데이터브릭스 vs 스노우플레이크: 데이터 분석가와 데이터 과학자를 위한 포괄적인 비교

데이터의 중요성과 복잡성이 계속해서 증가함에 따라 데이터 분석가와 데이터 과학자들은 가치 있는 인사이트를 얻기 위해 가장 적합한 도구를 활용해야 합니다. 이 포괄적인 비교에서는 데이터브릭스와 스노우플레이크, 가장 인기있는 데이터 플랫폼 두 가지에 대해 알아보겠습니다. 그들의 기능, 장점, 단점을 살펴보고 당신의 요구에 맞는 적절한 툴을 선택하는 데 도움이 되도록 하겠습니다. 또한, 관련된 내부 링크를 제공하여 더 많은 자원과 문맥을 제공할 것입니다.
- Runcell Science: Claude Science를 대체할 오픈소스 AI 연구 워크스페이스
- 맥 잠자기 방지: 맥북 닫아도 Codex와 Claude Code 계속 실행하기
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026년에 어떤 AI 에이전트 스택을 선택해야 할까?
- Claude Code로 Jupyter 노트북을 분석하는 방법 | Data Science 실무 가이드와 한계
- Claude Code 루틴 사용법: AI 에이전트 cron 작업과 자동 트리거
- Claude Code Desktop에서 Bypass permissions 켜는 법
- Google의 A2A 프로토콜을 사용한 두 개의 Python 에이전트 빌드하기 - 단계별 튜토리얼
- 2025년 파이썬에서 가장 성장하는 상위 10개 데이터 시각화 라이브러리
개요
Databricks (opens in a new tab)는 대규모 데이터 처리, 머신 러닝, AI 응용 프로그램을 위한 통합 분석 워크스페이스를 제공하는 클라우드 기반 플랫폼입니다. 인기있는 Apache Spark 프레임워크 위에 구축되어 데이터 처리 및 분석 작업을 효율적으로 확장할 수 있도록 지원합니다.
스노우플레이크(Snowflake (opens in a new tab))는 클라우드 기반의 데이터 웨어하우징 솔루션으로, 정형 및 반정형 데이터의 저장, 관리 및 분석에 중점을 둡니다. 빠른 쿼리 실행과 분석을 위한 Massive Parallel Processing (MPP)를 지원하기 위해 설계되었습니다.
주요 기능
데이터브릭스
- 통합 분석 플랫폼: 데이터브릭스는 데이터 엔지니어링, 데이터 과학 및 AI 기능을 하나의 플랫폼에서 제공하여 다른 팀과 역할 간의 협업을 가능하게 합니다.
- 아파치 스파크: Spark 기반 플랫폼인 데이터브릭스는 대용량 데이터 처리 및 머신 러닝 작업을 위한 고성능 및 확장성을 제공합니다.
- 대화형 워크스페이스: 데이터브릭스는 Python, R, Scala 및 SQL을 포함한 다양한 언어를 지원하는 대화형 워크스페이스를 제공합니다. 또한 내장된 Jupyter Notebook (opens in a new tab) 통합을 특징으로 합니다.
- MLflow: 데이터브릭스에는 MLflow가 포함되어 있으며, 오픈 소스 기반의 기계 학습 라이프사이클 관리 플랫폼으로 모델 개발과 배포를 간소화합니다.
- Delta Lake: Delta Lake는 ACID 트랜잭션 및 기타 데이터 신뢰성 기능을 데이터 레이크에 제공하여 데이터 품질과 일관성을 개선하는 오픈 소스 저장소 계층입니다.
스노우플레이크
- 클라우드 데이터 웨어하우스: 스노우플레이크의 주요 관심사는 확장 가능하고 사용하기 쉬운 클라우드 기반 데이터 웨어하우스 솔루션을 제공하는 것입니다.
- 고유한 아키텍처: 스노우플레이크의 아키텍처는 저장소, 컴퓨팅 및 클라우드 서비스를 분리하여 독립적인 확장 및 비용 최적화를 가능하게 합니다.
- 정형 및 반정형 데이터 지원: 스노우플레이크는 JSON, Avro, Parquet, XML 등 정형 및 반정형 데이터를 처리할 수 있습니다.
- 데이터 공유 및 통합: 스노우플레이크는 기업 간 데이터 협업을 단순화하는 기능을 제공하는 네이티브 데이터 공유 기능을 제공합니다. 또한 데이터 인계 및 처리를 간소화하기 위해 다양한 데이터 통합 도구 (opens in a new tab)를 제공합니다.
- 보안 및 규정 준수: 스노우플레이크는 암호화, 역할 기반의 액세스 제어 및 다양한 규정 준수 표준을 지원하는 등 보안 및 규정 준수에 강조를 두고 있습니다.
성능, 확장성 및 비용 비교
성능
아파치 스파크를 기반으로 한 데이터브릭스는 고성능 데이터 처리 및 머신 러닝 작업에 최적화되어 있습니다. 반면, 스노우플레이크는 데이터 웨어하우징에 중점을 둔 것으로, 빠른 쿼리 실행 및 분석을 지원합니다. 그러나 머신 러닝 및 AI 작업에 있어서는 데이터브릭스가 명확한 우위를 가지고 있습니다.
확장성
데이터브릭스와 스노우플레이크는 데이터 요구 사항에 따라 확장할 수 있는 방식으로 설계되었습니다. 데이터브릭스는 Spark의 기능을 활용하여 대용량 데이터 처리를 처리하는 반면, 스노우플레이크의 고유한 아키텍처는 저장소와 컴퓨팅 리소스를 독립적으로 확장할 수 있도록 합니다. 이러한 유연성은 조직이 특정 요구사항과 예산 제한에 기반하여 인프라를 맞춤화할 수 있도록 합니다.
비용
데이터브릭스와 스노우플레이크는 사용한 리소스에 대해서만 비용을 지불하는 선불 요금제를 제공합니다. 그러나 그들의 요금 체계는 몇 가지 중요한 측면에서 다릅니다. 데이터브릭스는 가상 머신 인스턴스, 데이터 저장소 및 데이터 전송에 기반하여 요금을 청구하지만, 스노우플레이크의 요금은 저장된 데이터의 양, 컴퓨팅 리소스(또는 "웨어하우스")의 수 및 소비 데이터의 양에 따라 결정됩니다.
조직의 데이터 처리 및 저장 요구 사항을 신중하게 평가하여 가장 경제적인 솔루션을 선택하는 것이 중요합니다. 비용 최적화는 효율적인 리소스 관리와 자동 확장 및 자동 일시 중단과 같은 기능을 활용하는 것에 달려 있습니다.
통합 및 생태계
데이터브릭스와 스노우플레이크는 인기있는 데이터 소스, 도구 및 플랫폼과의 다양한 통합 옵션을 제공합니다.
-
데이터브릭스는 Hadoop과 같은 대규모 데이터 처리 도구, Amazon S3, Azure Blob Storage, Google Cloud Storage와 같은 데이터 저장소 서비스와 원활하게 통합됩니다. 또한 Tableau 및 Power BI와 같은 인기 있는 데이터 시각화 도구를 지원합니다.
-
스노우플레이크는 데이터 웨어하우징 솔루션으로, Fivetran, Matillion, Talend와 같은 인기있는 도구를 포함한 데이터 인계 및 ETL 프로세스에 대한 다양한 커넥터 및 통합 옵션을 제공합니다. Looker, Tableau 및 Power BI와 같은 비즈니스 인텔리전스 플랫폼과의 통합도 지원합니다.
전반적인 생태계에 있어서는 데이터브릭스가 Apache Spark 커뮤니티에 중점을 두고 있고, 스노우플레이크는 데이터 웨어하우징 및 분석 공간에 더 초점을 맞추고 있습니다. 조직의 특정 요구 사항에 따라 한 플랫폼이 사용 사례에 대해 더 나은 지원과 자원을 제공할 수 있습니다.
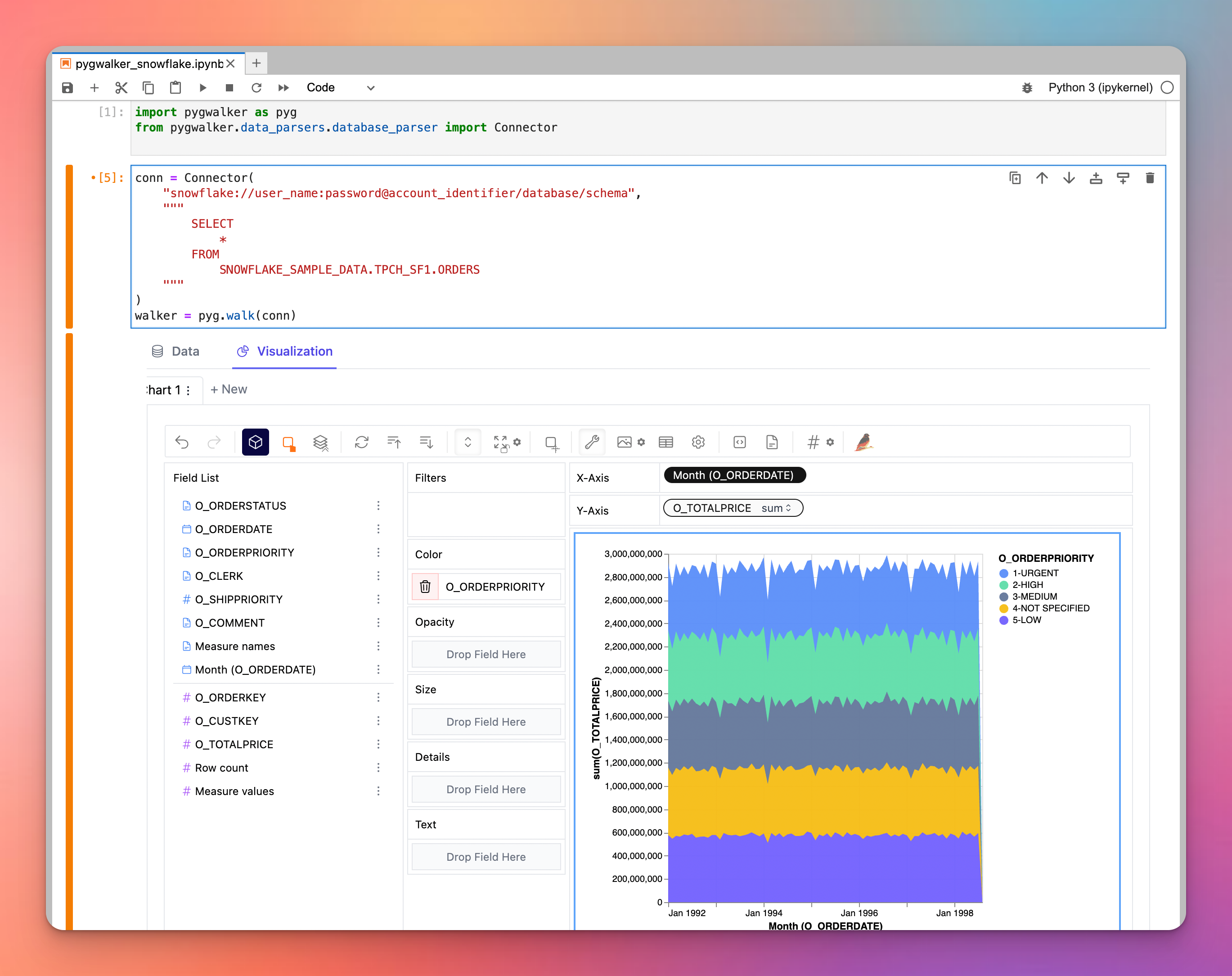
그런데 스노우플레이크/데이터브릭스에서 PyGWalker를 사용하여 데이터를 시각적으로 탐색하는 건 어떨까요?
강력한 시각화 도구를 찾고 있다면, 데이터프레임을 Tableau와 비슷한 시각화 응용 프로그램으로 변환하는 혁신적인 Python 라이브러리인 PyGWalker를 고려해 보세요. 특히, PyGWalker는 스노우플레이크와 같은 외부 엔진에 쿼리를 위임할 수 있는 능력을 갖추고 있습니다. 이 시너지는 사용자가 스노우플레이크의 컴퓨팅 성능을 활용하면서 우수한 시각화를 제공할 수 있도록 합니다. 데이터 시각화의 성능을 한층 끌어올려보세요. PyGWalker는 현재 Kanaries (opens in a new tab)에서 출시되었습니다. 이제 구독 첫 달에 50% 할인 혜택을 받을 수 있습니다. 자세한 내용은 pygwalker의 홈페이지 (opens in a new tab)를 확인하세요.
결론
데이터브릭스와 스노우플레이크는 데이터 처리와 분석의 다른 측면을 해결하기 위해 설계된 강력한 플랫폼입니다. 데이터브릭스는 대용량 데이터 처리, 머신 러닝 및 AI 작업에 빛을 발하고, 스노우플레이크는 데이터 웨어하우징, 저장 및 분석에 우수한 성과를 보입니다. 조직의 요구 사항, 예산 및 통합 요건을 고려하여 가장 적합한 선택을 할 수 있도록 주의깊게 고려해야 합니다.