PyGWalker에서 히스토그램 또는 히트맵 만드는 방법
업데이트

히스토그램 & 히트맵 소개
히스토그램
히스토그램은 숫자 데이터를 어떻게 분포하는지 보여주는 그래프입니다. 값은 버킷(또는 bin)으로 그룹화되고, 각 버킷에 맞는 값의 수가 계산됩니다.
히스토그램은 실제 값 대신 버킷을 그래프화합니다. 각 막대는 하나의 버킷을 상징하며, 막대의 높이는 해당 버킷 간격 내에 들어가는 값의 빈도(예: 개수)를 나타냅니다.
히트맵
히트맵은 시간에 따라 각 시간 단면이 자체 히스토그램을 나타내는 방식으로 히스토그램과 유사합니다. 빈도를 나타내기 위해 막대 높이를 사용하는 대신 셀을 사용하고, 셀의 색상을 버킷 내 값의 수에 비례하여 채웁니다.
히트맵은 복잡한 정보를 이해하기 쉽게 효과적으로 전달할 수 있는 훌륭한 데이터 시각화 도구입니다.
PyGWalker에서 히스토그램 & 히트맵 만들기
PyGWalker에서 히스토그램 만들기
PyGWalker에서 히스토그램을 만들려면 다음 단계를 따라야 합니다:
-
데이터를 가져옵니다.
-
필드의 드롭다운 아이콘을 클릭합니다. "새 계산"을 선택합니다. 몇 가지 변환을 수행할 수 있습니다. bin 변환 옵션을 클릭합니다. 그러면 **bin(필드 이름)**이 차원 세그먼트에 새로운 필드로 생성됩니다.
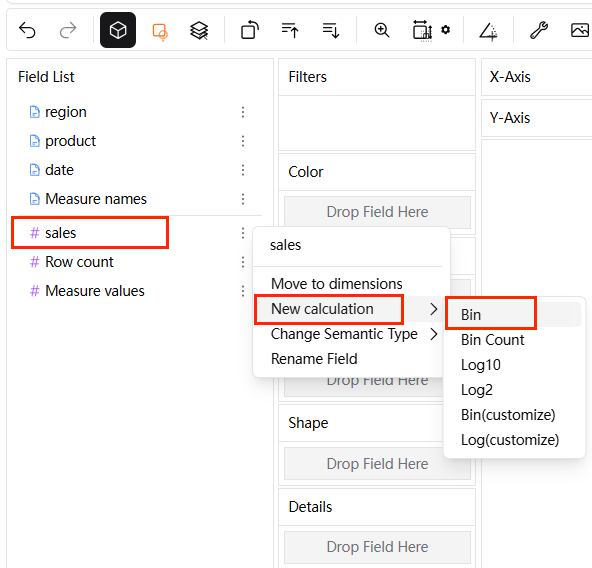
-
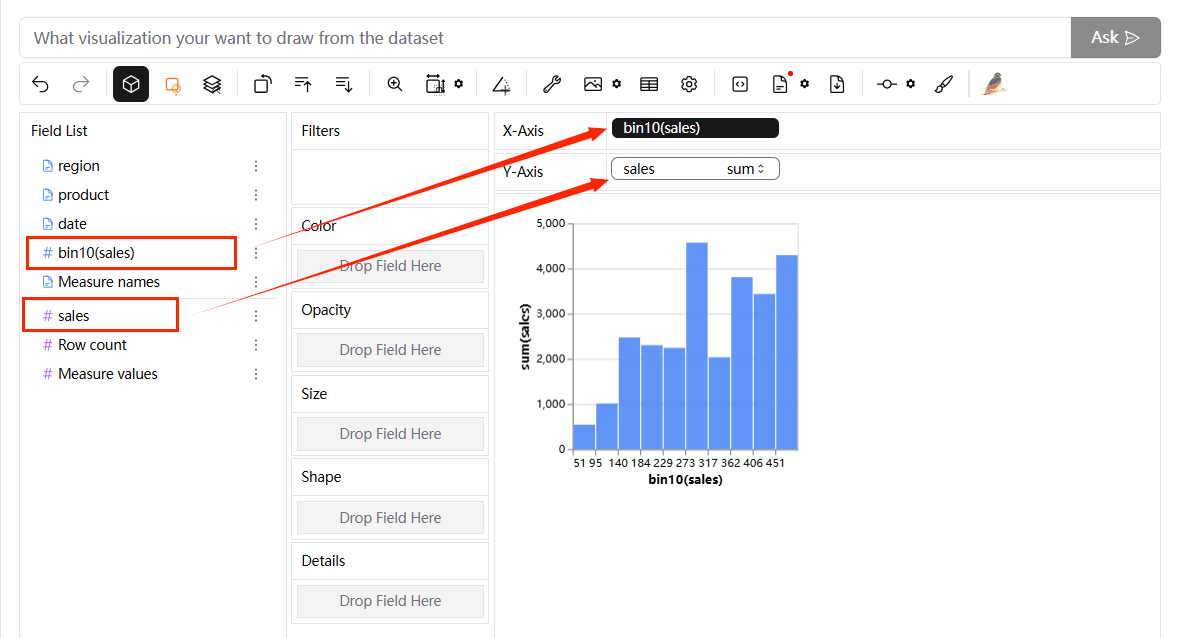
**bin(필드 이름)**을 x축으로, row count를 y축으로 사용하여 히스토그램을 얻을 수 있습니다.
PyGWalker에서 히트맵 만들기
PyGWalker에서 히트맵을 만들려면 다음 단계를 따라야 합니다:
-
데이터를 가져옵니다.
-
차트 유형 선택: 도구 모음에서 "마크 유형" 버튼을 클릭하고 'Rectangle'을 선택합니다.
-
변수 변환: 변수를 좌클릭하면 메뉴가 나타납니다. "새 계산" 옵션을 선택합니다. 몇 가지 변환을 수행할 수 있습니다. bin 변환 옵션을 클릭합니다. 그러면 **bin(필드 이름)**이 차원 세그먼트에 새로운 필드로 생성됩니다.
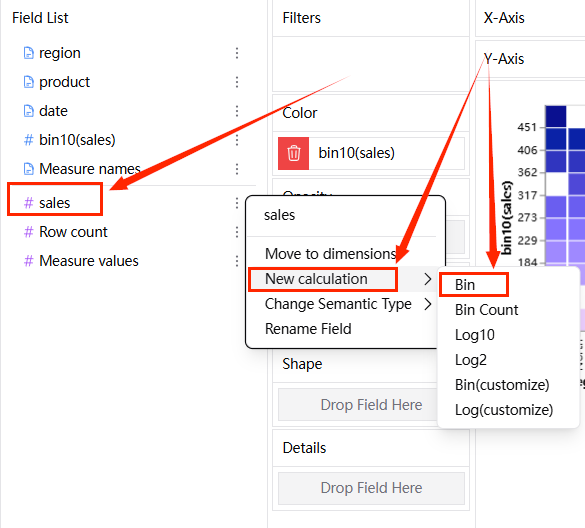
-
차트 생성: 변수를 x축, y축 및 색상 선반으로 드래그 앤 드롭하여 히트맵을 만듭니다.
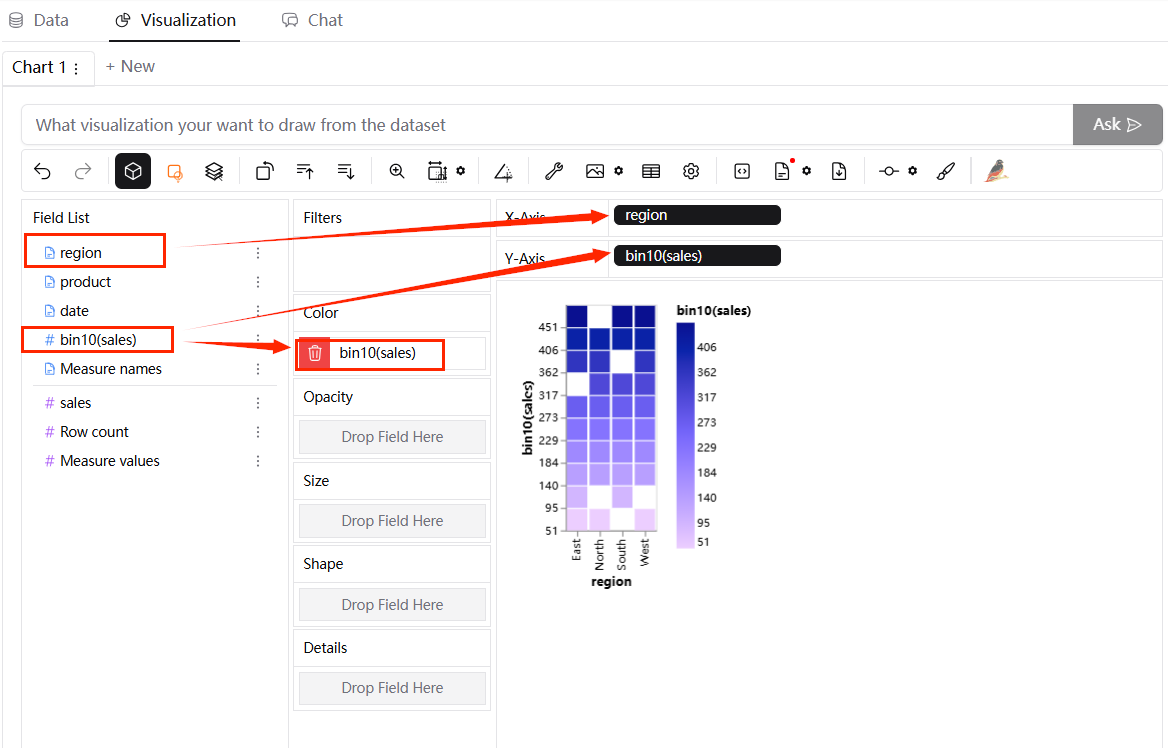
히스토그램 & 히트맵 사용을 위한 모범 사례
히스토그램
0 값 기준선 사용
히스토그램의 중요한 측면은 0 값 기준선으로 플로팅해야 한다는 것입니다. 각 막대의 높이로 데이터의 빈도를 암시하므로 기준선을 변경하거나 규모에 차이를 도입하면 데이터 분포에 대한 인식을 왜곡시킬 수 있습니다.
해석 가능한 bin 경계 선택
일반적으로 bin 크기 1, 2, 2.5, 4 또는 5(5, 10 및 20을 동일하게 나누는)가 적절한 시작점입니다. bin 크기 3, 7 또는 9는 읽기 어려울 수 있으므로 상황에 따라 사용해야 합니다.
히트맵
적절한 색상 팔레트 선택
색상은 히트맵의 핵심 요소이므로 데이터에 맞는 적절한 색상 팔레트를 선택해야 합니다. 대부분의 경우 값과 색상 사이에 순차적인 색상 램프가 있으며, 더 밝은 색상은 더 작은 값을, 더 어두운 색상은 더 큰 값을 나타냅니다.
범례 포함
일반적으로 히트맵에는 색상이 다른 숫자와 어떻게 관련되는지 설명하는 범례가 필요합니다. 범례 없이 시청자는 히트맵의 값을 이해할 수 없습니다. 값과 색상 간의 정확한 관계가 아닌 데이터의 상대적 패턴만 중요한 경우, 범례는 필요하지 않습니다.
결론
히트맵과 히스토그램의 기본을 이해하고 이러한 디자인 팁을 사용함으로써 PyGWalker에서 효과적이고 직관적인 히트맵 및 히스토그램을 만들 수 있습니다. 데이터 시각화의 여정을 즐기세요.