Netflix 데이터로 PyGWalker로 탐색하기
Netflix는 영화와 TV 프로그램을 위한 독보적인 플랫폼으로 많은 사람들에게 인기가 있습니다. 계속해서 늘어나는 라이브러리를 가지고 있는데, 그 내용을 이해하고 분석가, 영화감독, 시청자에게 중요한 추세와 패턴을 알아내기 위해서는 매우 중요합니다. 이 노트북에서는 PyGWalker 라이브러리를 사용하여 Netflix 데이터셋에 심층적으로 다가가 봅니다. 이 라이브러리는 데이터 시각화 및 탐색을 위한 강력한 도구로, 최소한의 코드로 상호작용 가능한 차트를 생성할 수 있어 데이터셋에서 통찰력과 패턴을 발견하기 쉽습니다.
PyGWalker란?
PyGWalker (opens in a new tab)는 데이터 시각화 과정을 단순화하기 위해 설계된 파이썬 라이브러리입니다. 이 라이브러리를 사용하면 사용자는 최소한의 코드로 상호작용 가능한 차트를 생성할 수 있으며, 데이터셋에서 통찰력과 패턴을 발견하기가 쉬워집니다.

PyGWalker를 사용하여 Netflix 콘텐츠 풍경에 대한 명확한 이해를 제공하는 유익한 시각화를 생성할 수 있습니다.
PyGWalker를 사용하여 Netflix 데이터 탐색하기의 단계
환경 설정
시작하기 위해, 분석을 위해 환경이 준비되어 있는지 확인해야 합니다. 이를 위해 PyGWalker 라이브러리를 설치하고 필요한 파이썬 패키지를 가져와야 합니다.
!pip install pygwalker -q --preimport pandas as pd
import pygwalker as pyg
df = pd.read_csv("/kaggle/input/netflix-shows/netflix_titles.csv")Netflix 데이터셋 불러오기 및 전처리
첫 번째 작업은 Netflix 데이터셋을 로드하는 것입니다. 로드한 후에는 추후 분석을 원활하게 하기 위해 전처리를 수행합니다. 이 전처리 과정은 다음과 같습니다:
- date_added 열을 날짜 형식으로 변환합니다.
- date_added 열에서 연도와 월을 추출합니다.
- duration 열을 수정하여 영화의 총 분수 또는 TV 프로그램의 시즌 수로 나타냅니다.
- 2019년 이후의 데이터를 필터링합니다.
df["date_added"] = pd.to_datetime(df["date_added"])
df["date_added_year"] = df["date_added"].dt.year.fillna(0).astype(int)
df["date_added_month"] = df["date_added"].dt.month.fillna(0).astype(int)
df["duration"] = df["duration"].fillna("0").str.split(" ").str[0].astype(int)
df = df[df["date_added_year"] <= 2019]
df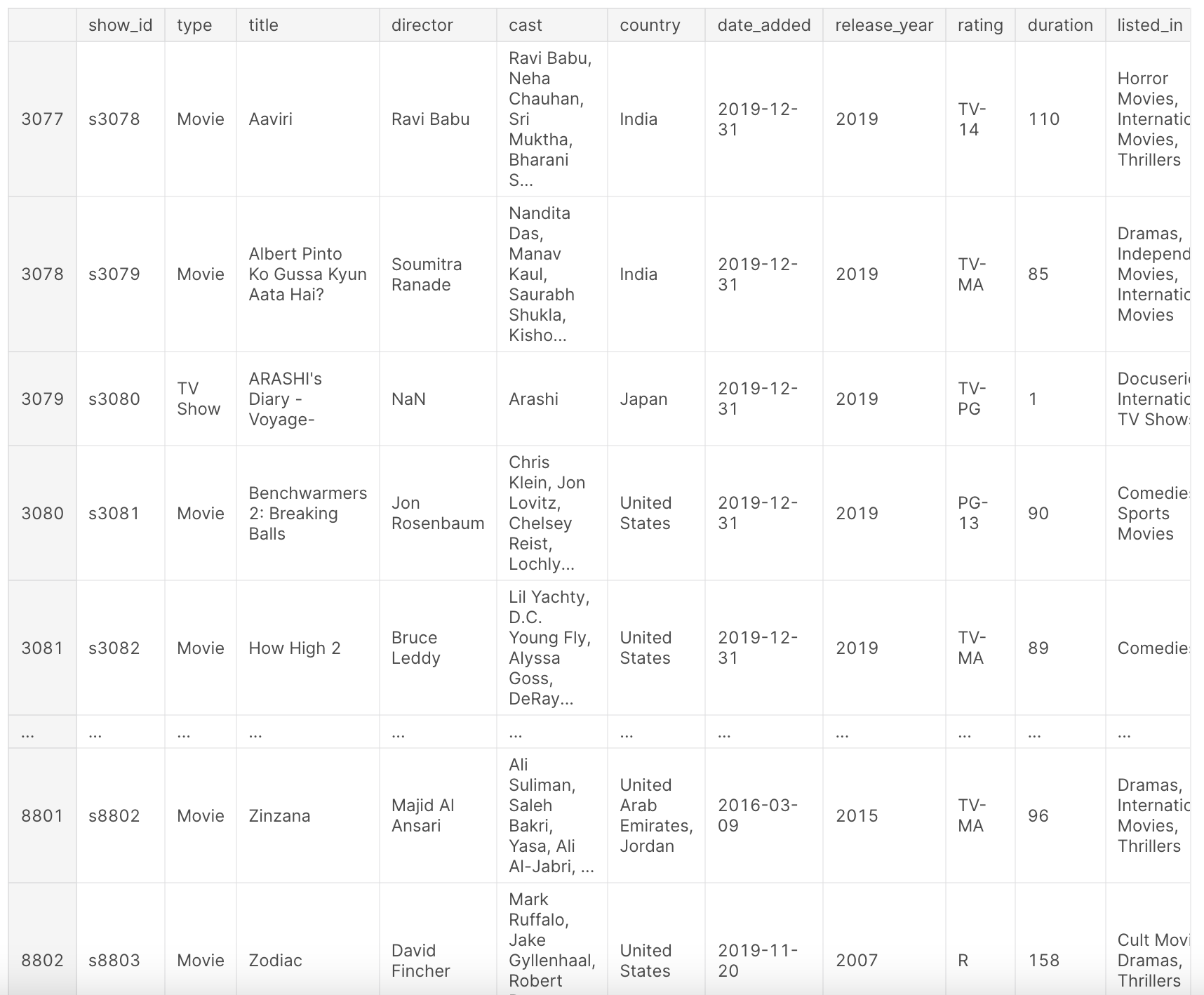
Netflix 데이터셋 개요
위의 전처리 작업을 통해 데이터셋 df는 Netflix 제목에 대한 포괄적인 개요를 제공합니다. 이 데이터셋에는 영화 또는 TV 쇼인지, 제목, 감독, 출연진, 제작 국가, Netflix에 추가된 날짜, 개봉 연도, 등급, 영화의 총 분수 또는 TV 프로그램의 시즌 수, 장르 및 간단한 설명과 같은 정보가 포함되어 있습니다.
이 데이터셋은 2019년까지의 Netflix 콘텐츠 풍경의 스냅샷을 제공하며, 이를 통해 몇 년 동안의 추세, 선호도 및 성장 패턴을 분석할 수 있습니다. 다음 열을 살펴보세요:
show_id: 각 영화/TV 쇼의 고유 IDtype: 영화 또는 TV 쇼를 식별하는 기호title: 영화/TV 쇼의 제목director: 영화의 감독cast: 영화/쇼에 참여한 배우들country: 영화/쇼가 제작된 국가date_added: Netflix에 추가된 날짜release_year: 영화/쇼의 실제 출시 연도rating: 영화/쇼의 TV 등급duration: 총 상영 시간(분) 또는 시즌 수listed_in: 장르description: 영화/쇼에 대한 간단한 설명
PyGWalker를 사용하여 Netflix 데이터 시각화하기
이제 재미있는 부분인 시각화를 위해 PyGWalker를 사용합니다. PyGWalker를 사용하여 데이터셋에서 통찰력을 얻기 위해 상호작용 가능한 시각화를 생성할 것입니다.
1. Netflix 데이터의 전반적인 개요
여기에서는 주요 데이터셋을 위한 walker를 초기화합니다. 이를 통해 "0.json"에 저장된 사양을 기반으로 일련의 차트를 생성할 수 있게 됩니다.
walker0 = pyg.walk(df, spec="0.json", use_preview=True)
PyGWalker의 온라인 버전을 사용하여 이 데이터셋을 상호작용식으로 탐색할 수 있습니다. 여기에서 (opens in a new tab) 확인해보세요.
walker0.display_chart("Chart 1", title="Netflix 콘텐츠 유형")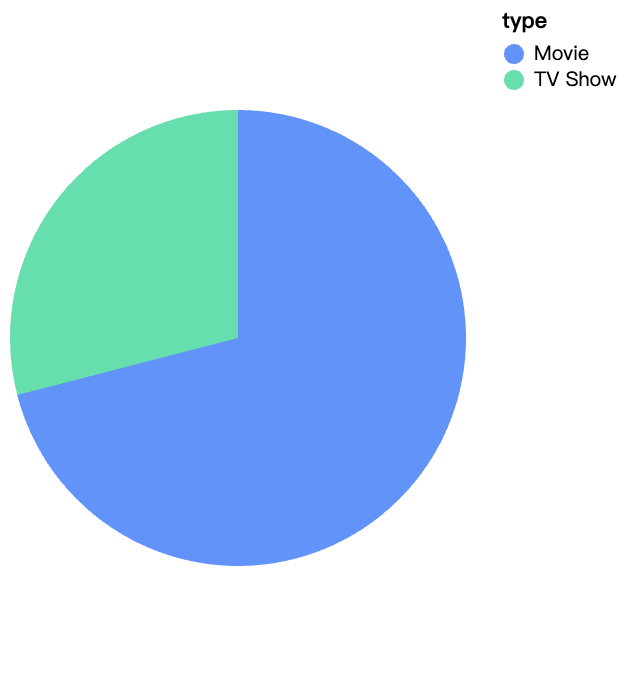
walker0.display_chart("Chart 2", title="연도별 추가된 콘텐츠", desc="Netflix의 영화 수는 TV 쇼보다 훨씬 빠르게 증가하며, 2016년 이후로 영화 콘텐츠가 크게 증가했습니다.")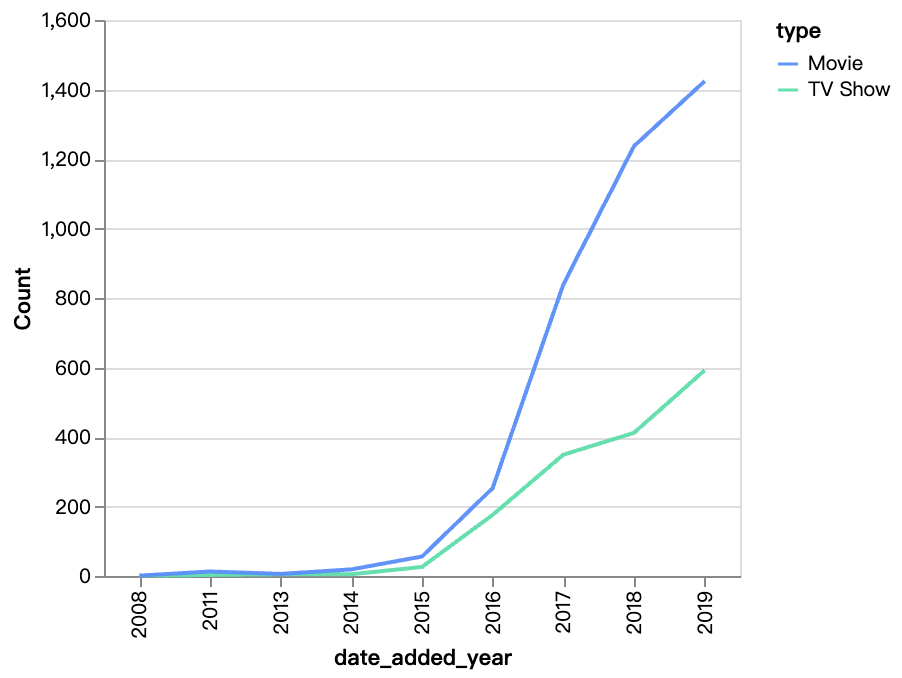
walker0.display_chart("Chart 3", title="연도별 출시된 콘텐츠")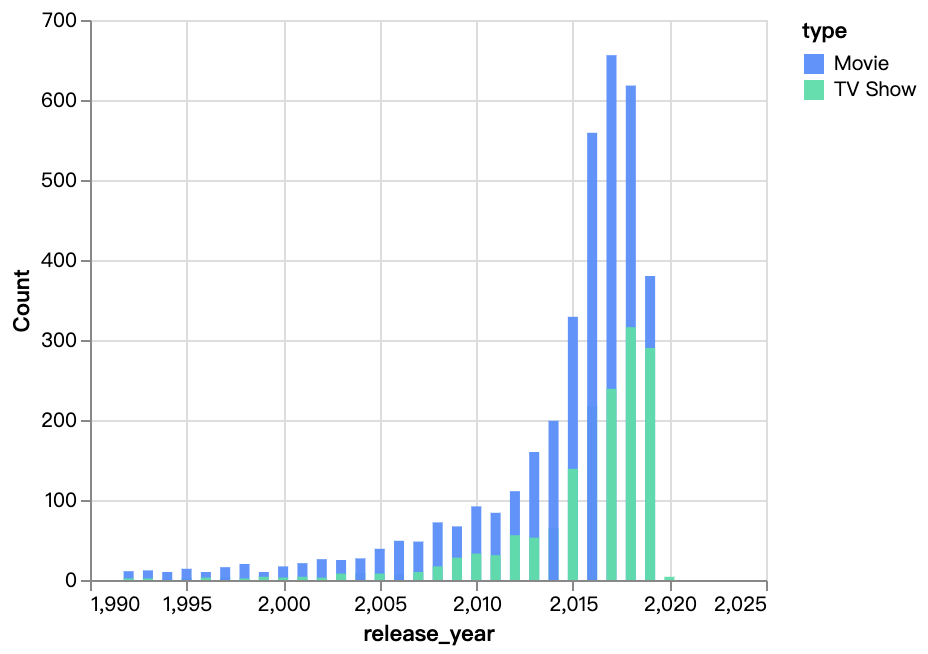
walker0.display_chart("Chart 4", title="월별 추가된 콘텐츠", desc="")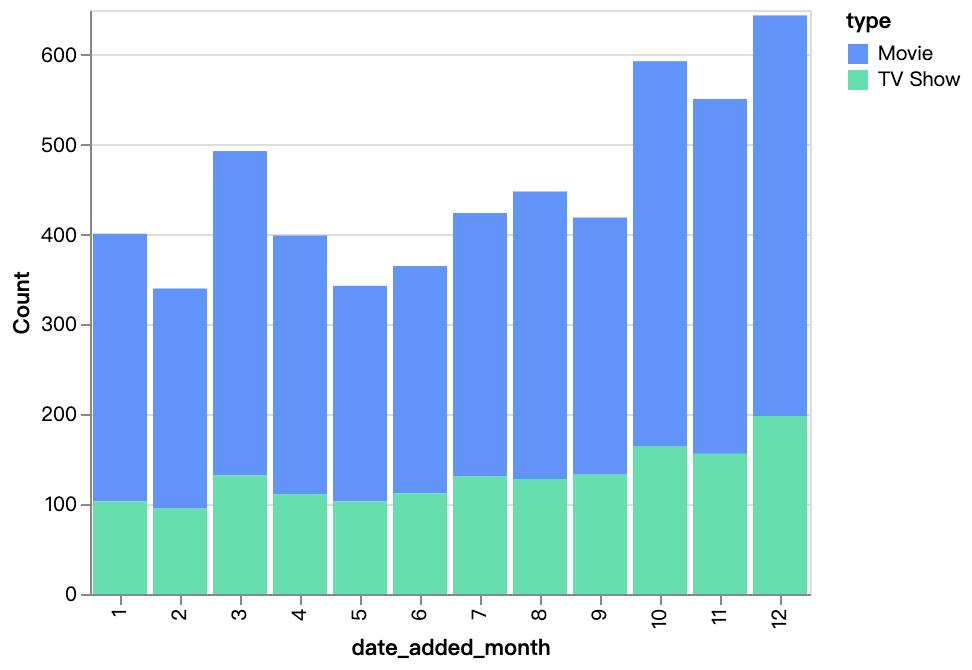
walker0.display_chart("Chart 5", title="등급별로 연도별 추가된 콘텐츠", desc="TV-MA, TV-14가 Netflix의 대부분 콘텐츠 등급이며, R 등급 컨텐츠도 연도별로 증가하고 있습니다.")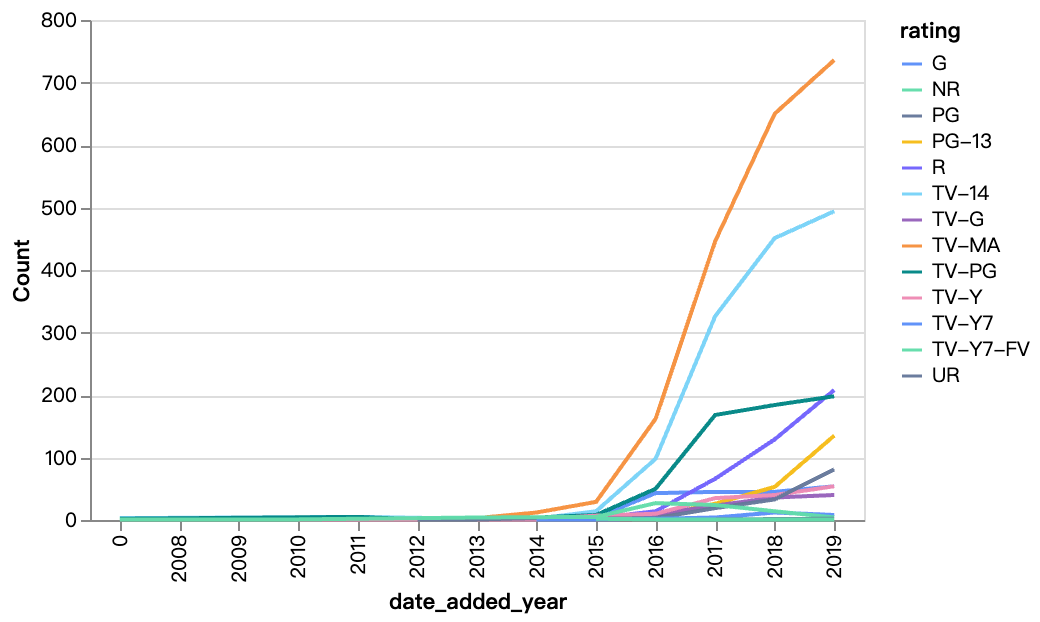
walker0.display_chart("Chart 6", title="영화 시간 분포", desc="주로 90분과 110분 사이에 집중되어 있습니다.")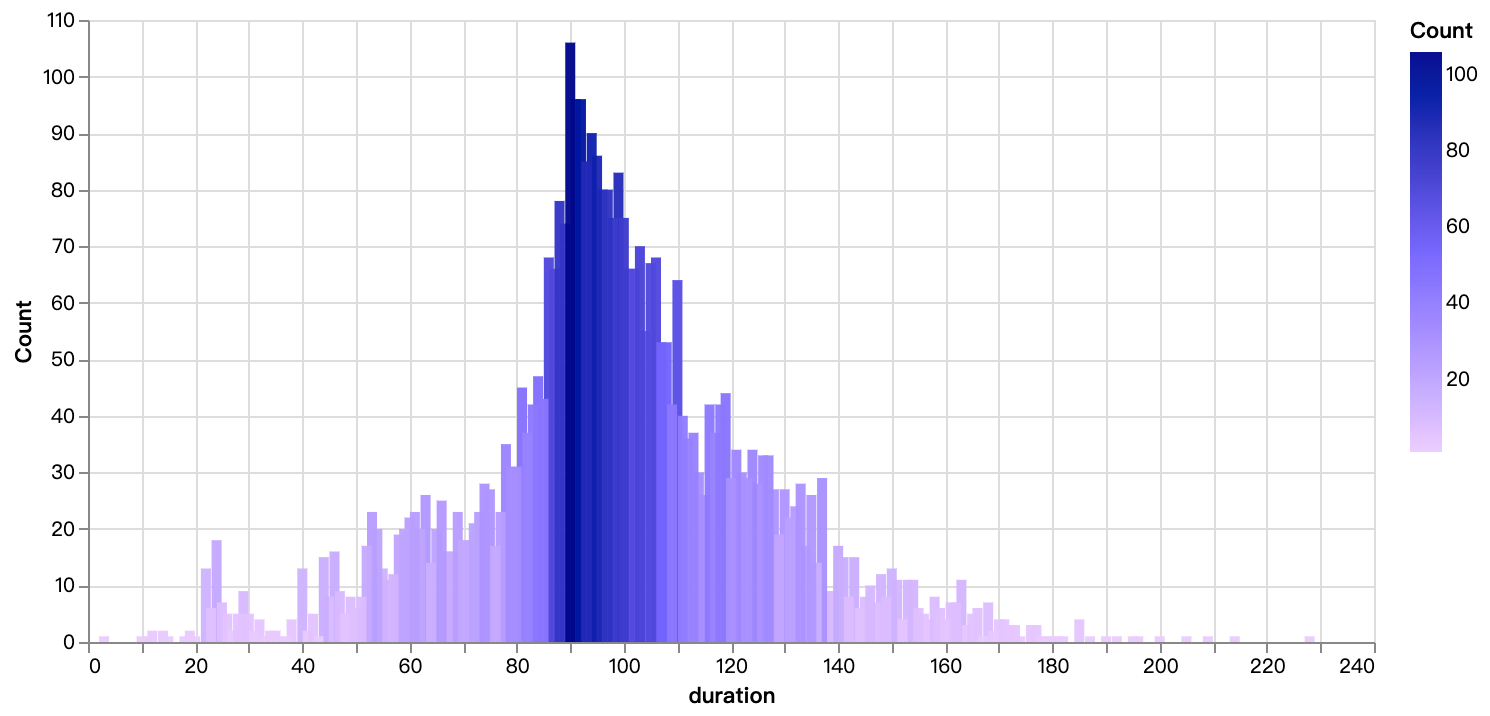
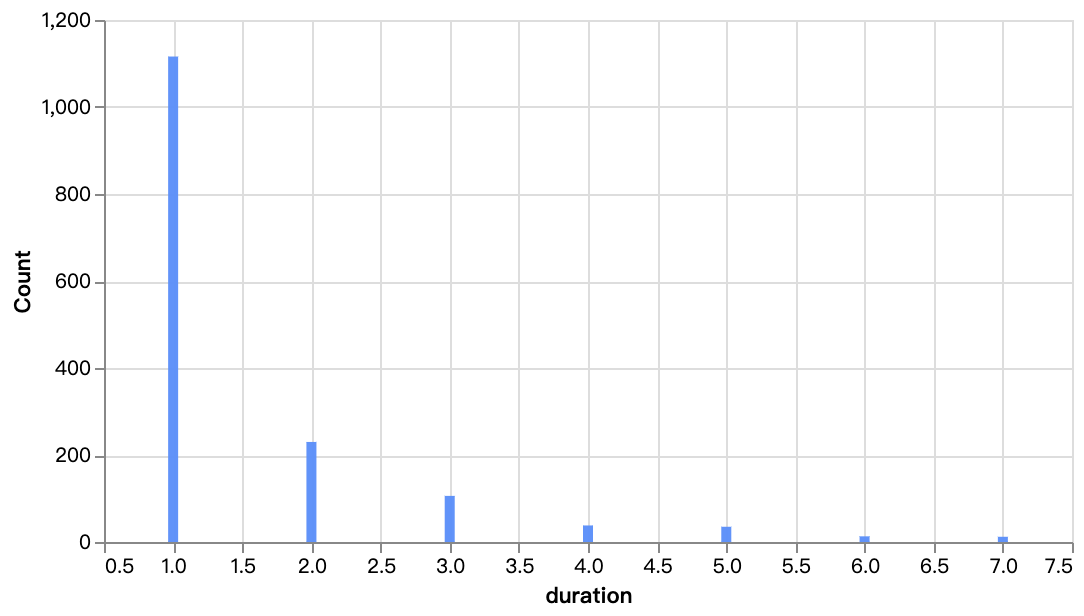
walker0.display_chart("Chart 7", title="TV 쇼 시즌 분포")
2. Netflix 데이터의 국가별 분석
이 세그먼트에서는 국가별 콘텐츠를 쪼개서 분석합니다. 국가 열을 분할하고 재구성하여 다른 국가 간의 콘텐츠 분포를 분석할 수 있습니다.
country_df = df["country"].str.split(",", expand=True).stack().reset_index(level=1, drop=True).to_frame('country')
country_df["country"] = country_df["country"].str.strip()
walker1 = pyg.walk(country_df, spec="1.json", use_preview=True)여기 (opens in a new tab)에서 PyGWalker 사용자 인터페이스로 실시간 시도해 볼 수 있습니다.
walker1.display_chart("차트 1", title="대부분 콘텐츠의 국가")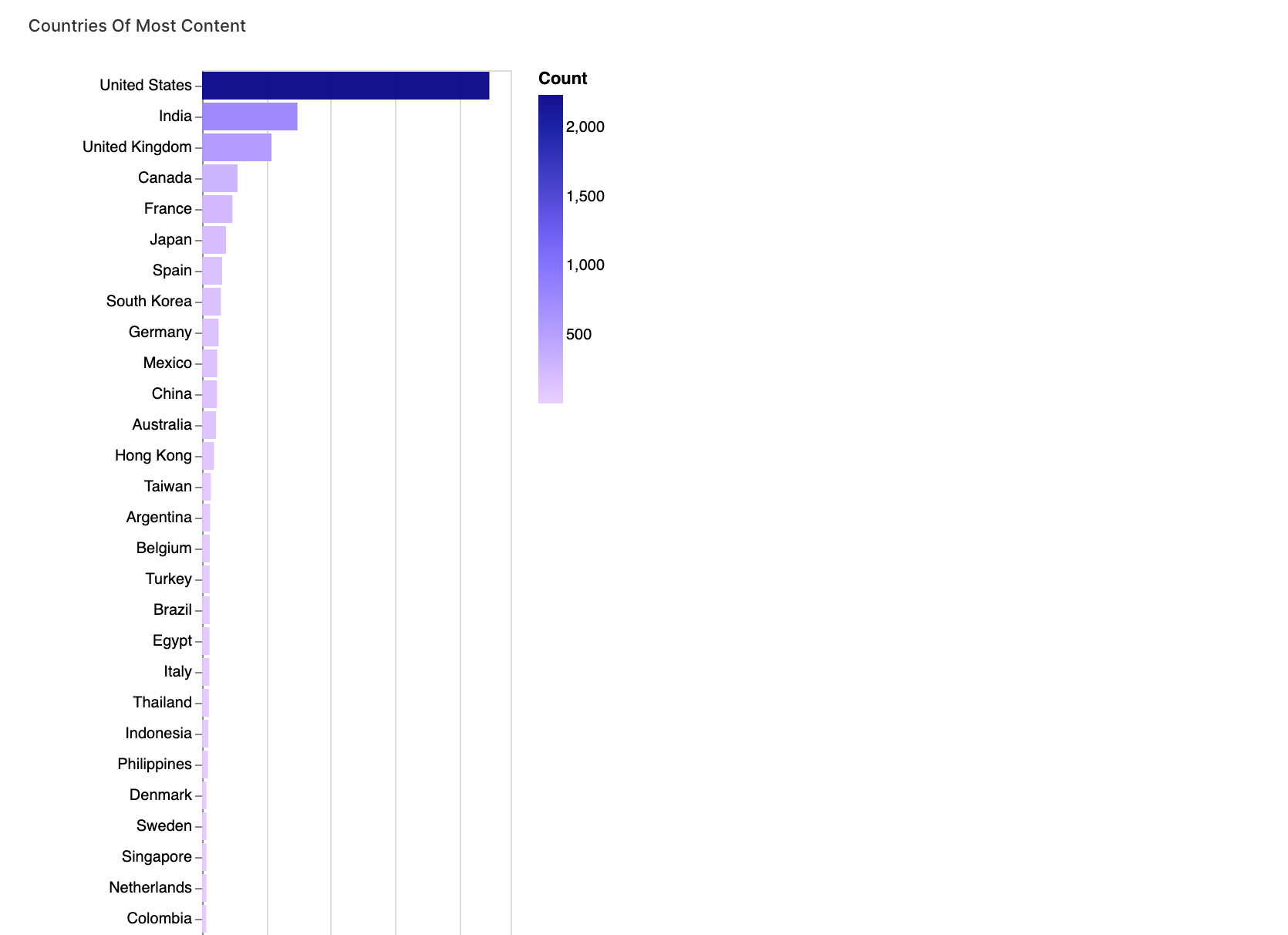
3. 카테고리 및 등급 분석
마지막으로, 카테고리와 등급에 초점을 맞춥니다. 이 섹션에서는 장르별 콘텐츠 분포와 해당 장르 내에서 등급이 어떻게 다른지를 이해할 수 있습니다.
category_df = df.loc[:, ("listed_in", "rating", "type")]
category_df["category"] = category_df["listed_in"].str.split(",")
category_df = category_df[["category", "rating", "type"]]
category_df = category_df.explode("category").reset_index(drop=True)
walker2 = pyg.walk(category_df, spec="2.json", use_preview=True)여기 (opens in a new tab)에서 PyGWalker 사용자 인터페이스로 실시간 시도해 볼 수 있습니다.
walker2.display_chart("TV 카테고리", title="TV 쇼 카테고리 분포")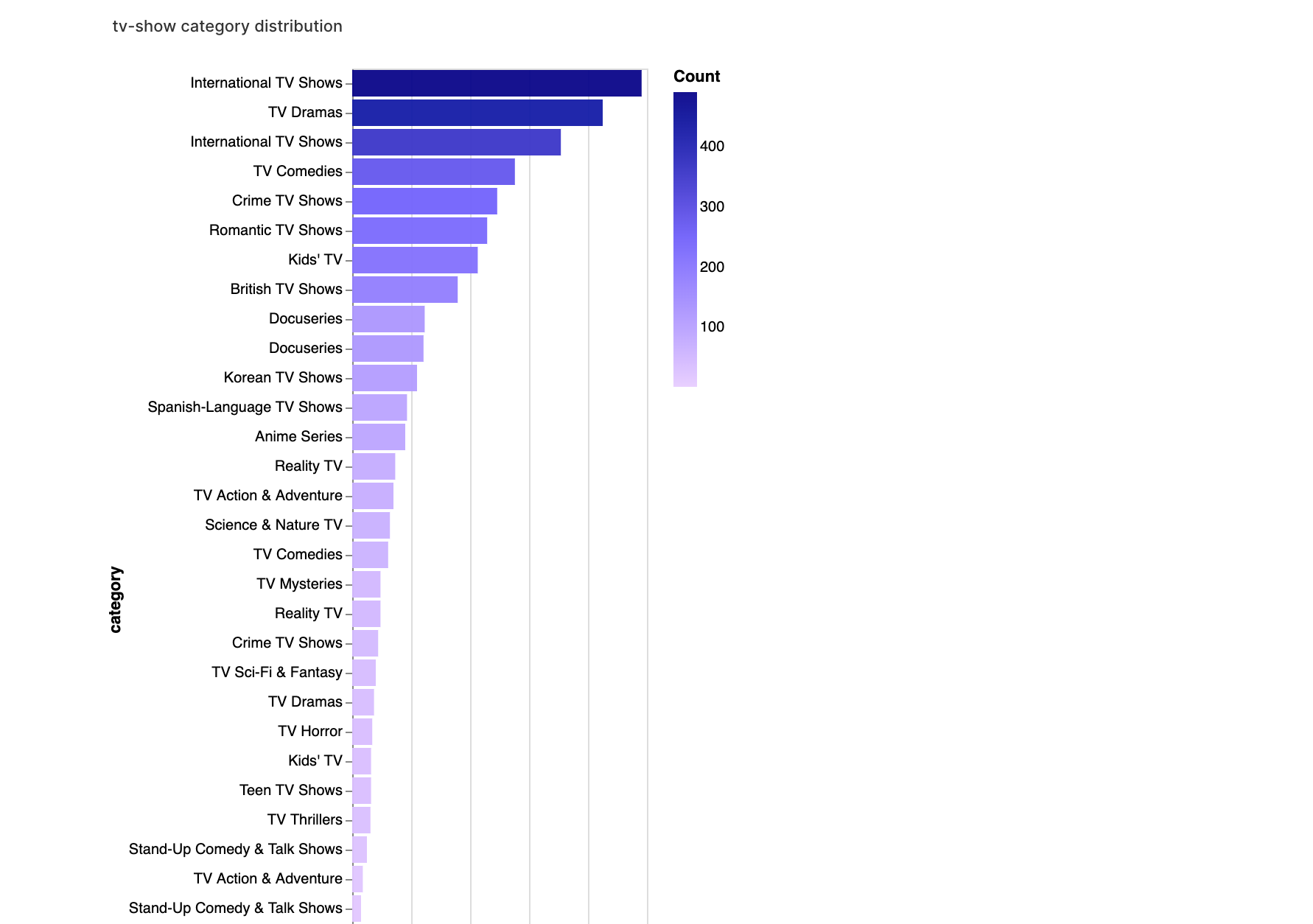
walker2.display_chart("영화 카테고리", title="영화 카테고리 분포")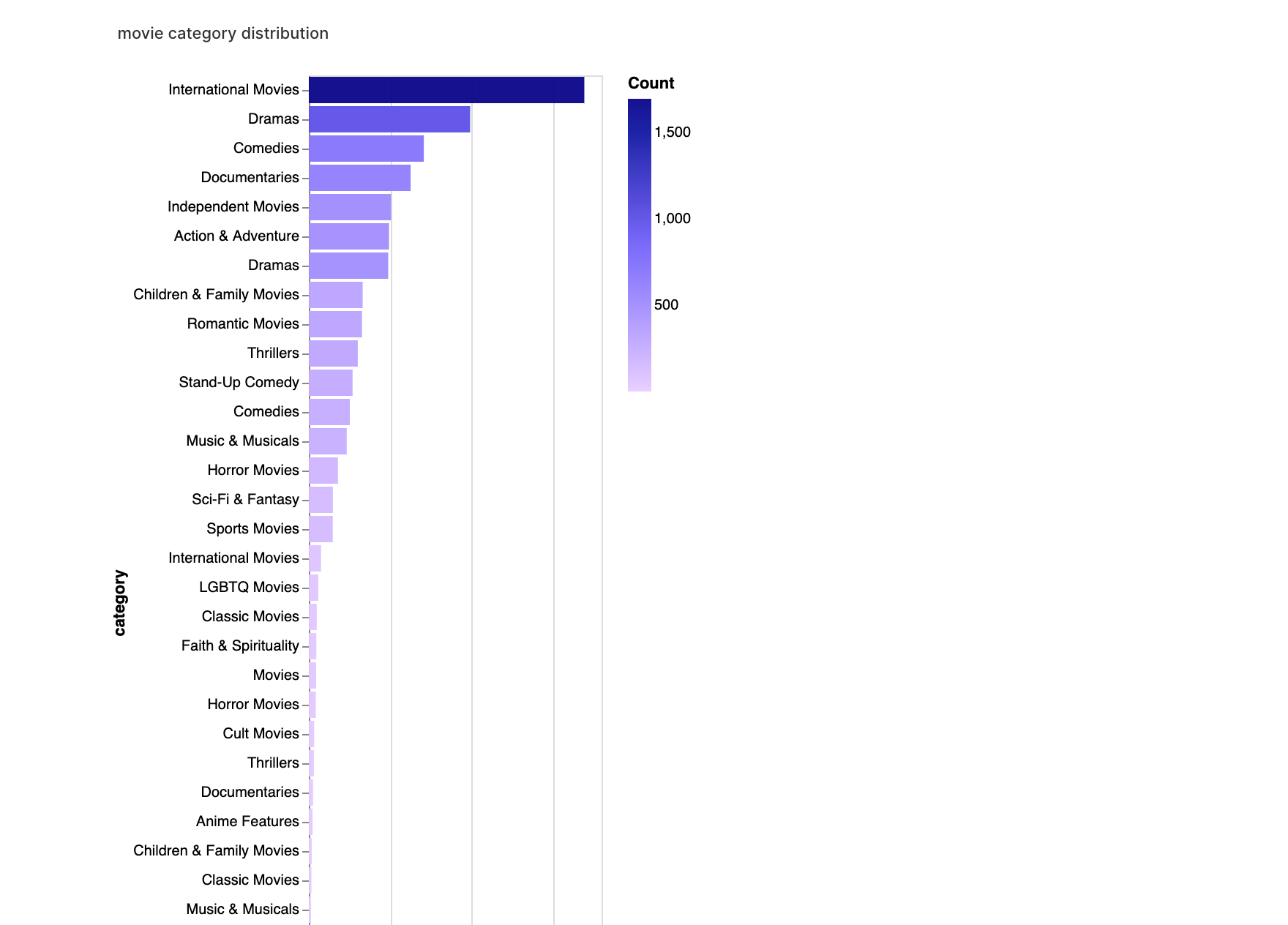
walker2.display_chart("등급 카테고리(tv)", title="등급 카테고리 히트맵(TV 쇼)")
walker2.display_chart("등급 카테고리(영화)", title="등급 카테고리 히트맵(영화)")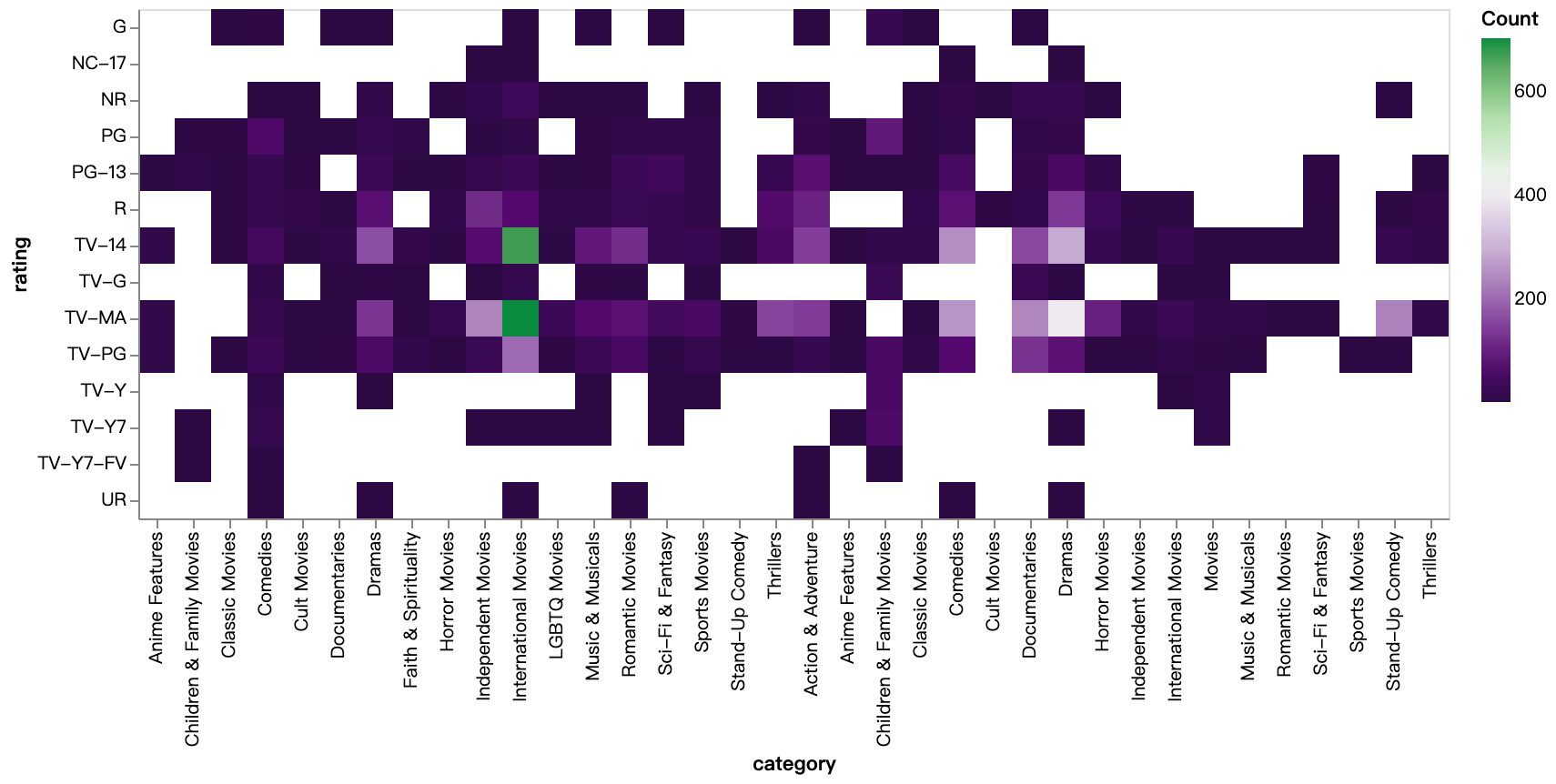
결론
PyGWalker 라이브러리를 사용하여 Netflix 데이터셋의 포괄적인 탐색에서 우리는 Netflix 콘텐츠 랜드스케이프의 다양한 측면에 대해 깊이 파고들었습니다. PyGWalker는 시각화 과정을 단순화하여 핵심적인 동향을 드러낼 수 있는 강력한 도구로 증명되었습니다. 국가 및 등급에 대한 분석을 통해 영화와 TV 쇼 간 장르의 다양성과 분포, 그리고 해당 장르 내에서 등급이 어떻게 다른지가 명확히 밝혀졌습니다.
이 문서는 Kaggle 노트북 (opens in a new tab)에서도 확인할 수 있습니다.
FAQs
1. Netflix 데이터셋이란 무엇인가요?
- Netflix 데이터셋은 Netflix 플랫폼에서 제공되는 콘텐츠에 대한 자세한 정보를 제공하는 데이터의 모음입니다. 이 데이터에는 일반적으로 콘텐츠 유형(영화 또는 TV 쇼), 제목, 감독, 출연진, 제작 국가, Netflix에 추가된 날짜, 출시 연도, 등급, 기간, 장르 및 간단한 설명과 같은 측면이 포함됩니다. 이 데이터셋은 연구원과 분석가들이 플랫폼의 콘텐츠 랜드스케이프를 더 잘 이해할 수 있도록 도와줍니다.
2. Netflix 데이터셋은 어떻게 사용할 수 있나요?
- Netflix 데이터셋은 다양한 방식으로 사용할 수 있습니다:
- 동향 분석: 연도별 성장 패턴, 선호도, 동향을 이해합니다.
- 국가 분석: 어떤 국가에서 가장 많은 콘텐츠를 생산하고 다른 지역에서 어떤 유형의 콘텐츠가 인기있는지를 판정합니다.
- 장르 분배: 가장 인기 있는 장르와 영화와 TV 쇼 사이의 차이를 탐색합니다.
- 등급 인사이트: 다양한 콘텐츠 유형별 등급 분포를 분석하고 관객 선호도를 판정합니다.
- 데이터 시각화: PyGWalker와 같은 도구를 사용하여 더 깊은 통찰력을 위해 대화형 시각화를 생성합니다.
3. PyGWalker는 무엇이며 데이터 탐색에 어떤 이점이 있나요?
- PyGWalker는 데이터 시각화 과정을 간소화하기 위해 특별히 설계된 Python 라이브러리입니다. 사용자는 최소한의 코드로 대화형 차트를 생성할 수 있으며, 이를 통해 데이터셋의 패턴과 통찰력을 파악하기 쉽습니다. 플랫폼에는 방대한 데이터셋이 있는 Netflix와 같은 경우, PyGWalker는 데이터 탐색을 단순화하고 이해하기 쉬운 시각화를 생성하는 데 도움이 되는 귀중한 도구가 될 수 있습니다.