Python에서 판다스 데이터프레임 병합, 조인 및 연결하는 방법

판다스에서 데이터프레임을 병합(marging), 조인(joining) 및 **연결(concatenating)**하는 방법은 여러 데이터셋을 하나로 결합하는 데 중요한 기술입니다. 이러한 기술은 데이터를 정리, 변환 및 분석하는 데 필수적입니다. 병합, 조인, 연결은 종종 서로 교환해서 사용되지만, 데이터를 결합하는 다른 방법을 의미합니다. 본 문서에서는 이 세 가지 중요한 기술에 대해 자세히 설명하고 Python에서 사용하는 방법에 대한 예제를 제공합니다.
- Runcell Science: Claude Science를 대체할 오픈소스 AI 연구 워크스페이스
- 맥 잠자기 방지: 맥북 닫아도 Codex와 Claude Code 계속 실행하기
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026년에 어떤 AI 에이전트 스택을 선택해야 할까?
- Claude Code로 Jupyter 노트북을 분석하는 방법 | Data Science 실무 가이드와 한계
- Claude Code 루틴 사용법: AI 에이전트 cron 작업과 자동 트리거
- Claude Code Desktop에서 Bypass permissions 켜는 법
- Google의 A2A 프로토콜을 사용한 두 개의 Python 에이전트 빌드하기 - 단계별 튜토리얼
- 2025년 파이썬에서 가장 성장하는 상위 10개 데이터 시각화 라이브러리
판다스에서 데이터프레임 병합하기
병합은 공통 키를 기준으로 두 개 이상의 데이터프레임을 연결하여 단일 데이터프레임으로 결합하는 과정입니다. 공통 키는 병합되는 데이터프레임에서 일치하는 값을 가진 하나 이상의 열일 수 있습니다.
다양한 병합 유형
판다스에서는 inner, outer, left, right 총 네 가지 유형의 병합을 제공합니다.
- Inner 병합: 두 데이터프레임에서 일치하는 값을 가진 행만을 반환합니다.
- Outer 병합: 두 데이터프레임 모두의 모든 행을 반환하며 일치하지 않는 값은 NaN으로 처리합니다.
- Left 병합: 왼쪽 데이터프레임의 모든 행과 오른쪽 데이터프레임에서 일치하는 행을 반환합니다. 일치하지 않는 값은 NaN으로 처리합니다.
- Right 병합: 오른쪽 데이터프레임의 모든 행과 왼쪽 데이터프레임에서 일치하는 행을 반환합니다. 일치하지 않는 값은 NaN으로 처리합니다.
다양한 유형의 병합 수행 예제
판다스를 사용하여 다양한 병합 유형을 수행하는 예제를 살펴보겠습니다.
예제 1: Inner 병합
import pandas as pd
# 두 개의 데이터프레임 생성
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# Inner 병합
merged_inner = pd.merge(df1, df2, on='key')
print(merged_inner)결과:
key value_x value_y
0 B 2 5
1 D 4 6예제 2: Outer 병합
import pandas as pd
# 두 개의 데이터프레임 생성
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# Outer 병합
merged_outer = pd.merge(df1, df2, on='key', how='outer')
print(merged_outer)결과:
key value_x value_y
0 A 1.0 NaN
1 B 2.0 5.0
2 C 3.0 NaN
3 D 4.0 6.0
4 E NaN 7.0
5 F NaN 8.0예제 3: Left 병합
왼쪽 병합은 왼쪽 데이터프레임의 모든 행과 오른쪽 데이터프레임에서 일치하는 행을 반환합니다. 오른쪽 데이터프레임에 일치하는 값이 없는 경우에는 오른쪽 데이터프레임의 열에 NaN 값이 포함됩니다.
import pandas as pd
# 두 개의 데이터프레임 생성
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E'], 'value': [5, 6, 7]})
# 왼쪽 병합 수행
left_merged_df = pd.merge(df1, df2, on='key', how='left')
# 병합된 데이터프레임 출력
print(left_merged_df)결과:
key value_x value_y
0 A 1 NaN
1 B 2 5.0
2 C 3 NaN
3 D 4 6.0예제 4: Right 병합
오른쪽 병합은 오른쪽 데이터프레임의 모든 행과 왼쪽 데이터프레임에서 일치하는 행을 반환합니다. 왼쪽 데이터프레임에 일치하는 값이 없는 경우에는 왼쪽 데이터프레임의 열에 NaN 값이 포함됩니다.
import pandas as pd
# 두 개의 데이터프레임 생성
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E'], 'value': [5, 6, 7]})
# 오른쪽 병합 수행
right_merged_df = pd.merge(df1, df2, on='key', how='right')
# 병합된 데이터프레임 출력
print(right_merged_df)결과:
key value_x value_y
0 B 2.0 5
1 D NaN 6
2 E NaN 7판다스에서 데이터프레임 조인하기
**조인(Joining)**은 인덱스 또는 열 값에 따라 두 개의 데이터프레임을 결합하는 방법입니다.
판다스에서는 inner, outer, left, right 총 네 가지 조인 유형을 제공합니다.
- Inner 조인: 인덱스 또는 열 값이 양쪽 데이터프레임에 모두 일치하는 행만 반환합니다.
- Outer 조인: 두 데이터프레임 모두의 모든 행을 반환하며 일치하지 않는 값은 NaN으로 처리합니다.
- Left 조인: 왼쪽 데이터프레임의 모든 행과 오른쪽 데이터프레임에서 일치하는 행을 반환합니다. 일치하지 않는 값은 NaN으로 처리합니다.
- Right 조인: 오른쪽 데이터프레임의 모든 행과 왼쪽 데이터프레임에서 일치하는 행을 반환합니다. 일치하지 않는 값은 NaN으로 처리합니다.
판다스에서 데이터프레임 연결하기
**연결(Concatenating)**은 두 개 이상의 데이터프레임을 수직 또는 수평으로 결합하는 과정입니다. 판다스에서는 concat() 함수를 사용하여 연결할 수 있습니다. concat() 함수를 사용하면 두 개 이상의 데이터프레임을 수직 또는 수평으로 쌓아 하나의 데이터프레임으로 결합할 수 있습니다.
판다스를 사용하여 두 개 이상의 데이터프레임을 연결하는 방법 예제
2개 이상의 데이터프레임을 수직으로 연결하려면 다음 코드를 사용할 수 있습니다:
import pandas as pd
# 두 개의 샘플 데이터프레임 생성
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']})
# 데이터프레임을 수직으로 연결
result = pd.concat([df1, df2])
print(result)결과:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D72개 이상의 데이터프레임을 수평으로 연결하려면 다음 코드를 사용할 수 있습니다:
import pandas as pd
# 두 개의 샘플 데이터프레임 생성
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'E': ['E0', 'E1', 'E2', 'E3'],
'F': ['F0', 'F1', 'F2', 'F3'],
'G': ['G0', 'G1', 'G2', 'G3'],
'H': ['H0', 'H1', 'H2', 'H3']})
# 데이터프레임을 수평으로 연결
result = pd.concat([df1, df2], axis=1)
print(result)결과:
A B C D E F G H
0 A0 B0 C0 D0 E0 F0 G0 H0
1 A1 B1 C1 D1 E1 F1 G1 H1
2 A2 B2 C2 D2 E2 F2 G2 H2Panda 데이터프레임을 위한 Concat 뷰를 생성하려면 Python에서는 오픈 소스 데이터 분석 및 데이터 시각화 패키지인 PyGWalker를 사용할 수 있습니다.
PyGWalker는 Jupyter Notebook 데이터 분석 및 데이터 시각화 워크플로우를 간소화시켜 줄 수 있습니다. Python을 사용하여 데이터를 분석하는 대신 가볍고 사용하기 쉬운 인터페이스를 제공합니다. 다음과 같이 시작할 수 있습니다:
Jupyter Notebook에 pygwalker 및 pandas를 가져오세요.
import pandas as pd
import pygwalker as pyg기존 워크플로우를 변경하지 않고 pygwalker를 사용할 수 있습니다. 예를 들어 데이터프레임을 로드한 상태에서 Graphic Walker를 호출할 수 있습니다.
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)이제 사용자 친화적인 UI로 Pandas 데이터프레임을 시각화할 수 있습니다!
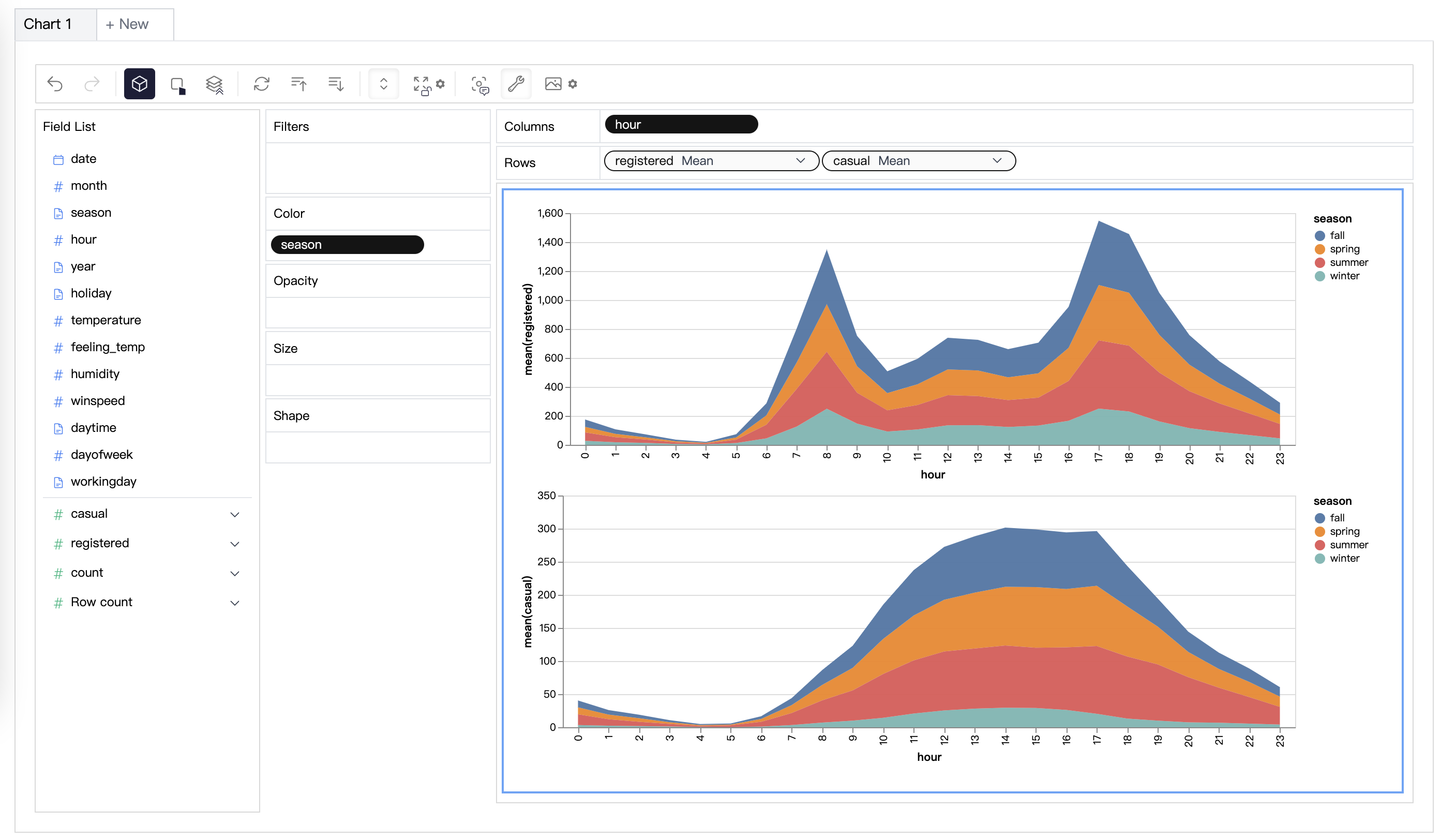
변수를 드래그 앤 드롭하여 단순히 Concat 뷰를 생성할 수 있습니다:
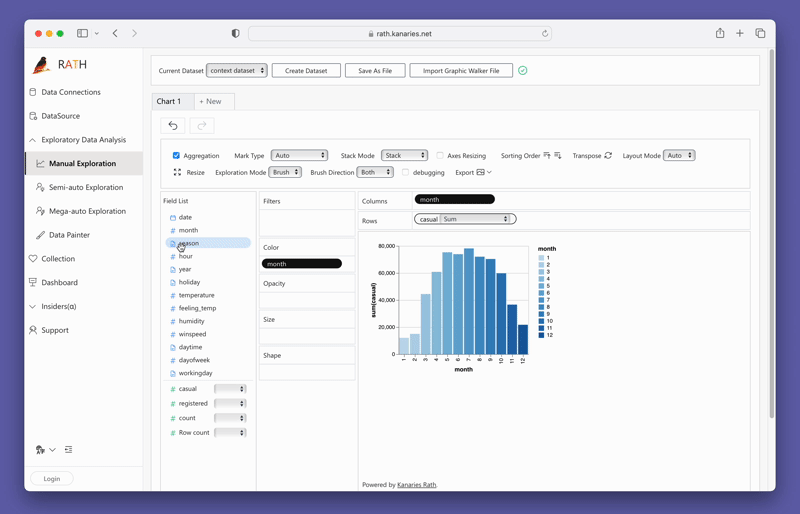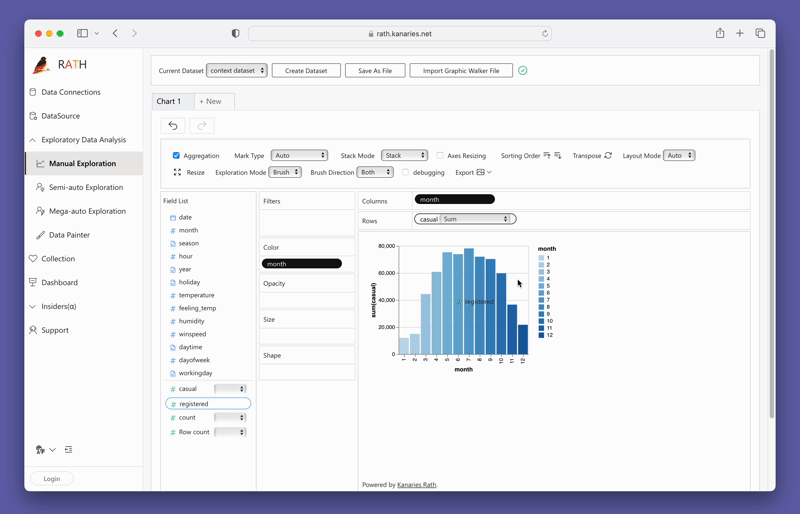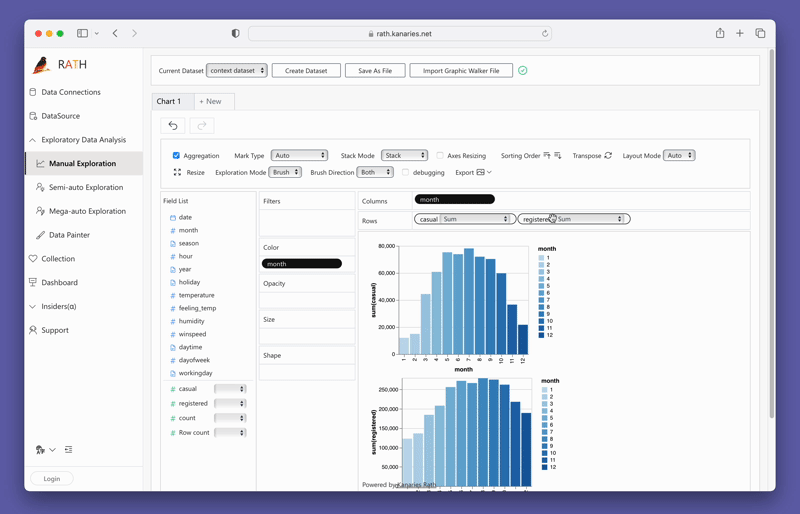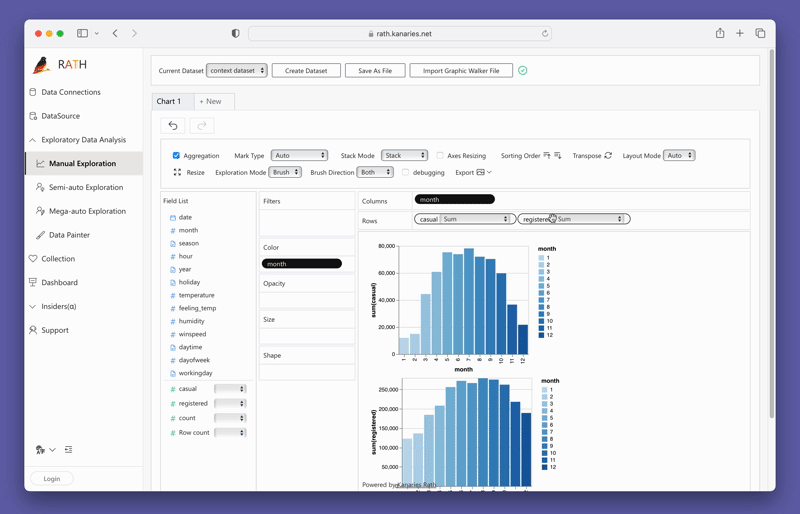
지금 바로 PyGWalker를 테스트해 보려면 Google Colab (opens in a new tab), Binder (opens in a new tab) 또는 Kaggle (opens in a new tab)에서 PyGWalker를 실행할 수 있습니다.
PyGWalker는 오픈 소스입니다. PyGWalker GitHub 페이지 (opens in a new tab)를 확인하고 Towards Data Science 기사 (opens in a new tab)를 읽어보세요.
고급 AI 기반의 자동 데이터 분석 도구인 RATH (opens in a new tab)도 꼭 확인해보세요. RATH 역시 오픈 소스이며 GitHub (opens in a new tab)에서 소스 코드를 확인할 수 있습니다.
FAQ
PySpark를 사용하여 두 개의 데이터프레임을 어떻게 결합할 수 있을까요?
PySpark는 Python, Java, Scala 또는 R로 데이터 처리 애플리케이션을 작성할 수 있는 오픈 소스 대규모 데이터 처리 프레임워크입니다. PySpark를 사용하여 두 개의 데이터프레임을 결합하려면 두 개의 DataFrame 개체와 선택적인 결합 표현식을 인수로 사용하는 join() 메서드를 사용할 수 있습니다. join 방법을 how 매개변수를 사용하여 지정할 수 있습니다.
R을 사용하여 두 개의 데이터프레임을 어떻게 합칠 수 있을까요?
R을 사용하여 두 개의 데이터프레임을 병합하려면 merge() 함수를 사용할 수 있습니다. 이 함수는 두 개의 데이터프레임과 데이터를 병합하는 방법을 지정하는 선택적인 인수 집합을 인수로 받습니다.
판다스에서 두 개 이상의 데이터프레임을 어떻게 추가할 수 있을까요?
판다스에서 두 개 이상의 데이터프레임을 추가하려면 concat() 함수를 사용할 수 있습니다. 이 함수는 데이터프레임의 리스트와 선택적인 축 매개변수를 인수로 받으며 데이터프레임을 연결할 축을 지정합니다.
판다스를 사용하여 공통 열을 기준으로 두 개의 데이터프레임을 어떻게 결합할 수 있을까요?
판다스를 사용하여 공통 열을 기준으로 두 개의 데이터프레임을 결합하려면 merge() 함수를 사용할 수 있습니다. 이 함수는 두 개의 데이터프레임과 데이터를 병합하는 방법을 지정하는 선택적인 인수 집합을 인수로 받습니다. on 매개변수를 사용하여 결합할 열을 지정할 수 있습니다.
결론
결론적으로, 데이터프레임을 병합, 결합 및 연결하는 것은 데이터 분석에서 필수적인 작업입니다. pandas, PySpark 및 R 같은 강력한 도구의 도움으로 이러한 작업을 쉽고 효율적으로 수행할 수 있습니다. 대용량 또는 소규모 데이터셋에 대해 유연하고 직관적인 방식으로 데이터를 조작할 수 있는 이러한 도구를 활용해 보세요.