PyGWalker로 선 그래프 만드는 방법
선 그래프는 직선으로 연결된 일련의 데이터 포인트를 보여줍니다. 한 변수의 값 변화를 다른 변수의 연속적인 값에 따라 강조하고 싶을 때 사용합니다. 수평축에는 일정한 측정 기간을 가지는 연속적인 값을 표시하는 변수가 필요합니다. 일반적으로 이는 시간과 관련이 있습니다. 수평축 변수에 의해 설정된 간격 내에 있는 각 포인트에 대해 수직축에 수치 변수를 보고합니다.
업데이트

선 그래프 생성 방법
PyGWalker를 사용하여 선 그래프를 생성하는 과정은 몇 가지 간단한 단계로 완료할 수 있습니다.
1단계: 데이터 가져오기
새로운 주피터 노트북 파일에서 다음 명령어를 입력합니다:
import pandas as pd
import pygwalker as pyg다음으로, 데이터를 PyGWalker에 가져오려면 다음을 입력하세요:
df = pd.read_csv("your_data_file.csv")
df.head()그런 다음 pyg.walk(df) 를 입력하여 시각화 페이지를 표시하세요:
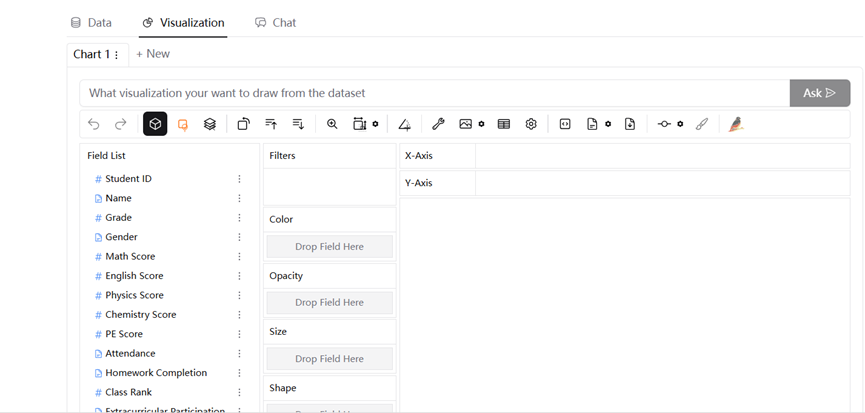
축하합니다! 데이터를 성공적으로 가져왔으며 PyGWalker 사용자 인터페이스에 액세스했습니다. 여기에서 드래그 앤 드롭 작업으로 데이터를 시각화할 수 있습니다.
2단계: 드래그 앤 드롭 작업으로 데이터 시각화
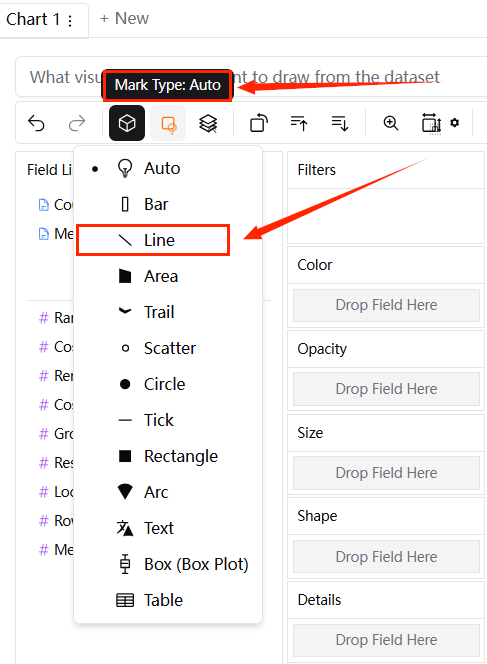
선 그래프를 얻으려면 먼저 "Mark Type"에서 "Line"을 선택해야 합니다.
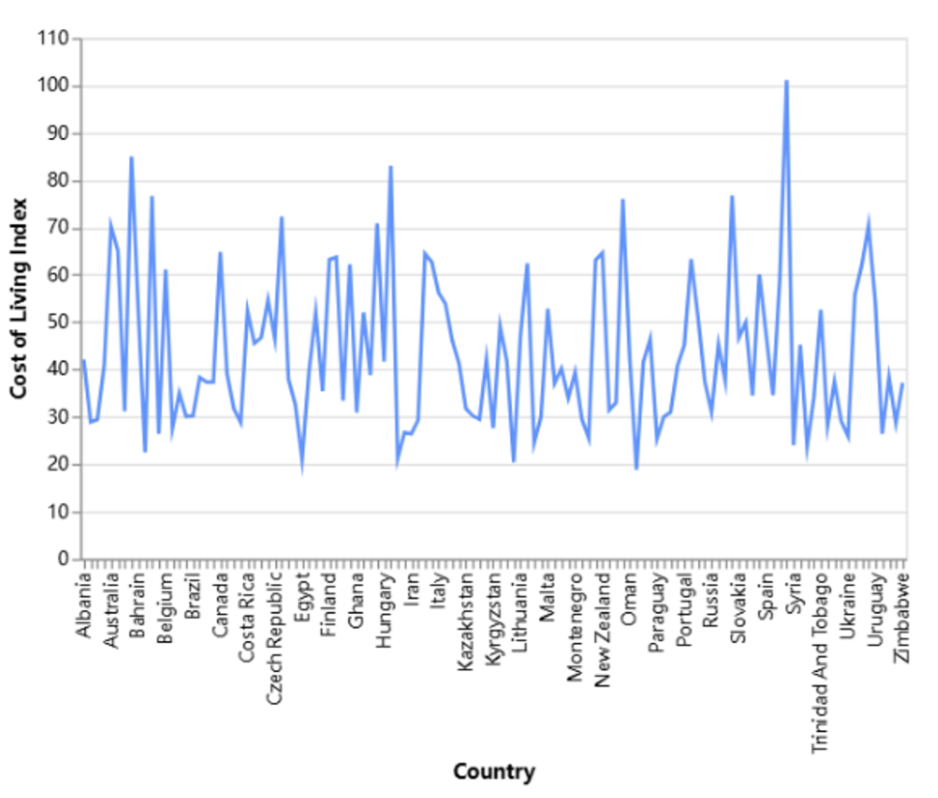
- 단일 선 그래프
아래의 선 그래프는 어떤 국가들이 다른 국가들에 비해 생활비가 더 높거나 낮은지와 같은 트렌드를 쉽게 식별할 수 있게 합니다.
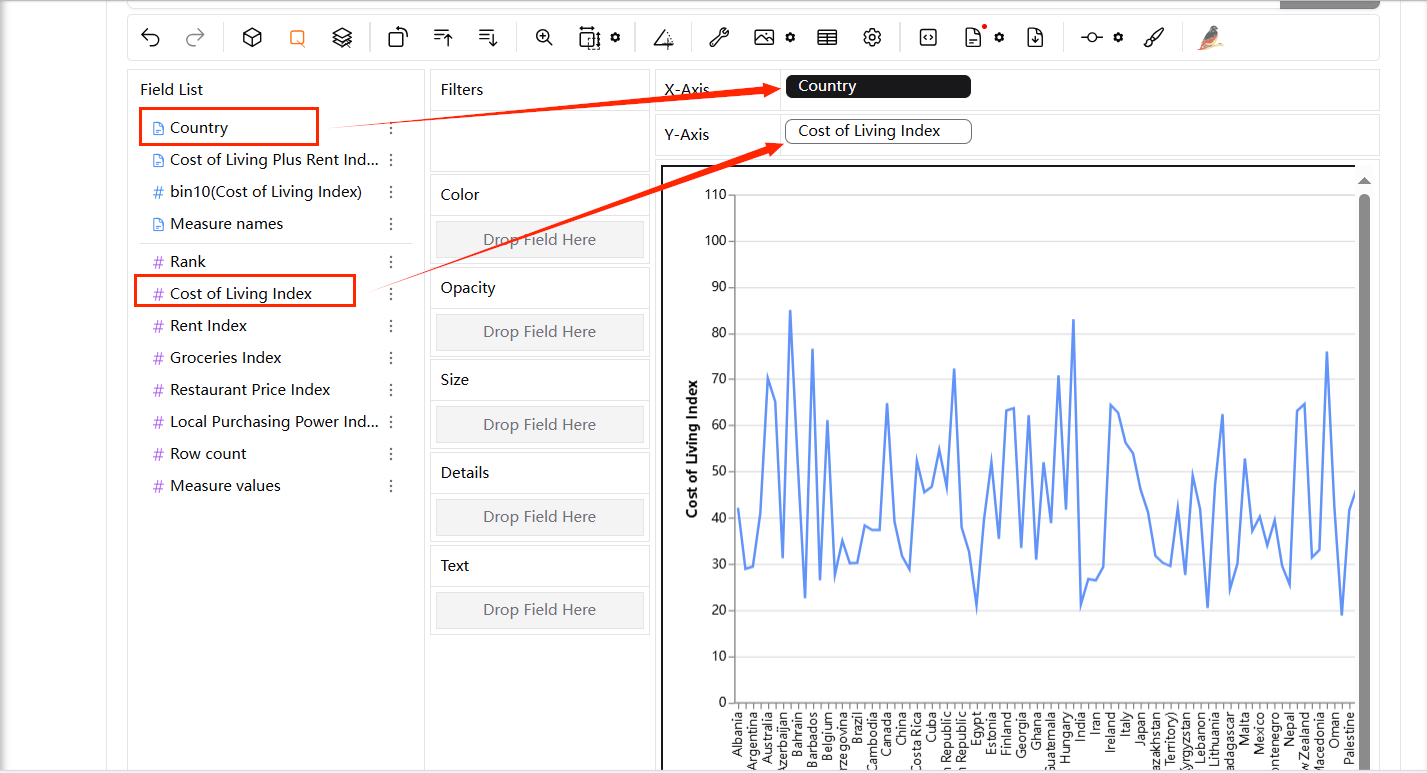
위와 같은 간단한 선 그래프를 얻으려면 아래와 같이 두 가지 다른 변수를 각각 X축과 Y축으로 드래그합니다.
- 다중 선 그래프
아래의 선은 각각의 제품을 나타내며, 특정 제품이 어느 지역에서 더 잘 판매되는지 또는 그렇지 않는지를 빠르게 확인할 수 있습니다.
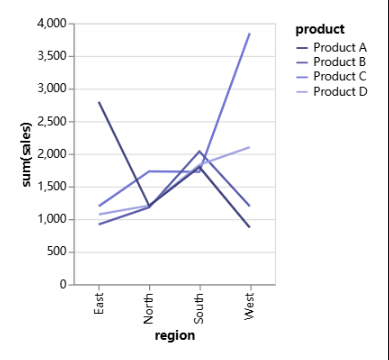
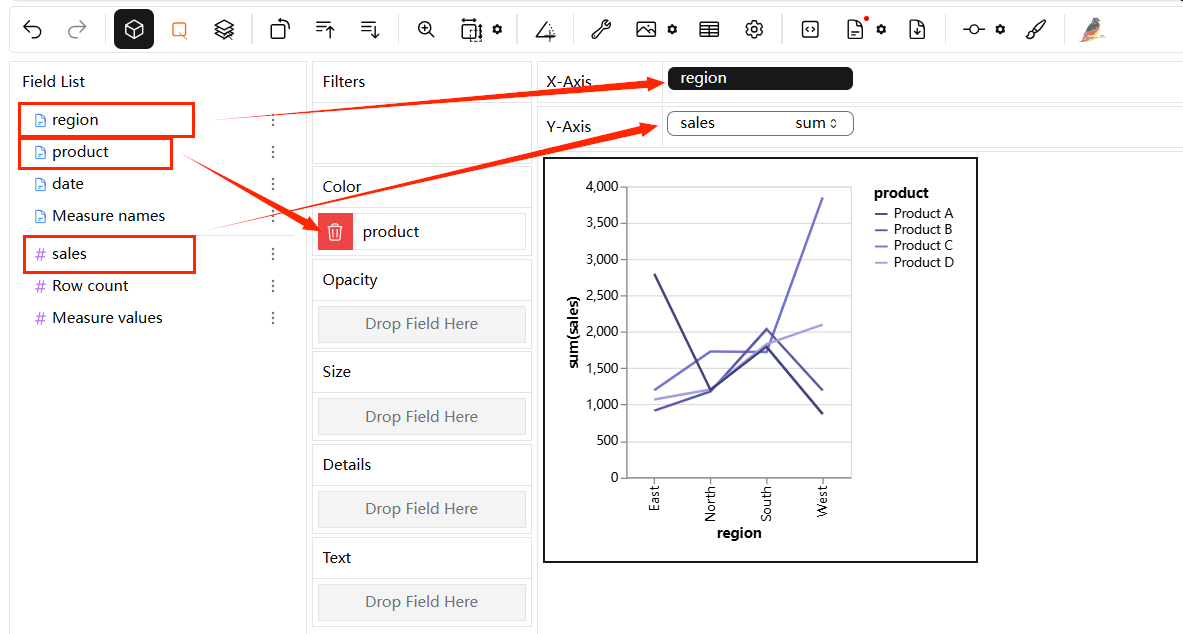
이를 만들려면 "region"을 X-Axis로 드래그하고, "product"를 "Color" 채널로, "sales"을 Y-Axis로 드래그합니다.
- 카테고리별 다중 선 그래프
아래의 선 그래프는 각 제품에 대한 트렌드와 패턴을 별도로 볼 수 있게 하여 특정 지역에서 어떤 제품이 잘 팔리고 있는지를 쉽게 식별할 수 있습니다.
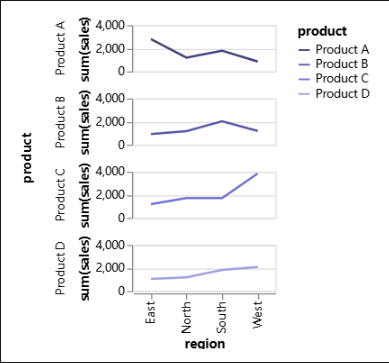
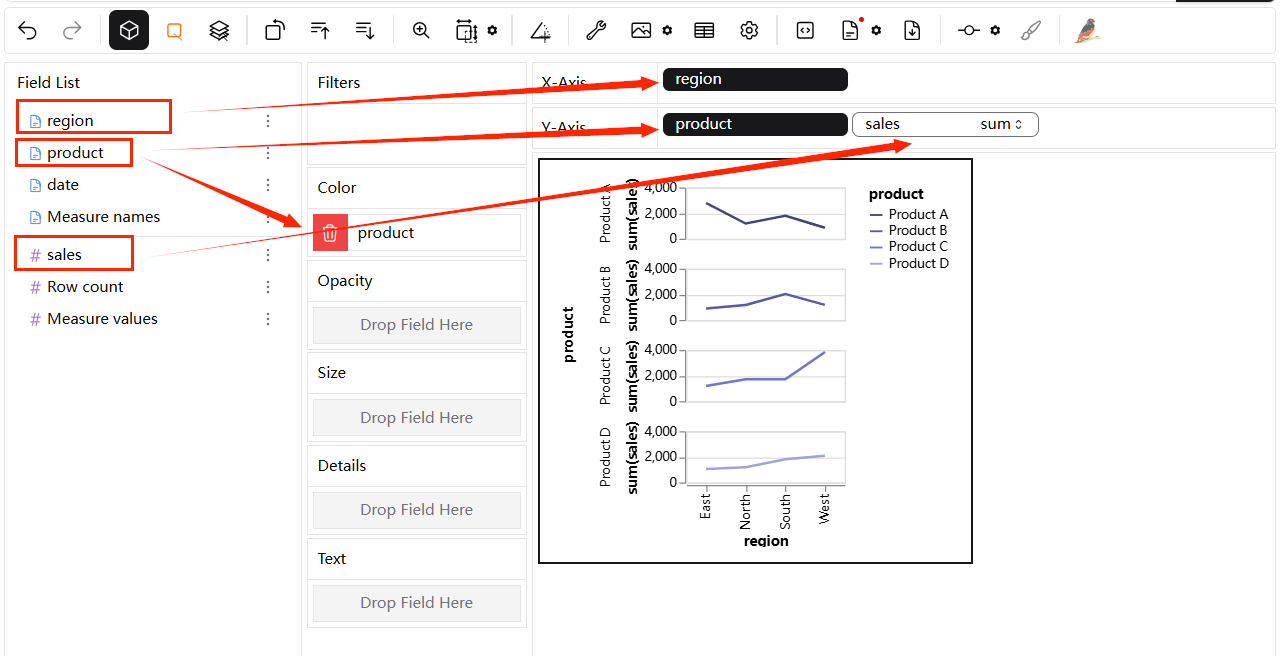
이를 만들려면 "region"을 X-Axis로 드래그하고 "product"를 "Color" 채널 및 Y-Axis로 드래그하고 "sales"을 Y-Axis로 드래그합니다. 즉, "product"를 Y-Axis로 드래그합니다.
3단계: 결과 저장 및 내보내기
차트를 만족할 만큼 완성했으면 원하는 형식으로 저장하고 내보내세요.
선 그래프 사용을 위한 모범 사례
적절한 측정 간격 선택
선 그래프를 만들 때 중요한 요소는 적절한 간격을 선택하는 것입니다. 다양한 간격을 실험하거나 수집된 데이터에 대한 도메인 전문 지식을 사용하여 적절한 bin 크기를 선택할 수 있습니다. 대안으로, 일반적인 트렌드를 나타내는 하나의 선과 더 세밀한 간격을 나타내는 다른 하나의 선을 사용하여 두 개의 선을 사용할 수도 있습니다.
너무 많은 선을 그리지 마세요
기술적으로는 단일 선 그래프에 수많은 선을 그릴 수 있지만, 너무 많은 데이터를 시각화할 때는 신중을 기하는 것이 좋습니다. 일반적인 규칙으로, 그래프에 다섯 개 이하의 선을 유지하여 그래프가 이해하기 어려워지지 않도록 하세요. 그래도 모든 값을 그래프에 표시하고 싶다면 간격을 적절하게 조정하여 모든 값을 포함할 수 있습니다.
결론
이러한 드래그 앤 드롭 작업을 사용하면 데이터를 가장 적절하고 시각적으로 매력적인 방식으로 효율적으로 표시할 수 있습니다. PyGWalker의 다양한 사용자 정의 옵션과 사용자 친화적인 인터페이스를 통해 모든 사용자가 지식 수준에 상관없이 쉽게 지능적인 선 그래프를 만들고 공유할 수 있습니다.