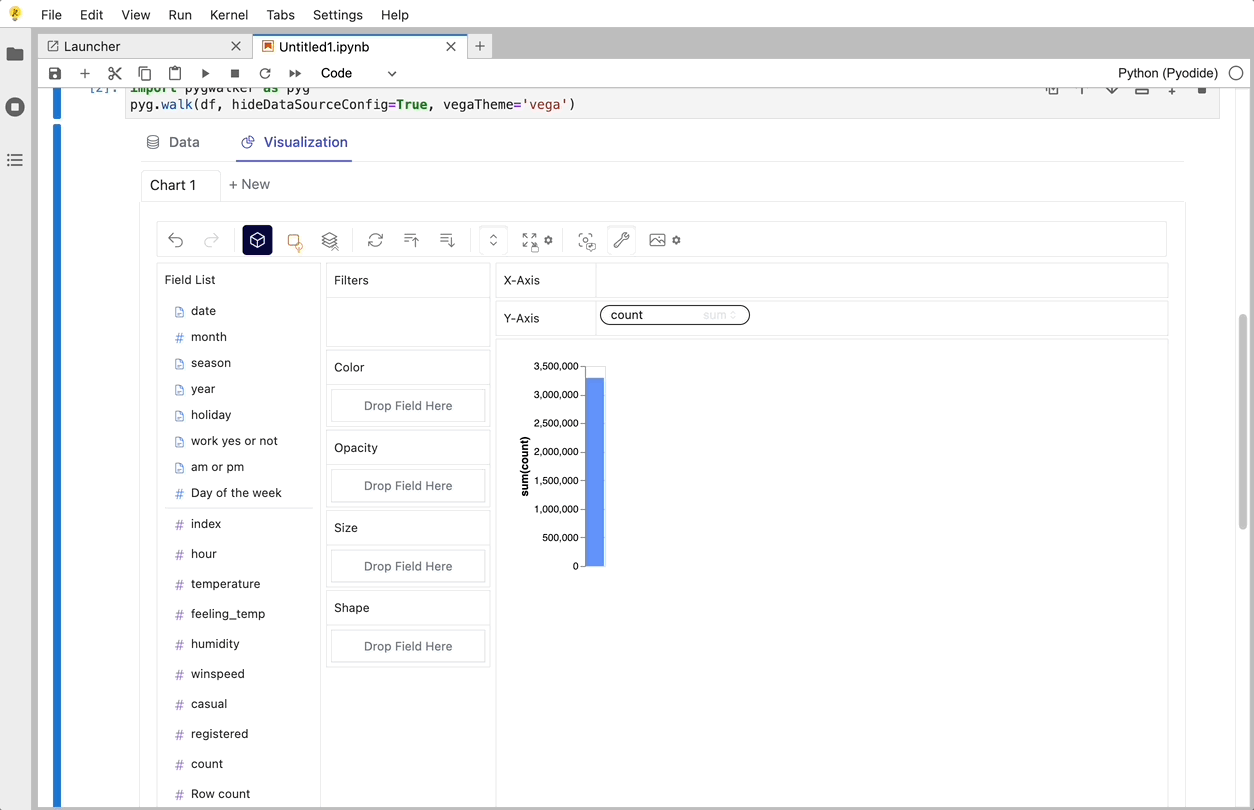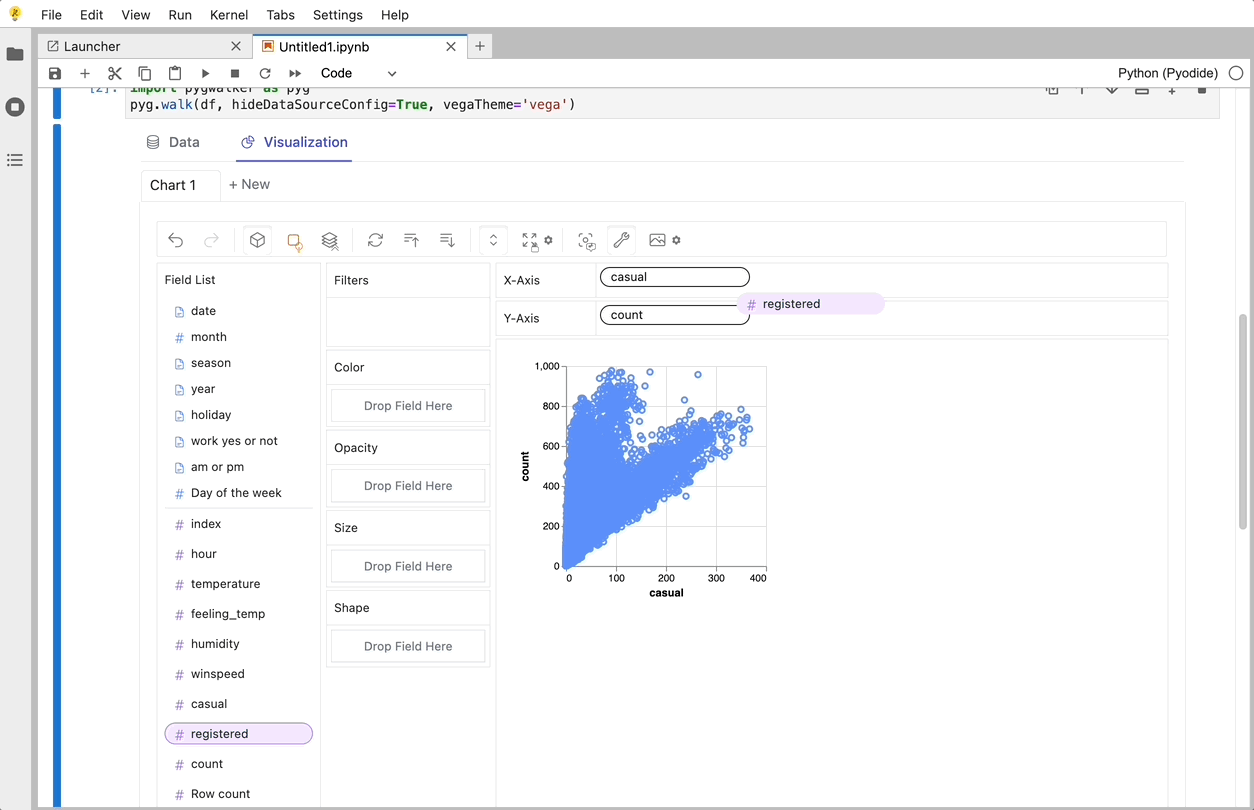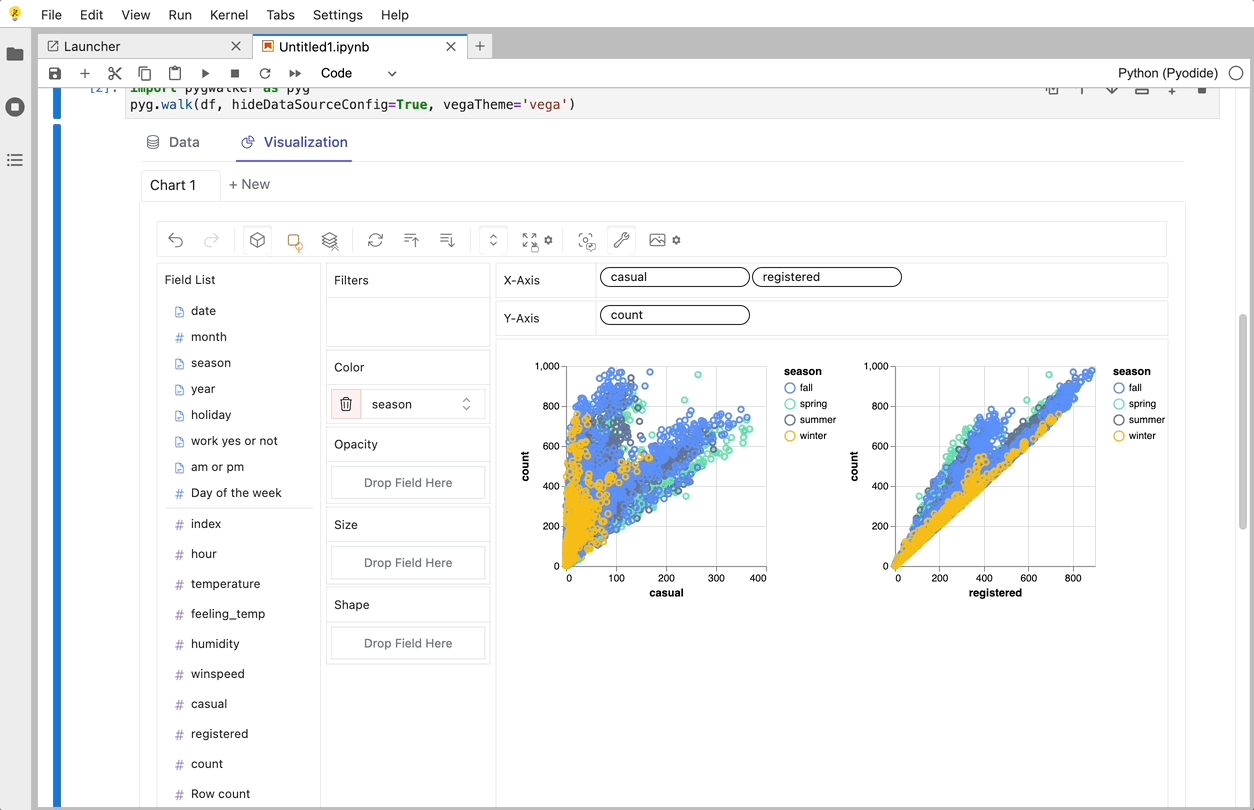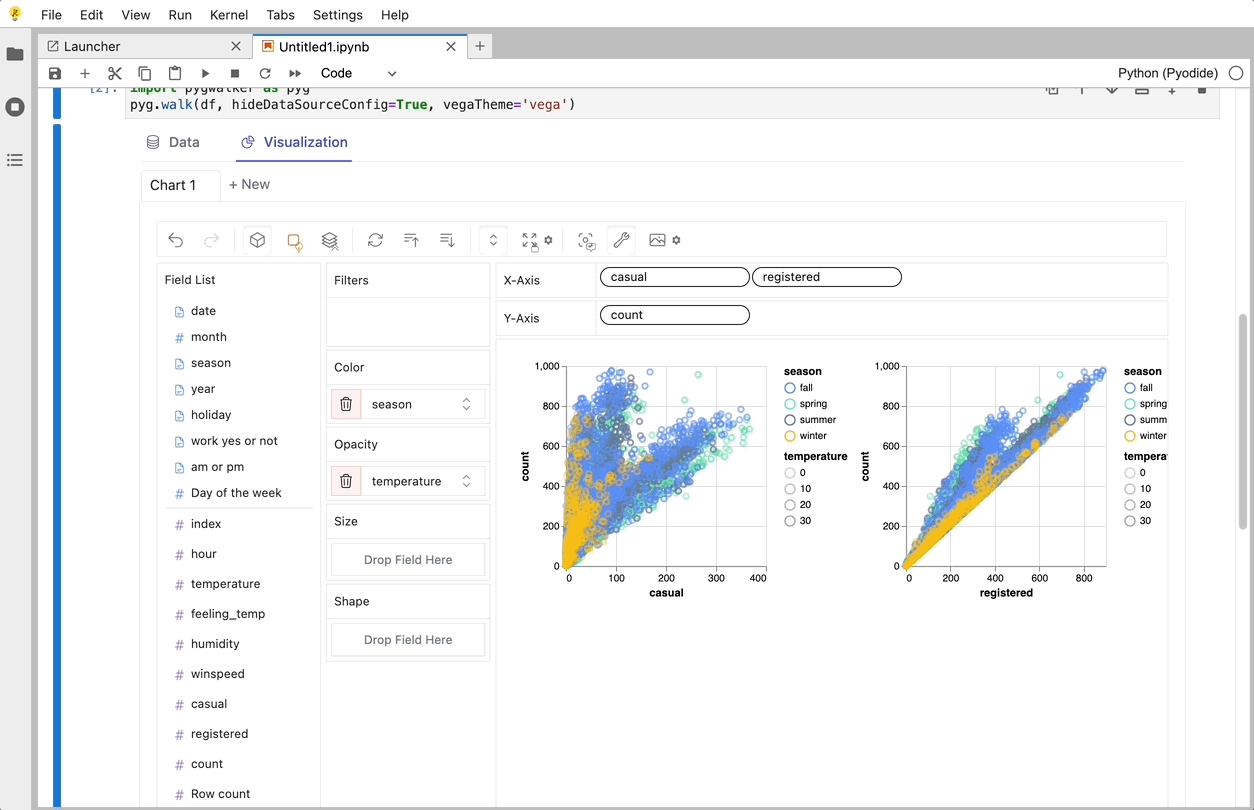
PyGWalker로 데이터 시각화 만들기
변수를 드래그 앤 드롭하여 지원하는 UI를 사용하여 이러한 차트를 생성할 수 있습니다.
막대 그래프  | 선 그래프  | 면적 그래프  |
|---|---|---|
트레일  | 산점도  | 원  |
틱 플롯  | 사각형  | 아크 다이어그램  |
박스 플롯  | 히트맵  |
더 많은 예제는 데이터 시각화 갤러리에서 확인하실 수 있습니다.
판다스 플롯으로 고급 플로팅하기
Pandas Plot은 서브플롯, 그룹화된 막대 그래프 및 쌓인 막대 그래프와 같은 향상된 플로팅 기능을 제공합니다. 이러한 기능 중 일부를 살펴보겠습니다.
서브플롯
**서브플롯(subplots)**은 하나의 그림 내에서 여러 그래프를 표시하는 강력한 방법입니다. 판다스 플롯으로 서브플롯을 만들려면 서브플롯 함수(subplots function)를 사용할 수 있습니다. 이 함수는 그림을 만들고 원하는 그래프를 만들기 위해 사용할 수 있는 서브플롯의 집합을 반환합니다. 예를 들어, 두 개의 데이터셋을 나란히 그래프로 표시하려면 다음 코드를 사용할 수 있습니다.
import pandas as pd
import matplotlib.pyplot as plt
data1 = pd.read_csv('data1.csv')
data2 = pd.read_csv('data2.csv')
fig, axs = plt.subplots(1, 2, figsize=(10, 5))
data1.plot(ax=axs[0])
data2.plot(ax=axs[1])이 코드에서는 먼저 두 데이터셋(data1과 data2)을 읽습니다. 그런 다음, 서브플롯 함수(subplots function)를 사용하여 두 개의 서브플롯으로 구성된 그림을 만듭니다. 1과 2 인수가 하나의 행과 두 개의 열의 서브플롯을 원한다는 것을 지정합니다. figsize 인수는 그림의 크기를 지정합니다.
그런 다음 data1을 첫 번째 서브플롯(axs[0])에, data2를 두 번째 서브플롯(axs[1])에 그립니다.
그룹화 된 막대 그래프
**그룹화 된 막대 그래프(grouped bar charts)**는 여러 데이터셋을 비교하는 유용한 방법입니다. 파이썬에서 Pandas Plot으로 구현할 때, width 인수를 1보다 작은 값으로 설정하여 bar 함수를 사용할 수 있습니다. 예를 들어, 그룹화 된 막대 그래프를 사용하여 두 개의 데이터셋을 비교하려면 다음 코드를 사용할 수 있습니다.
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('data.csv')
fig, ax = plt.subplots()
data.plot(kind='bar', x='Group', y=['Data1', 'Data2'], width=0.4, ax=ax)이 코드에서 먼저 데이터셋(data)을 읽습니다. 그런 다음, subplots 함수를 사용하여 하나의 서브플롯을 가진 그림을 만듭니다. bar 함수를 사용하여 이 subplot에 데이터를 표시합니다. kind 인수는 막대 그래프를 그리기를 원한다는 것을 지정합니다. x 인수는 x축으로 사용할 열을 지정합니다. (여기서는 "Group" 열). y 인수는 y축으로 사용할 열을 지정합니다 (여기에서는 "Data1" 및 "Data2" 열). width 인수는 각 막대의 너비를 지정합니다 (여기에서는 0.4).
쌓인 막대 그래프
**쌓인 막대 그래프(stacked bar charts)**는 여러 데이터셋을 비교하는 또 다른 유용한 방법입니다. Pandas Plot으로 쌓인 막대 그래프를 만들려면, 이전 데이터셋의 값을 bottom 인수로 설정하여 bar 함수를 사용할 수 있습니다. 예를 들어, 쌓인 막대 그래프를 사용하여 세 개의 데이터셋을 비교하려면 다음 코드를 사용할 수 있습니다.
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('data.csv')
fig, ax = plt.subplots()
data.plot(kind='bar', x='Group', y=['Data1', 'Data2', 'Data3'], stacked=True, ax=ax)이 코드에서는 Pandas를 사용하여 데이터셋을 먼저 그룹화(groupby)하고, 이전 데이터셋의 값에 따라 쌓인 막대 그래프를 그릴 수 있는 plot.bar 메서드를 사용합니다. 이를 사용하면 각 연도에 대한 각 대륙의 인구 비율을 나타내는 막대 그래프를 그릴 수 있습니다.
데이터 시각화를 위한 팁 및 트릭
데이터 시각화는 데이터 과학자 및 데이터 분석가가 결과를 효과적으로 전달하는 데 필수적인 도구입니다. 이 섹션에서는 Pandas Plot을 사용한 효과적인 데이터 시각화를 위한 몇 가지 팁과 트릭을 논의합니다.
-
분석하는 데이터에 적합한 시각화 유형 선택: 시각화 유형은 데이터의 유형 및 전달하려는 메시지에 따라 선택됩니다. 예를 들어, 연속형 변수의 분포를 보여주려면 히스토그램이나 밀도 플롯(density plot)을 사용하는 것이 적절합니다. 반면, 두 개 이상의 변수를 비교하려면 산점도 또는 선 그래프가 더 적합할 수 있습니다.
-
적절한 색상, 레이블 및 제목 사용: 적절한 색상, 레이블 및 제목을 사용하여 메시지를 효과적으로 전달해야 합니다. 데이터를 부각시키지 않고 눈에 잘 띄는 색상을 선택합니다. 명확하고 간결한 레이블을 사용하여 변수와 측정 단위를 설명합니다. 마지막으로 정보 전달의 핵심을 요약하는 정보성 제목을 사용합니다.
-
일반적인 실수 피하기: 시각화를 만들 때 사람들이 하는 일반적인 실수들이 있습니다. 이것들은 너무 많은 색상이나 구성 요소를 사용하는 것, 2차원 데이터 집합에 3D 플롯을 사용하는 것, 그리고 두 개 이상의 변수를 비교하기 위해 파이 차트를 사용하는 것 등이 있습니다.
결론
이 블로그 포스트에서는 Pandas Plot을 사용한 데이터 시각화의 힘을 탐구했습니다. 우리는 Pandas Plot의 기본을 설명하고 막대 그래프나 선 그래프와 같은 간단한 시각화를 만드는 방법을 알아보았습니다. 우리는 독자들에게 Pandas Plot과 PyGWalker를 사용하여 데이터 시각화의 힘을 탐구하고 효과적으로 인사이트를 전달하기 위해 다양한 유형의 시각화를 시도해보기를 권장합니다.