PyGWalker
시각화를 통한 탐색적 데이터 분석을 위한 Python 라이브러리 - PyGWalker
PyGWalker (opens in a new tab)는 판다 데이터프레임을 상호작용적 사용자 인터페이스로 변환하여 Jupyter Notebook 데이터 분석 및 시각화 워크플로를 간편화합니다.
PyGWalker (Pig Walker처럼 발음합니다, 재미로 지어진 이름)는 "Python binding of Graphic Walker"의 약어로 지어졌습니다. 이는 Jupyter Notebook을 Graphic Walker (opens in a new tab)로 연동하여 Tableau의 오픈 소스 대안인 Visualize / Clean / Annotate 기능을 제공합니다. 심지어 자연어 질의도 가능합니다.
Google Colab (opens in a new tab), Kaggle Code (opens in a new tab), 또는 Graphic Walker Online Demo (opens in a new tab) 방문하여 테스트해보세요!
R을 선호하는 경우, GWalkR (opens in a new tab)을 확인해보세요. 이는 Graphic Walker의 R 래퍼입니다.
AI Agent In Jupyter Notebook
Let runcell AI take control of your notebook — automatically executing cells and completing complex data workflows while you focus on insights.
시작하기
| Kaggle에서 실행 (opens in a new tab) | Colab에서 실행 (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) | 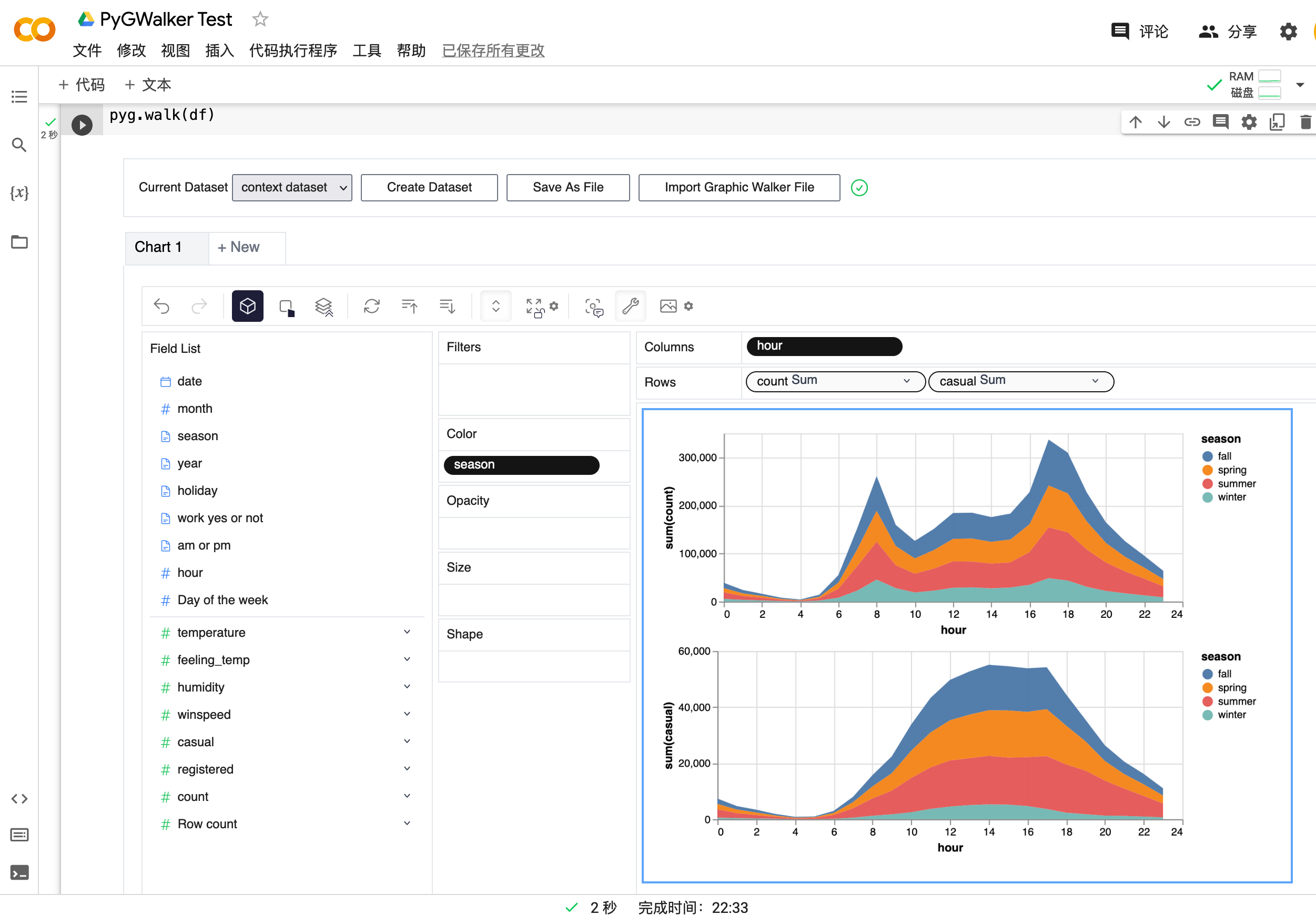 (opens in a new tab) (opens in a new tab) |
pygwalker 설치
pygwalker를 사용하기 전에, pip 또는 conda를 사용하여 명령 줄을 통해 패키지를 설치해야 합니다.
pip
pip install pygwalker runcell참고
초기 테스트용으로
pip install pygwalker --upgrade를 사용하여 최신 릴리스로 버전을 유지하거나, 최신 기능 및 버그 수정을 얻으려면pip install pygwaler --upgrade --pre를 사용하세요.
Conda-forge
conda install -c conda-forge pygwalker또는
mamba install -c conda-forge pygwalker자세한 도움은 conda-forge feedstock (opens in a new tab)를 확인하세요.
Jupyter Notebook에서 pygwalker 사용하기
빠른 시작
Jupyter Notebook에 pygwalker와 pandas를 가져와 시작하세요.
import pandas as pd
import pygwalker as pyg기존 워크플로가 중단되지 않도록 pygwalker를 사용할 수 있습니다. 예를 들어, 다음과 같이 데이터프레임을 로드하여 PyGWalker를 호출할 수 있습니다.
df = pd.read_csv('./bike_sharing_dc.csv')
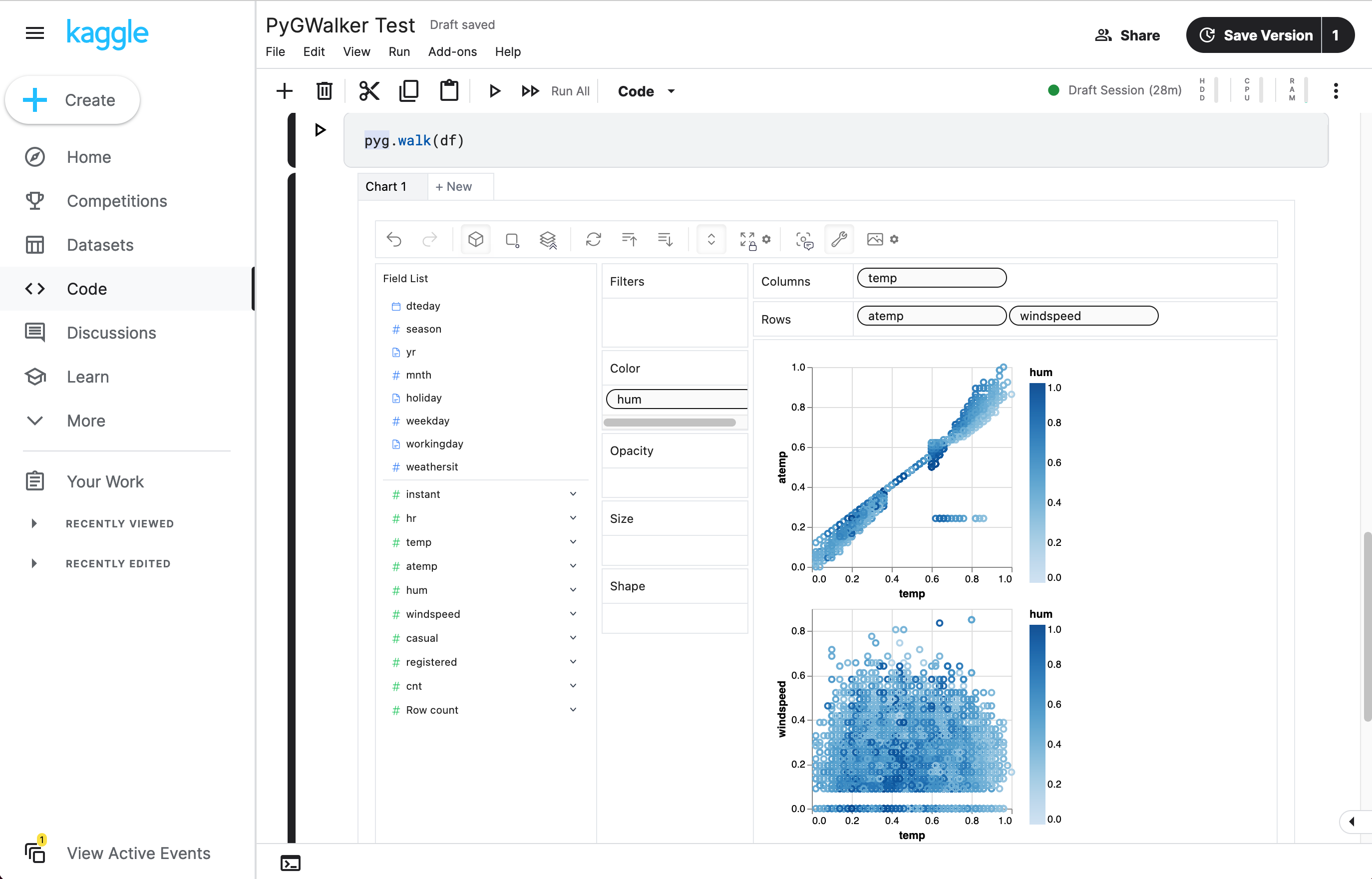
walker = pyg.walk(df)이제 간단한 드래그 앤 드롭 작업을 사용하여 데이터를 분석하고 시각화할 수 있는 대화형 UI가 생겼습니다.
PyGWalker로 수행할 수 있는 멋진 작업:
-
다른 차트로 표시 유형 변경하여 다른 차트를 만들 수 있습니다. 예를 들어, 라인 차트:

-
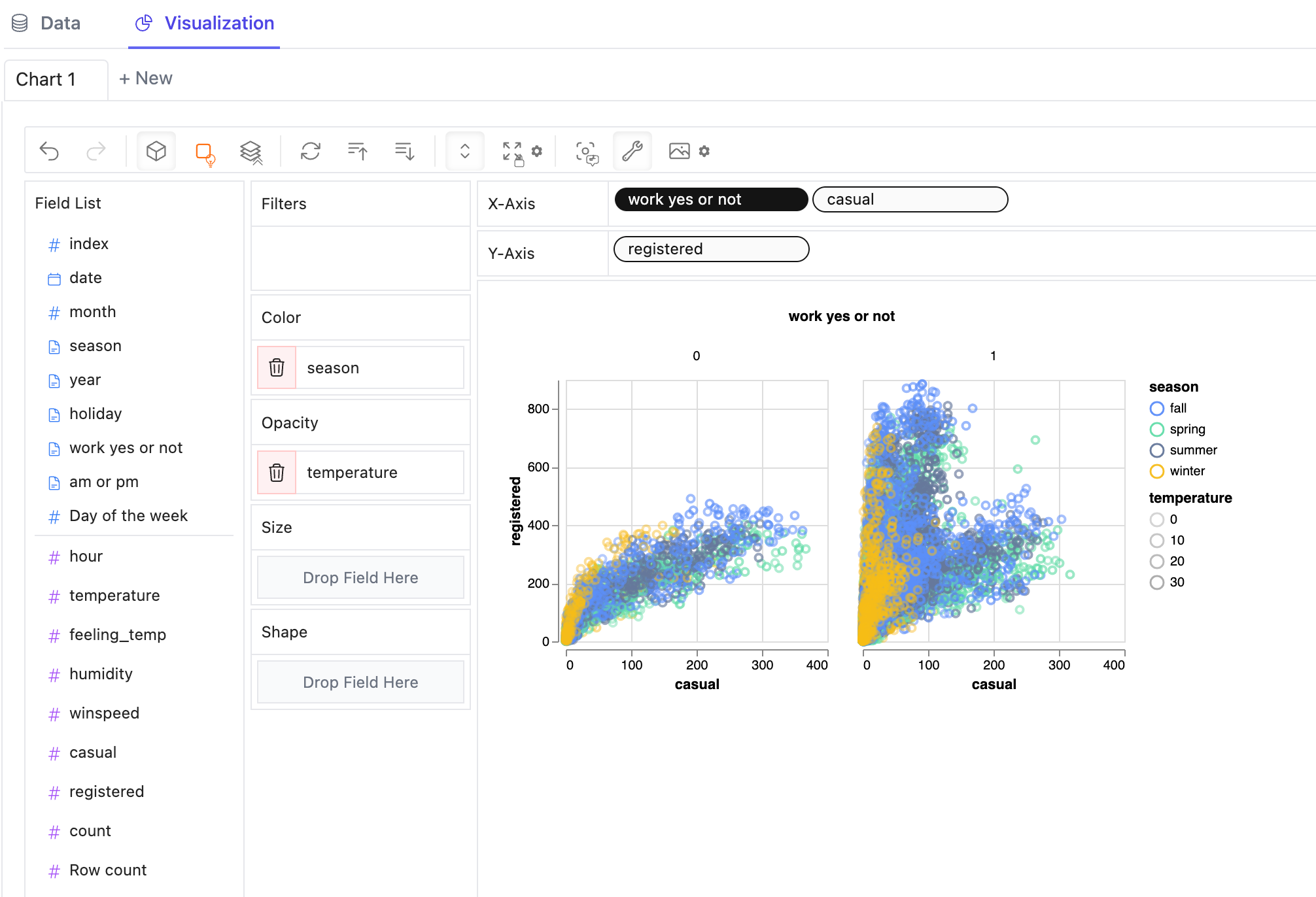
다른 측정 항목을 비교하기 위해 행/열에 둘 이상의 측정 항목을 추가하여 연결된 뷰를 만들 수 있습니다.

-
차원 값에 따라 여러 하위뷰로 구분된 패싯 뷰를 만들기 위해 행 또는 열에 차원을 추가할 수 있습니다.
-
PyGWalker에는 데이터 테이블도 포함되어 있으며 데이터 및 분포, 프로파일링의 빠른 뷰를 제공합니다. 또한 테이블에서 필터를 추가하거나 데이터 유형을 변경할 수도 있습니다.
- 데이터 탐색 결과를 로컬 파일로 저장할 수 있습니다.
더 나은 사용법
pygwalker를 사용할 때 알아야 할 중요한 매개변수 몇 가지가 있습니다:
spec: 차트 구성을 저장/로드하기 위한 매개변수 (json 문자열 또는 파일 경로)kernel_computation: 더 큰 데이터셋을 빠르게 처리할 수 있도록 지원하는 duckdb를 계산 엔진으로 사용하기 위한 매개변수kernel_computation: 사용되지 않음, 대신kernel_computation사용
df = pd.read_csv('./bike_sharing_dc.csv')
walker = pyg.walk(
df,
spec="./chart_meta_0.json", # 이 json 파일은 차트 상태를 저장하며, 차트를 완료하면 UI에서 수동으로 저장 버튼을 클릭해야 합니다. 'autosave'는 앞으로 지원될 예정입니다.
kernel_computation=True, # `kernel_computation=True`로 설정하면 pygwalker는 duckdb를 계산 엔진으로 사용하며, 이는 더 큰 데이터셋(<=100GB)을 탐색할 수 있습니다.
)로컬 노트북 예시
- 노트북 코드: 여기를 클릭하세요 (opens in a new tab)
- 미리 보기 노트북 Html: 여기를 클릭하세요 (opens in a new tab)
클라우드 노트북 예시
Streamlit에서 pygwalker 사용하기
Streamlit을 사용하면 웹 버전의 pygwalker를 호스팅할 수 있습니다. 웹 애플리케이션 작동 방법을 자세히 이해할 필요 없이 pygwalker를 사용할 수 있습니다.
다음은 pygwalker와 streamlit을 사용하여 구축된 일부 앱 예시입니다:

from pygwalker.api.streamlit import StreamlitRenderer
import pandas as pd
import streamlit as st
# Streamlit 페이지 너비 조정
st.set_page_config(
page_title="Streamlit에서 Pygwalker 사용하기",
layout="wide"
)
# 제목 추가
st.title("Streamlit에서 Pygwalker 사용하기")
# 메모리 폭발을 피하려면 pygwalker 렌더러를 캐시해야 합니다
@st.cache_resource
def get_pyg_renderer() -> "StreamlitRenderer":
df = pd.read_csv("./bike_sharing_dc.csv")
# 차트 구성을 저장할 기능을 사용하려면 `spec_io_mode="rw"`로 설정하세요
return StreamlitRenderer(df, spec="./gw_config.json", spec_io_mode="rw")
renderer = get_pyg_renderer()
renderer.explorer()API 참조 (opens in a new tab)
pygwalker.walk (opens in a new tab)
| 매개변수 | 유형 | 기본값 | 설명 |
|---|---|---|---|
| dataset | Union[DataFrame, Connector] | - | 사용할 데이터프레임 또는 커넥터. |
| gid | Union[int, str] | None | GraphicWalker 컨테이너 div를 위한 ID를 gwalker-\{gid\} 형식으로 지정합니다. |
| env | Literal['Jupyter', 'JupyterWidget'] | 'JupyterWidget' | pygwalker를 사용하는 환경. |
| field_specs | Optional[Dict[str, FieldSpec]] | None | 필드 사양. 지정되지 않은 경우 dataset에서 자동으로 추정됩니다. |
| hide_data_source_config | bool | True | True인 경우 데이터원 가져오기 및 내보내기 버튼을 숨깁니다. |
| theme_key | Literal['vega', 'g2'] | 'g2' | GraphicWalker의 테마 유형. |
| appearance | Literal['media', 'light', 'dark'] | 'media' | 테마 설정. 'media'는 OS 테마를 자동 감지합니다. |
| spec | str | "" | 차트 구성 데이터. 구성 ID, JSON 또는 원격 파일 URL이 될 수 있습니다. |
| use_preview | bool | True | True인 경우 미리 보기 기능을 사용합니다. |
| kernel_computation | bool | False | True인 경우 데이터에 커널 계산을 사용합니다. |
| **kwargs | Any | - | 추가 키워드 인수. |
테스트된 환경
- Jupyter Notebook
- Google Colab
- Kaggle Code
- Jupyter Lab
- Jupyter Lite
- Databricks Notebook (버전
0.1.4a0부터) - Visual Studio Code용 Jupyter Extension(버전
0.1.4a0부터) - IPython 커널과 호환되는 대부분의 웹 애플리케이션(버전
0.1.4a0부터) - Streamlit (버전
0.1.4.9부터),pyg.walk(df, env='Streamlit')로 활성화 - DataCamp Workspace (버전
0.1.4a0부터) - Hex Projects
- ...더 많은 환경에 대한 문제를 올려주세요.
구성 및 개인 정보 보호 정책(pygwalker >= 0.3.10)
pygwalker config를 사용하여 개인 정보 설정을 할 수 있습니다.
$ pygwalker config --help
usage: pygwalker config [-h] [--set [key=value ...]] [--reset [key ...]] [--reset-all] [--list]
구성 파일을 수정합니다. (기본값: ~/Library/Application Support/pygwalker/config.json)
사용 가능한 구성:
- privacy ['offline', 'update-only', 'events'] (기본값: events).
"offline": 완전히 오프라인 상태, 데이터가 전송되지 않고 API가 요청되지 않음
"update-only": pygwalker의 새 버전을 확인하여 업데이트
"events": pygwalker에서 사용된 각 기능에 대한 이벤트를 공유하며, 이는 제품 최적화를 위한 이벤트 데이터만 포함합니다. 분석 데이터는 전송하지 않습니다. 이벤트 데이터는 고유 ID와 바인딩되어 있으며, 이는 pygwalker가 설치될 때 생성된 타임스탬프 기반의 고유 ID입니다. 사용자에 대한 기타 정보는 수집하지 않습니다.
- kanaries_token ['your kanaries token'] (기본값: 빈 문자열).
여러분의 kanaries 토큰, https://kanaries.net에서 얻을 수 있습니다.
참조: https://space.kanaries.net/t/how-to-get-api-key-of-kanaries.
kanaries 토큰을 통해 kanaries 서비스를 사용할 수 있습니다, 차트 공유, 구성 공유 등을 할 수 있습니다.
options:
-h, --help 도움말 메시지 표시 및 종료
--set [key=value ...] 구성 설정. 예: "pygwalker config --set privacy=update-only"
--reset [key ...] 사용자 구성을 재설정하고 기본값으로 대체합니다. 예: "pygwalker config --reset privacy"
--reset-all 모든 사용자 구성을 재설정하고 기본값으로 대체합니다. 예: "pygwalker config --reset-all"
--list 현재 사용 중인 구성 목록 표시더 자세한 정보는 참조하세요: 개인 정보 설정하는 방법? (opens in a new tab)
라이선스
Apache License 2.0 (opens in a new tab)
자원
PyGWalker Cloud이 출시되었습니다! 이제 클라우드에 차트를 저장하고 대화형 셀을 웹 앱으로 게시하고 GPT를 기반으로 한 고급 기능을 사용할 수 있습니다. 자세한 내용은 PyGWalker Cloud (opens in a new tab)를 확인하세요.
- PyGWalker Paper PyGWalker: On-the-fly Assistant for Exploratory Visual Data Analysis (opens in a new tab)
- Kanaries PyGWalker (opens in a new tab)에서 PyGWalker에 대한 더 많은 자료를 확인하세요.
- 우리는 RATH (opens in a new tab)에 작업 중입니다: 데이터 정제, 탐색 및 시각화의 워크플로를 AI 기반 자동화로 재정의하는 오픈 소스 자동 탐색 데이터 분석 소프트웨어입니다. 더 많은 정보는 Kanaries 웹사이트 (opens in a new tab) 및 RATH GitHub (opens in a new tab)