자동 데이터 분석을 위한 상위 10개 Python 라이브러리

- Runcell Science: Claude Science를 대체할 오픈소스 AI 연구 워크스페이스
- 맥 잠자기 방지: 맥북 닫아도 Codex와 Claude Code 계속 실행하기
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026년에 어떤 AI 에이전트 스택을 선택해야 할까?
- Claude Code로 Jupyter 노트북을 분석하는 방법 | Data Science 실무 가이드와 한계
- Claude Code 루틴 사용법: AI 에이전트 cron 작업과 자동 트리거
- Claude Code Desktop에서 Bypass permissions 켜는 법
- Google의 A2A 프로토콜을 사용한 두 개의 Python 에이전트 빌드하기 - 단계별 튜토리얼
- 2025년 파이썬에서 가장 성장하는 상위 10개 데이터 시각화 라이브러리
소개
자동화된 데이터 분석은 오늘날의 데이터 중심 세계에서 점점 더 중요해지고 있습니다.매일 생성되는 데이터의 양이 많기 때문에 대규모 데이터 세트를 수동으로 분석하고 처리하려면 시간이 많이 걸리고 오류가 발생하기 쉽습니다.다행스럽게도 Python은 데이터 분석 작업을 자동화할 수 있는 광범위한 라이브러리를 제공하므로 대규모 데이터 세트로 작업하고 의미 있는 통찰력을 추출하기가 더 쉬워집니다.
이 글에서는 데이터 분석을 자동화하는 데 사용할 수 있는 10개의 Python 라이브러리를 살펴보겠습니다.이러한 라이브러리로는 Pandas, NumPy, Matplotlib, Seaborn, Scikit-learn, TensorFlow, Keras, NLTK 및 포함하려는 기타 관련 라이브러리가 있습니다.
1부.차세대 자동 데이터 분석: RATH
RATH (opens in a new tab) 는 Tableau와 같은 데이터 분석 및 시각화 도구에 대한 오픈 소스 대안을 넘어섭니다.패턴, 인사이트, 인과 관계를 발견하여 증강 분석 엔진으로 탐색적 데이터 분석 워크플로를 자동화하고 강력한 자동 생성 다차원 데이터 시각화를 통해 이러한 통찰력을 제공합니다.
|기능|설명|미리보기|
|: ---: |---|: ---: |
| AutoEDA |패턴, 인사이트 및 인과 관계를 발견하기 위한 증강 분석 엔진.클릭 한 번으로 데이터 세트를 탐색하고 데이터를 시각화하는 완전 자동화된 방법입니다.|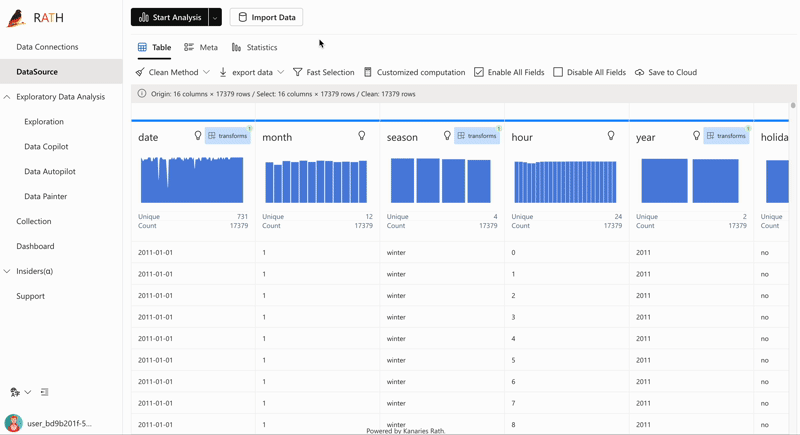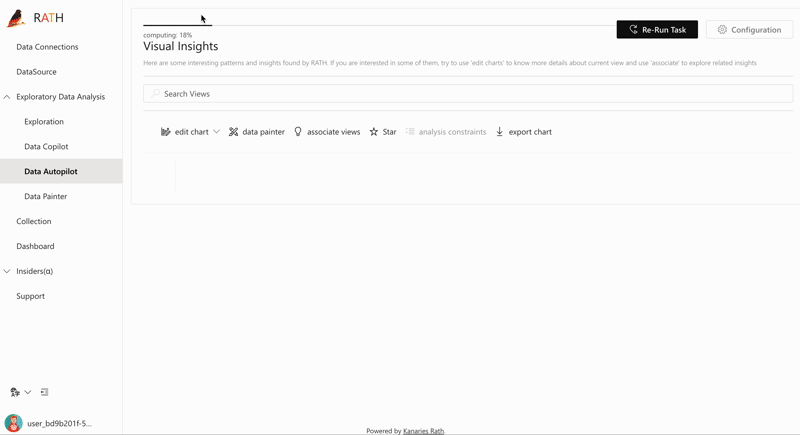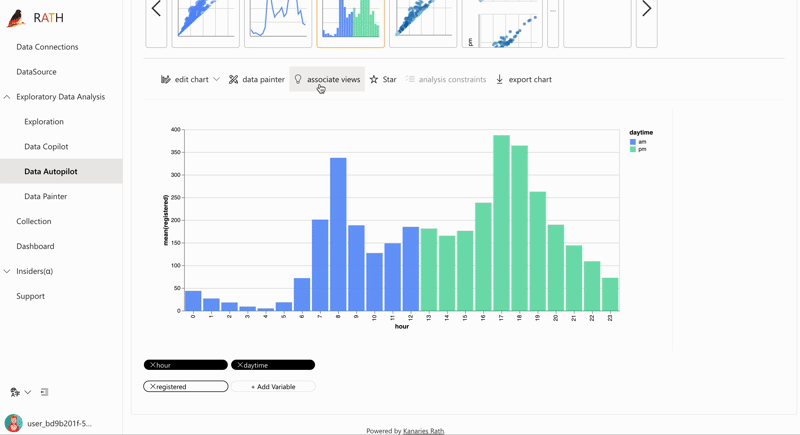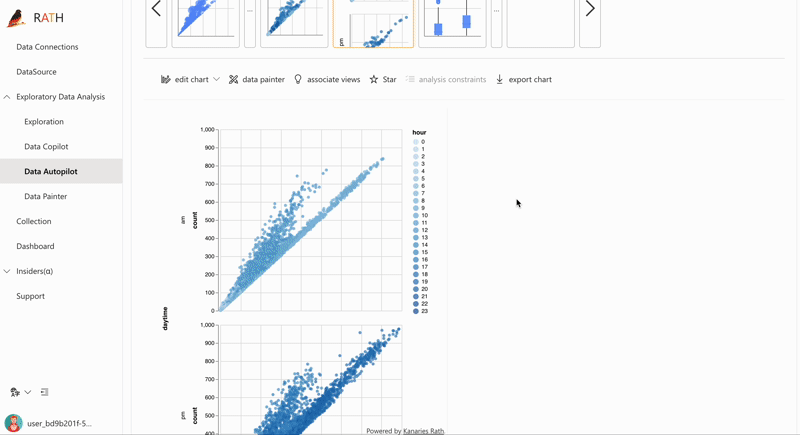 |
| 데이터 시각화 | 효과 점수를 기반으로 다차원 데이터 시각화를 생성하십시오.|
|
| 데이터 시각화 | 효과 점수를 기반으로 다차원 데이터 시각화를 생성하십시오.|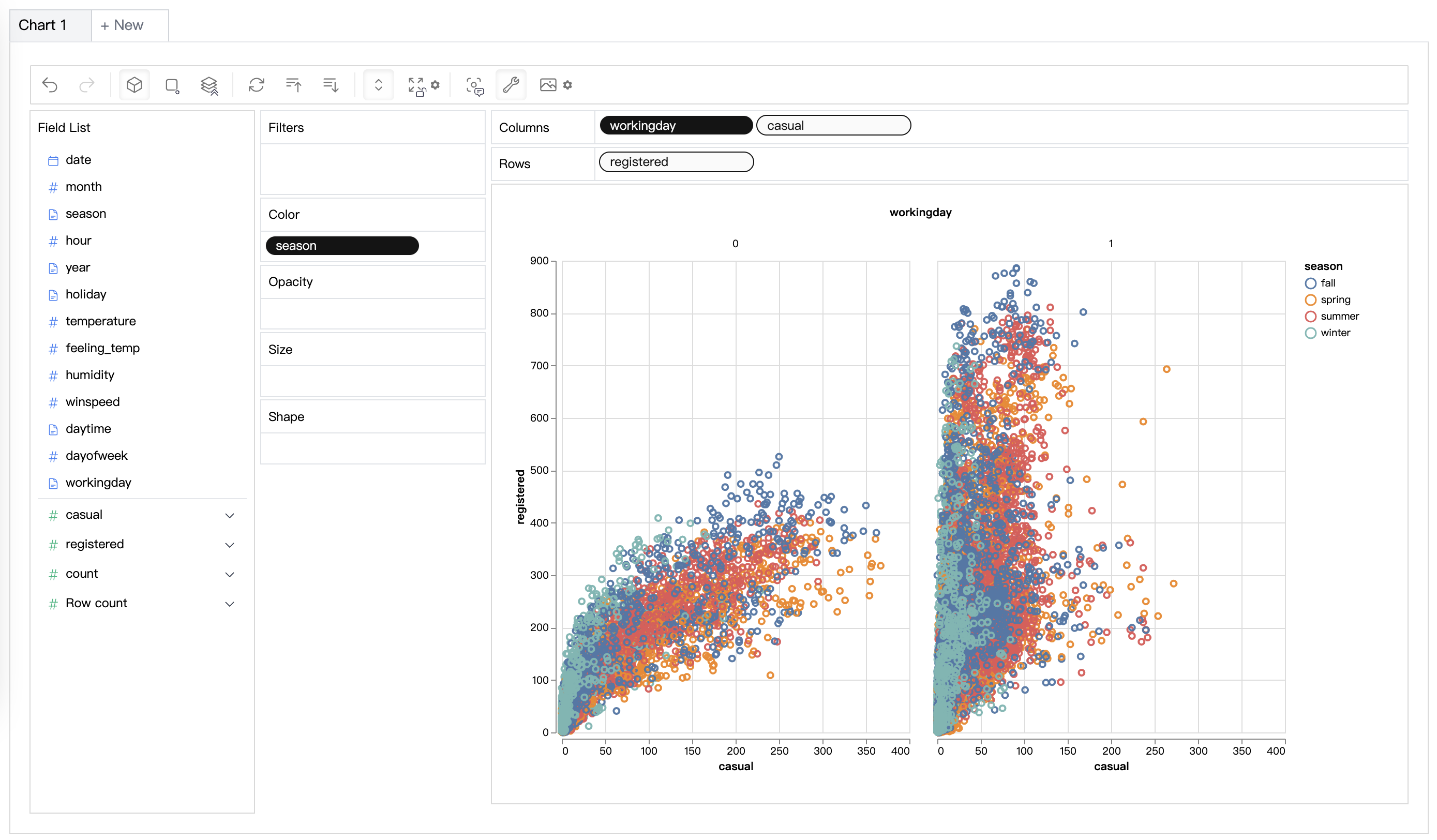 |
| 데이터 랭글러 |데이터 및 데이터 변환의 요약을 생성하기 위한 자동화된 데이터 랭글러.|
|
| 데이터 랭글러 |데이터 및 데이터 변환의 요약을 생성하기 위한 자동화된 데이터 랭글러.|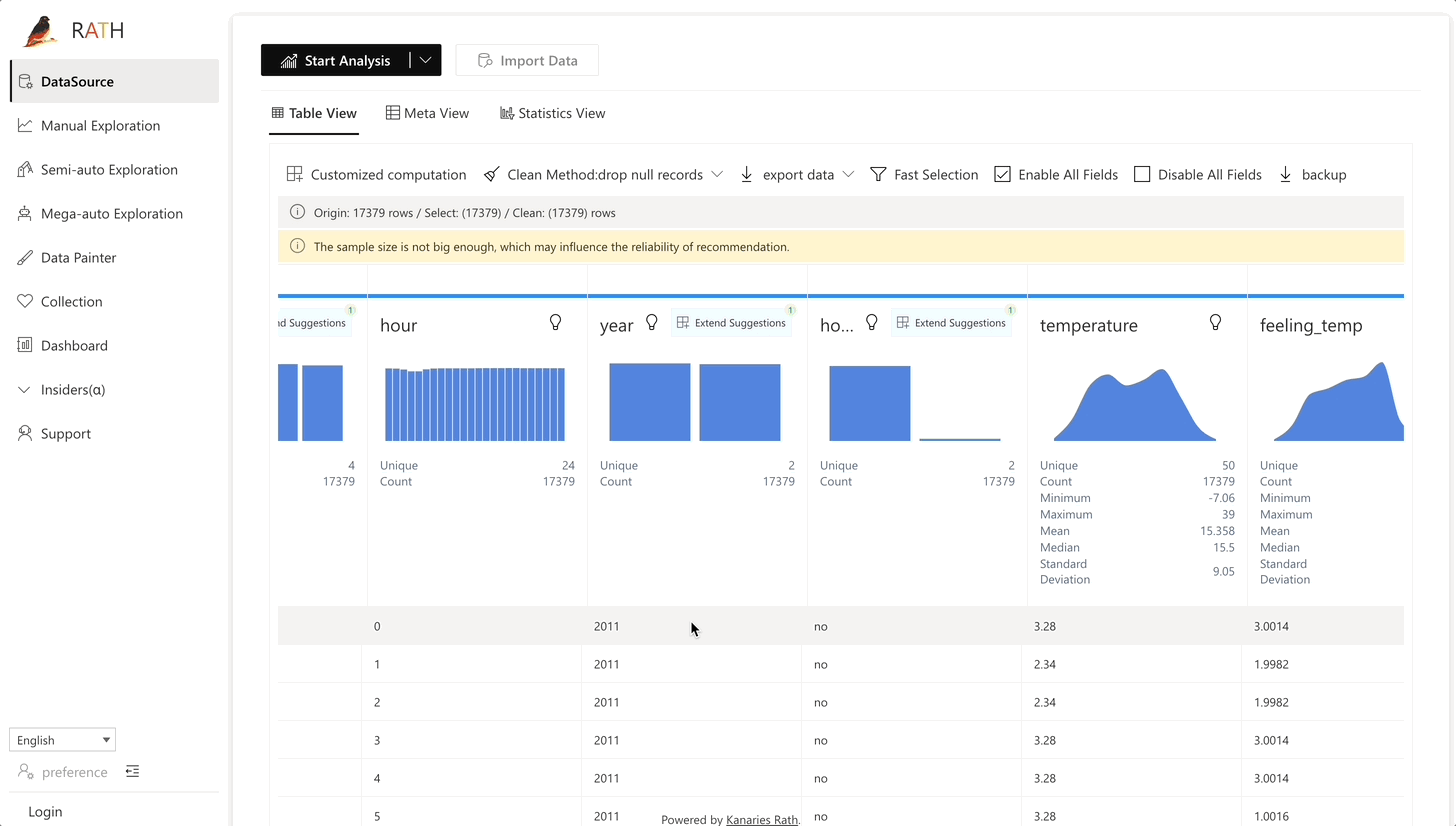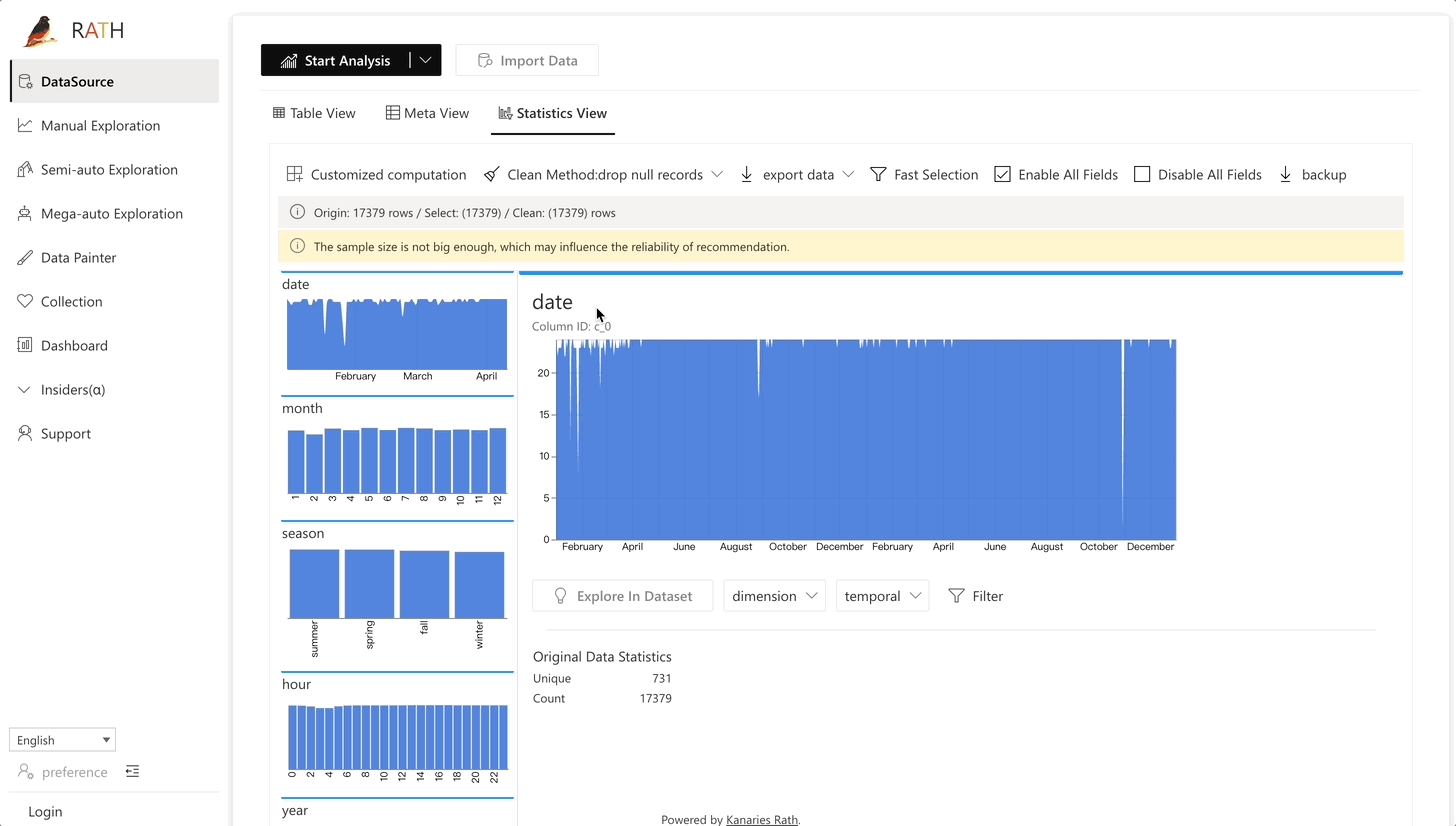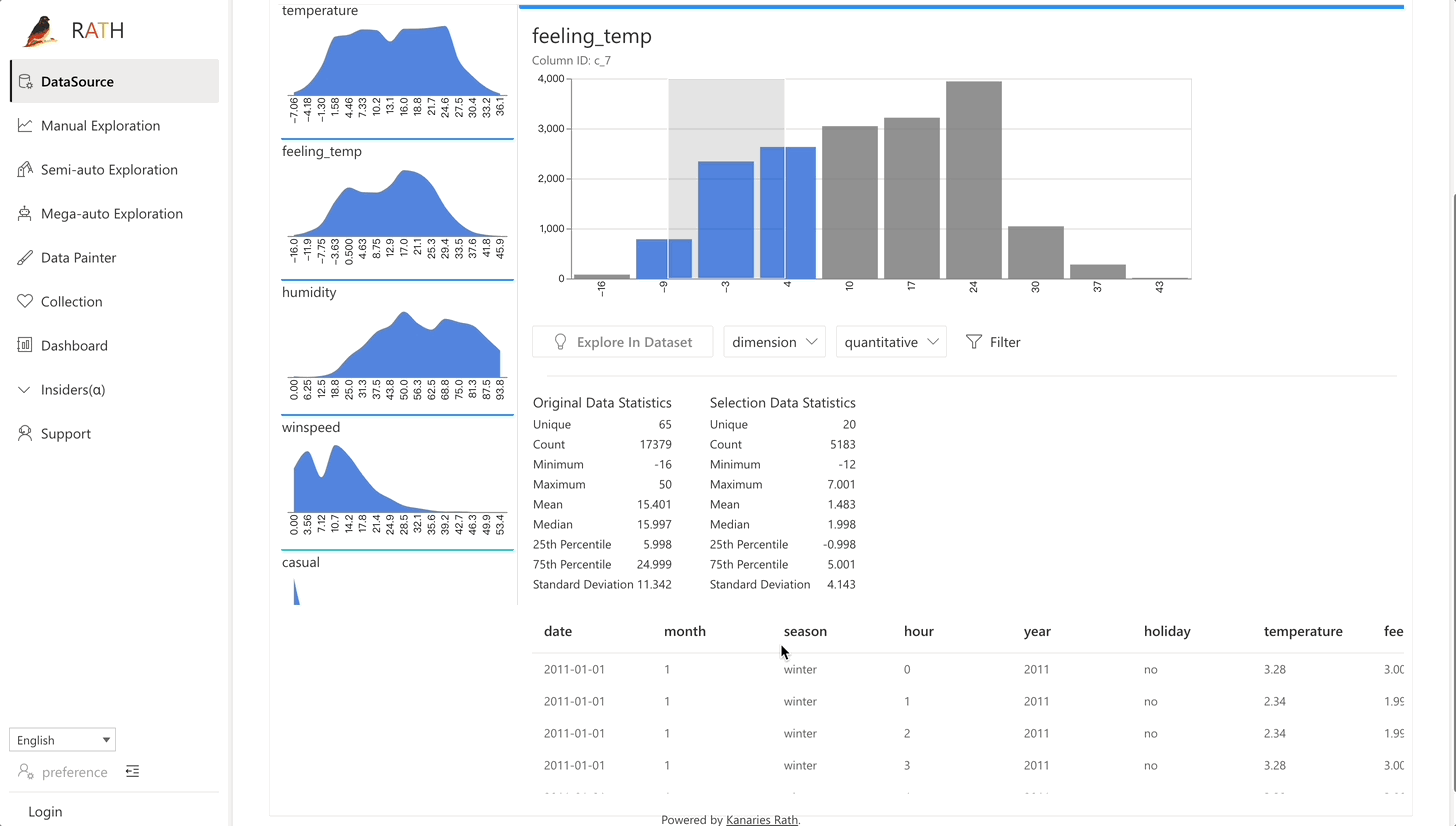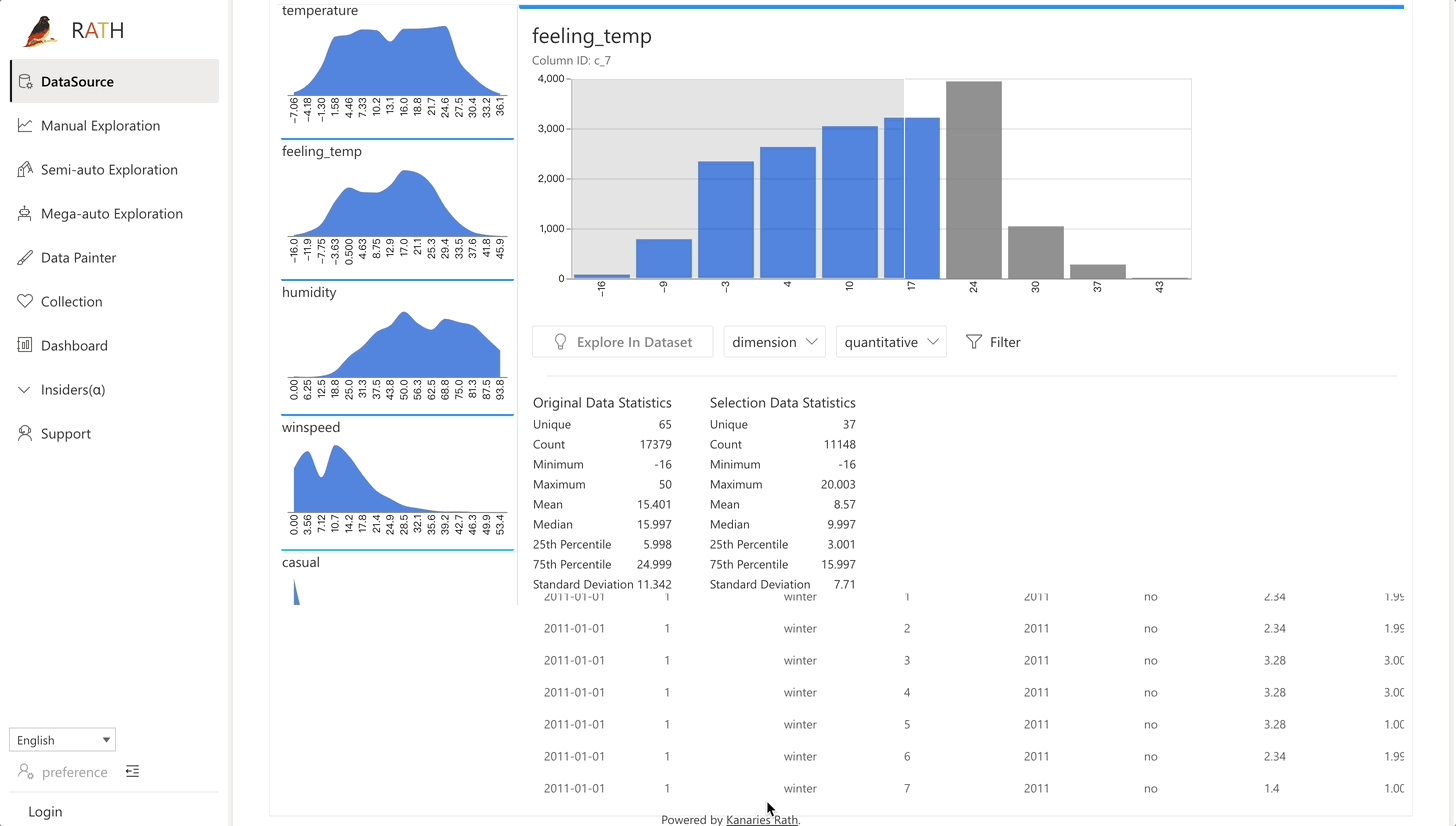 |
| 데이터 탐색 부파일럿 |자동화된 데이터 탐색과 수동 탐색을 결합합니다.RATH는 데이터 과학 분야의 부조종사로 일하며 관심사를 파악하고 증강 분석 엔진을 사용하여 관련 권장 사항을 생성합니다.|
|
| 데이터 탐색 부파일럿 |자동화된 데이터 탐색과 수동 탐색을 결합합니다.RATH는 데이터 과학 분야의 부조종사로 일하며 관심사를 파악하고 증강 분석 엔진을 사용하여 관련 권장 사항을 생성합니다.|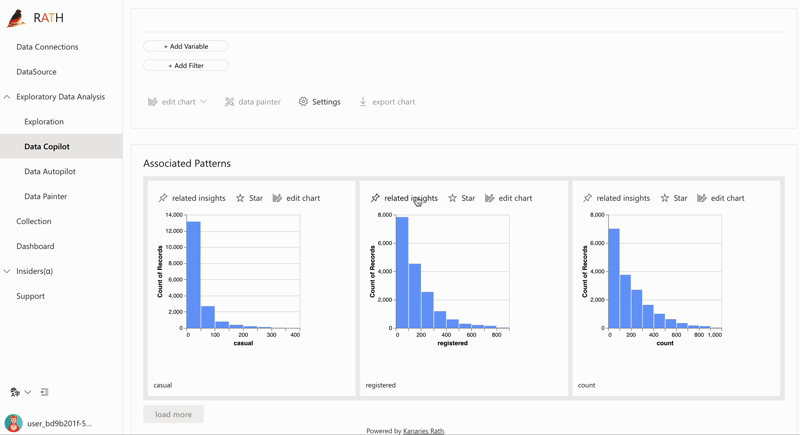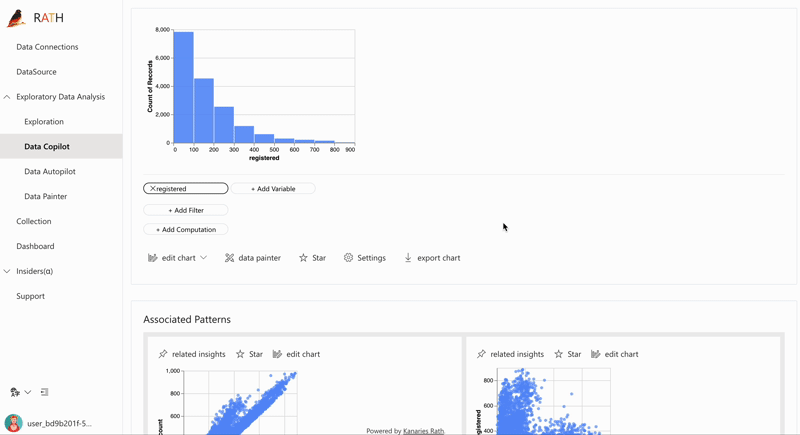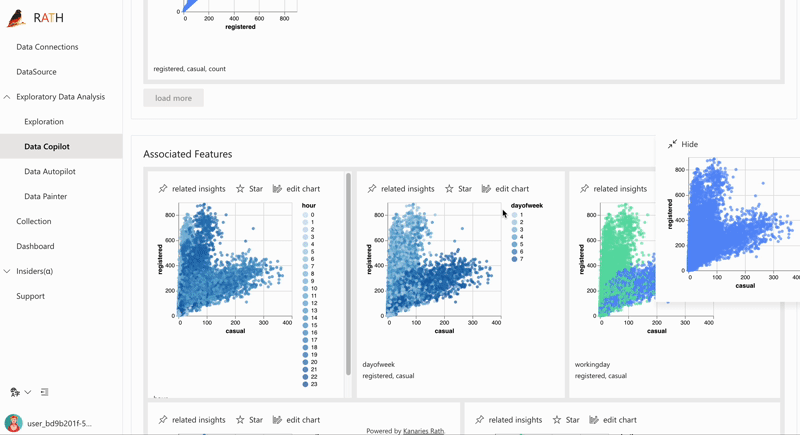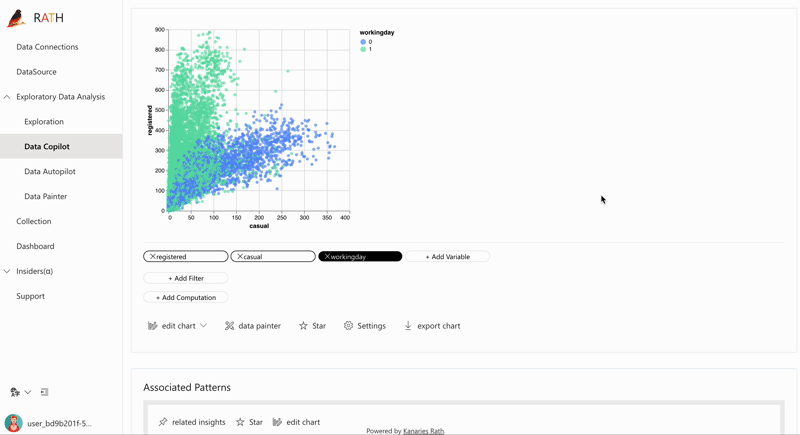 |
| 데이터 페인터 |추가 분석 기능을 사용하여 데이터에 직접 색상을 지정하여 탐색적 데이터 분석을 위한 직관적이고 강력한 대화형 도구입니다.|
|
| 데이터 페인터 |추가 분석 기능을 사용하여 데이터에 직접 색상을 지정하여 탐색적 데이터 분석을 위한 직관적이고 강력한 대화형 도구입니다.|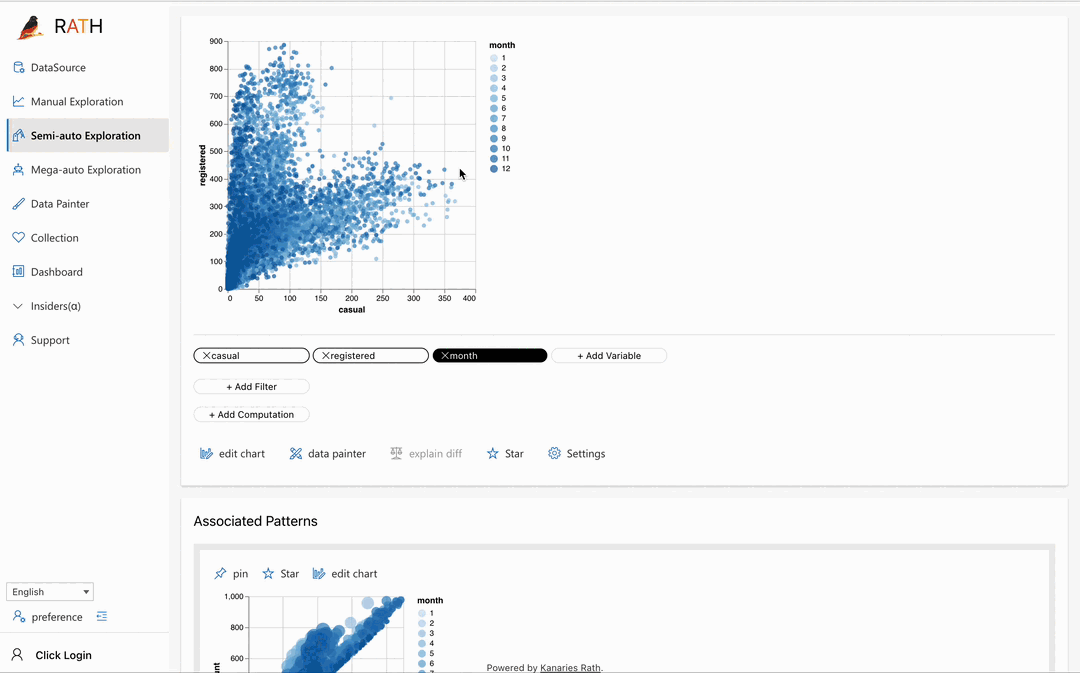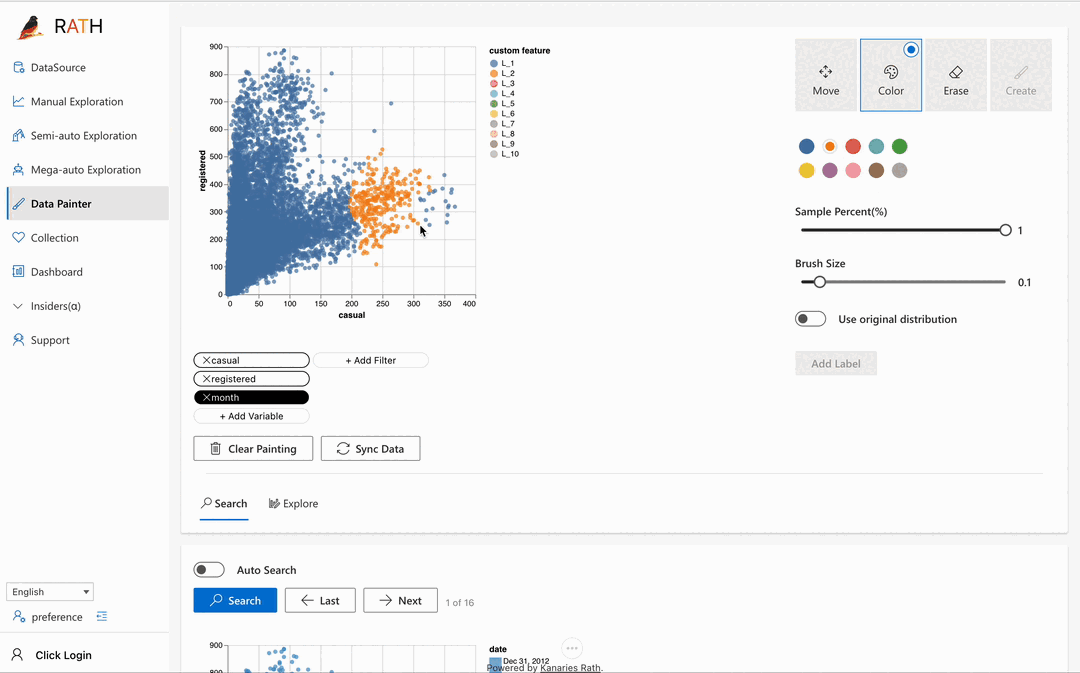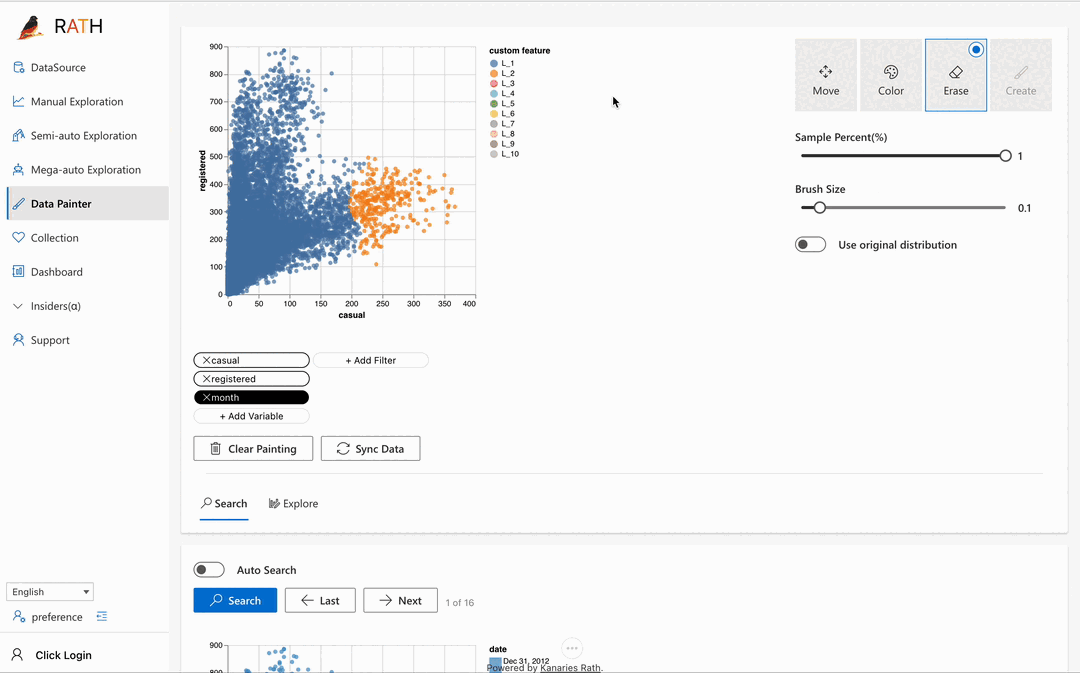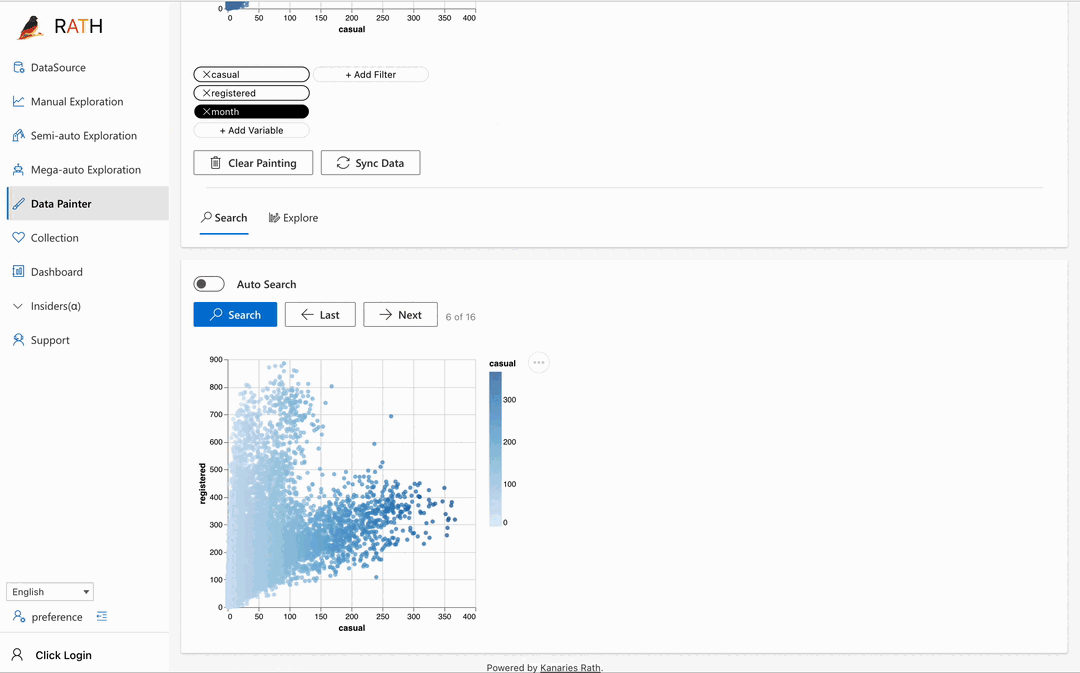 |
|대시보드|멋진 대화형 데이터 대시보드를 구축하세요 (대시보드에 제안을 제공할 수 있는 자동화된 대시보드 디자이너 포함) .|
|
|대시보드|멋진 대화형 데이터 대시보드를 구축하세요 (대시보드에 제안을 제공할 수 있는 자동화된 대시보드 디자이너 포함) .|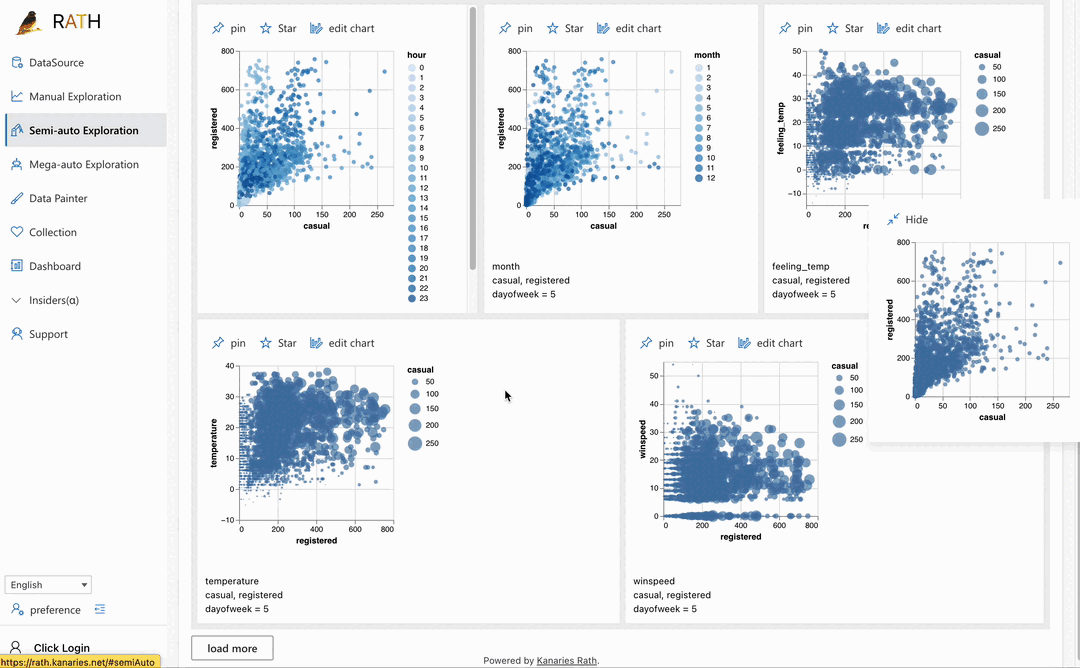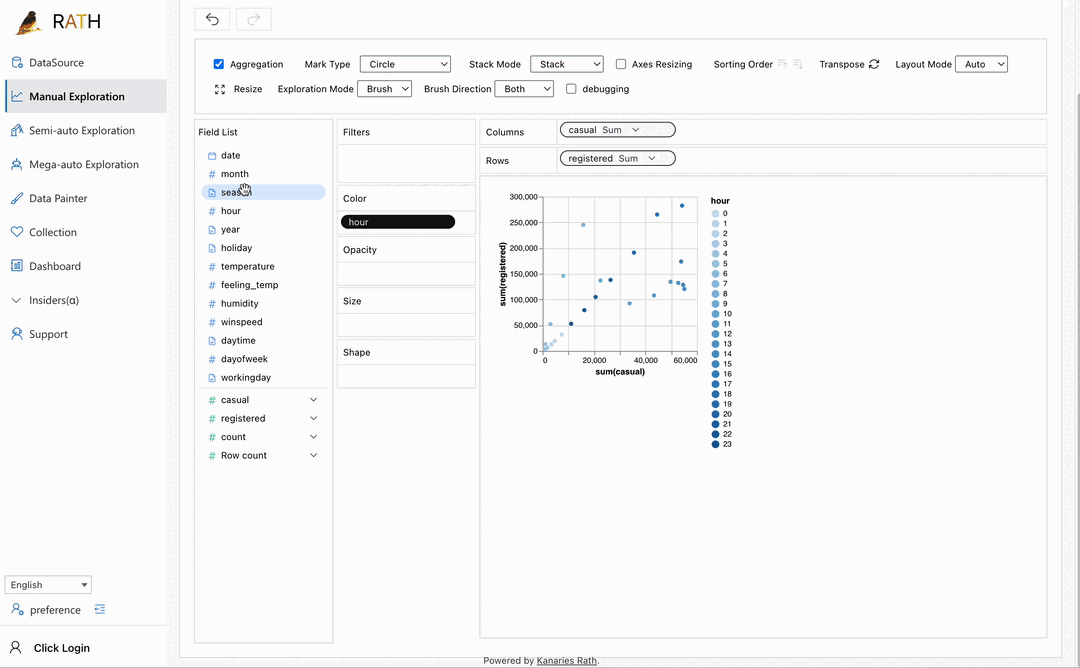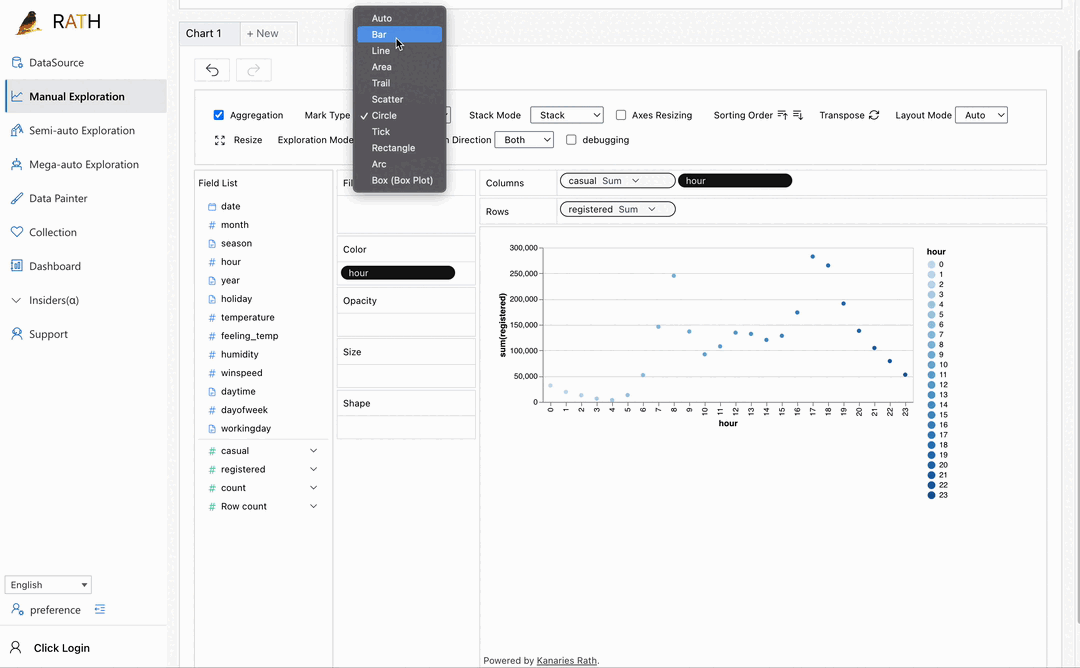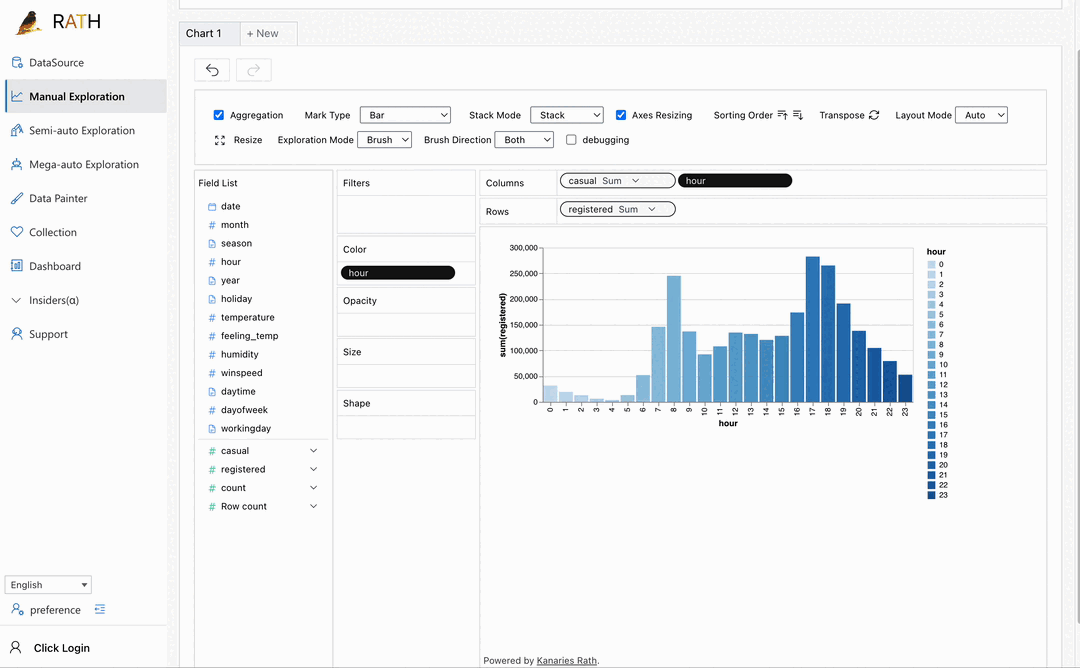 |
| 인과 분석 |복잡한 관계 분석을 위한 인과 관계 발견 및 설명 제공.|
|
| 인과 분석 |복잡한 관계 분석을 위한 인과 관계 발견 및 설명 제공.|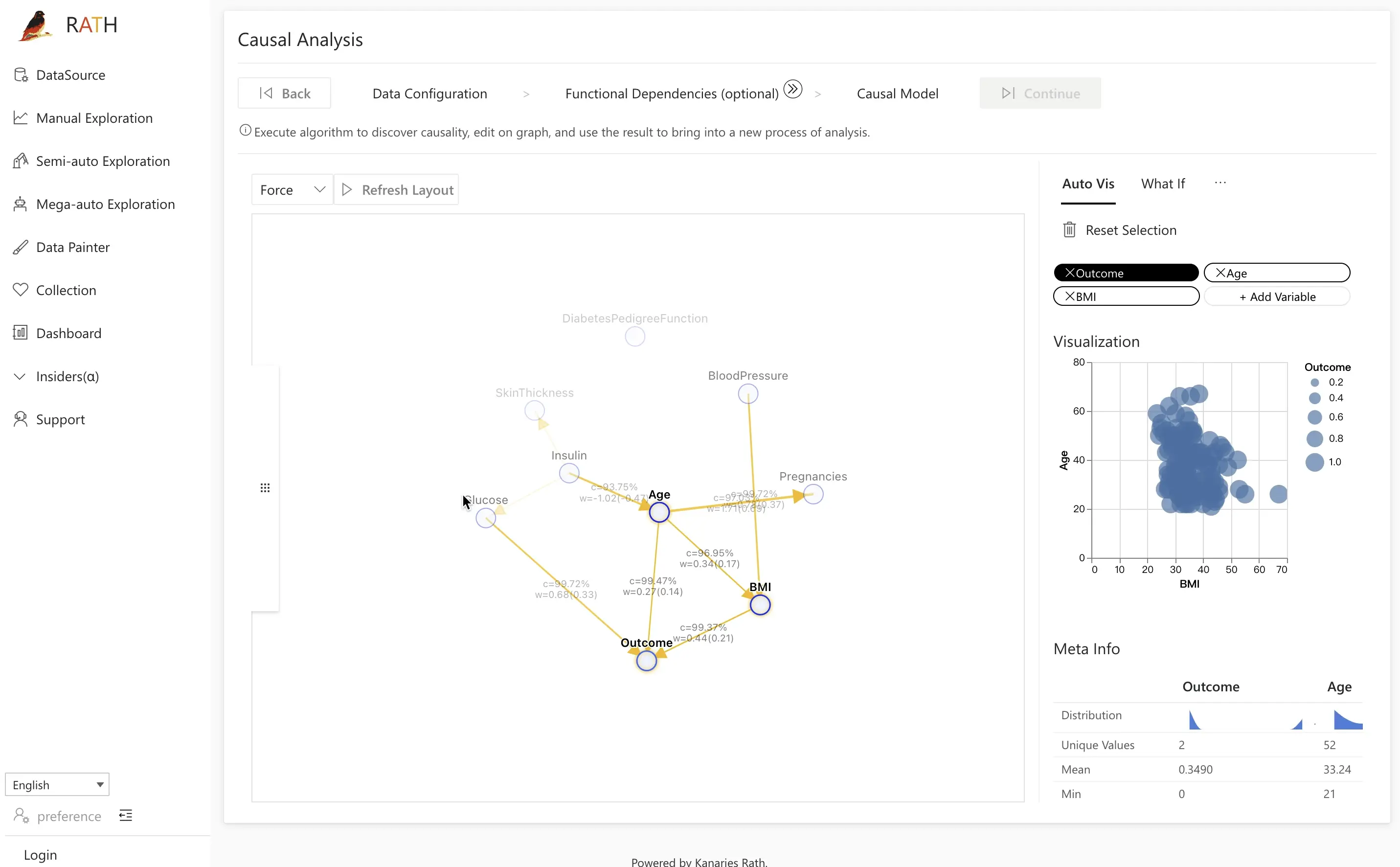 |
|
[RATH는 광범위한 데이터 소스를 지원합니다](/rath/connect-data/choose-a-data-source #online -데이터베이스).RATH에 연결할 수 있는 몇 가지 주요 데이터베이스 솔루션은 다음과 같습니다. MySQL, ClickHouse, Amazon Athena, Amazon Redshift, Apache Spark SQL, Apache Doris, Apache Hive, Apache Impala, Apache Kylin, Oracle 및 PostgreSQL이 있습니다.
RATH (opens in a new tab) 는 오픈 소스입니다.RATH GitHub를 방문하여 차세대 Auto-EDA 도구를 경험해 보십시오.RATH 온라인 데모를 데이터 분석 플레이그라운드로 활용할 수도 있습니다!

파트 2.최고의 Python 자동 데이터 분석 라이브러리
1.판다
Pandas는 Python에서 가장 많이 사용되는 데이터 분석 라이브러리 중 하나입니다.대용량 데이터를 쉽게 처리할 수 있는 강력한 데이터 구조 및 데이터 조작 도구를 제공합니다.Pandas를 사용하면 추가 분석을 위해 데이터를 쉽게 로드, 정리 및 준비할 수 있습니다.또한 필터링, 그룹화 및 데이터 조인과 같은 데이터 조작 작업을 수행할 수 있습니다.
다음은 Pandas를 사용하여 DataFrame에 데이터를 로드하고 누락된 값을 처리하는 방법의 예입니다.
코드_블록_플레이스홀더_0
2.넘피
NumPy는 수치 계산 및 데이터 조작을 위한 강력한 라이브러리입니다.광범위한 수학 함수를 제공하며 데이터 배열에 대한 연산을 수행할 수 있습니다.NumPy를 사용하면 데이터의 평균, 표준 편차 및 상관 관계와 같은 통계를 쉽게 계산할 수 있습니다.
다음은 NumPy를 사용하여 데이터 배열의 평균과 표준편차를 계산하는 방법의 예입니다.
코드_블록_플레이스홀더_1
3.매트 플롯 라이브러리
Matplotlib은 정적, 애니메이션 및 대화형 시각화를 만들 수 있는 Python의 플로팅 라이브러리입니다.데이터 시각화를 위한 강력한 도구이며 라인 플롯, 스캐터 차트 및 히스토그램과 같은 광범위한 플롯을 만드는 데 사용할 수 있습니다.
다음은 Matplotlib를 사용하여 간단한 선 플롯을 만드는 방법의 예입니다.
코드_블록_플레이스홀더_2
4.바다에서 태어난
Seaborn은 Matplotlib를 기반으로 구축된 라이브러리로 고급 시각화를 만들 수 있습니다.Pandas를 통한 데이터 시각화 지원이 내장되어 있으며 히트맵, 박스 플롯 및 바이올린 플롯을 만드는 데 사용할 수 있습니다.
다음은 Seaborn을 사용하여 히트맵을 만드는 방법의 예입니다.
코드_블록_플레이스홀더_3
5.Scikit-Learn
Scikit-learn은 파이썬 기반 머신 러닝을 위한 강력한 라이브러리입니다.분류, 회귀, 클러스터링 등을 위한 광범위한 알고리즘을 제공합니다.또한 NumPy 및 Pandas와 같은 다른 라이브러리와도 호환되므로 데이터 분석 워크플로우와 쉽게 통합할 수 있습니다.
다음은 scikit-learn을 사용하여 선형 회귀 모델을 구축하는 방법의 예입니다.
코드_블록_플레이스홀더_4
6.텐서플로우
TensorFlow는 파이썬의 딥 러닝을 위한 강력한 라이브러리입니다.이를 통해 기계 학습 모델, 특히 딥 러닝 모델을 구축, 학습 및 배포할 수 있습니다.TensorFlow를 사용하면 신경망을 쉽게 구축하고 이미지 분류 및 자연어 처리와 같은 작업을 수행할 수 있습니다.
다음은 TensorFlow를 사용하여 간단한 피드포워드 신경망을 구축하는 방법의 예입니다.
코드_블록_플레이스홀더_5
7.케라스
케라스는 파이썬으로 작성된 고수준 신경망 API입니다.신경망 모델을 쉽게 구축, 학습 및 테스트할 수 있는 사용자 친화적인 API입니다.TensorFlow를 기반으로 구축되었으며 최소한의 코드로 복잡한 신경망을 구축하는 데 사용할 수 있습니다.
다음은 Keras를 사용하여 간단한 피드포워드 신경망을 구축하는 방법의 예입니다.
코드_블록_플레이스홀더_6
8.NLTK
NLTK (자연어 툴킷) 는 자연어 처리 (NLP) 를 위한 도구를 제공하는 Python 라이브러리입니다.토큰화, 어간 분석 및 품사 태깅과 같은 작업을 수행하는 데 사용할 수 있습니다.NLTK를 사용하면 텍스트 데이터를 쉽게 분석하고 이해할 수 있습니다.
다음은 NLTK를 사용하여 문장을 토큰화하는 방법의 예입니다.
코드_블록_플레이스홀더_7
9.스키피
SciPy는 NumPy를 기반으로 구축되고 광범위한 수학 및 과학 함수를 제공하는 파이썬 라이브러리입니다.최적화, 통합, 보간, 신호 및 이미지 처리 등에 사용할 수 있습니다.과학 컴퓨팅 및 데이터 분석을 위한 강력한 라이브러리입니다.
다음은 Scipy를 사용하여 최적화를 수행하는 방법의 예입니다.
코드_블록_플레이스홀더_8
10.통계 모델
Statsmodels는 다양한 통계 모델을 추정하기 위한 클래스와 함수를 제공하는 Python 라이브러리입니다.또한 다양한 통계 테스트 및 데이터 탐색 도구를 제공합니다.NumPy 및 Pandas와 호환되므로 데이터 분석 워크플로우와 쉽게 통합할 수 있습니다.
다음은 Statsmodels를 사용하여 선형 회귀를 수행하는 방법의 예입니다.
코드_블록_플레이스홀더_9
결론
결론적으로, 이것들은 데이터 분석 작업을 자동화하는 데 사용할 수 있는 Python에서 사용할 수 있는 많은 라이브러리의 몇 가지 예일 뿐입니다.이러한 라이브러리를 사용하면 대규모 데이터 세트로 쉽게 작업하고, 데이터 정리 및 준비를 수행하고, 의미 있는 통찰력을 추출하고, 시각화를 만들 수 있습니다.보다 현대화된 인터페이스와 인과 분석, 데이터 탐색 부조종 등과 같은 훨씬 더 발전된 기능을 선호하는 사람들에게 RATH는 도움을 줄 수 있는 최고의 도구입니다.