인과 분석
RATH는 데이터에서 인과 관계를 찾고 탐색하기 위한 시각적 노코드 워크플로우를 제공합니다. 단순 상관관계에서 멈추지 않고, 잠재적 원인을 발견하고, 가설을 검증하며, 더 나은 머신러닝 모델을 구축할 수 있도록 인터랙티브 인과 그래프를 기반으로 작업할 수 있습니다.
이 가이드에서 다루는 내용:
- 인과 분석이 무엇이며 언제 활용해야 하는지 이해합니다.
- RATH에서 인과 분석을 수행하는 단계별 워크플로우를 익힙니다.
- Kaggle의 “Diabetes” 데이터셋을 사용하는 구체적인 예제를 따라가 봅니다.
- 비교 분석, 상호 검증, 예측 테스트, 수동 인과 모델 편집과 같은 고급 도구를 살펴봅니다.
인과 분석이란?
인과 분석은 변수들 간의 관계를 살펴보며, 한 변수의 변화가 다른 변수의 변화를 야기(cause) 하는지 — 단순히 함께 움직이는지(상관관계) 여부를 넘어 —를 탐색하는 과정입니다.
실무에서는 보통 다음을 의미합니다:
- 관심 있는 결과 변수에 영향을 줄 수 있는 변수를 식별합니다.
- 가정이나 학습된 관계를 인코딩한 인과 모델(보통 방향 그래프)을 구축합니다.
- 통계 및 알고리즘 기법을 통해 효과의 강도와 방향을 추정합니다.
- 단순 상관관계나 피처 중요도에 의존하는 대신, 가설을 테스트하고 정교화합니다.
대부분의 실제 데이터는 관찰 데이터(통제된 실험이 아닌 방식으로 수집)이기 때문에, 인과 분석이 “절대적인 참 인과”를 보장하지는 않습니다. 하지만, 단순 상관관계만 볼 때보다 훨씬 강하고 해석 가능한 가설을 생성하고 검증하는 데 도움이 됩니다.
RATH에서 인과 분석 수행 방법
RATH는 복잡한 인과 발견 기법을 인터랙티브 워크플로우로 감쌉니다. 전체적인 흐름은 다음과 같습니다:
-
데이터 연결 및 준비
- 데이터셋을 RATH에 가져옵니다.
- 잘못된 레코드를 정제하고, 주요 필드의 타입(수치, 범주형 등)을 올바르게 지정합니다.
-
필드 및 선택적 종속성 설정
- 인과 모델에 포함할 필드를 선택합니다.
- 선택적으로, 알려진 함수적 종속성(예: 파생 필드, 수식)을 선언하여, RATH가 인과 발견 시 이를 고려하도록 합니다.
-
인과 발견 실행
- Causal Analysis 워크플로우를 시작하고, RATH가 데이터로부터 인과 그래프를 추론하도록 합니다.
-
관계 탐색 및 검증
- Field Insights, Manual Exploration, Mutual Inspection 등의 도구를 사용해, 발견된 모델을 도메인 지식과 비교하며 검증하고 다듬습니다.
-
예측 모델 구축 및 테스트
- Prediction Test를 활용해 인과 그래프 기반 머신러닝 모델을 만들고, 다른 피처 세트와 성능을 비교합니다.
-
인과 모델 편집 및 확정
- 추가적인 도메인 지식이 있거나, 데이터가 노이즈가 크거나, 누락된 요인이 있을 때 모델을 수동으로 조정합니다.
이후 섹션에서는 실제 예제를 통해 이 워크플로우를 단계별로 살펴봅니다.
사례 연구: Kaggle의 "Diabetes Database" 인과 분석
구체적인 예제로, RATH에서 Kaggle의 “Diabetes Database” (opens in a new tab)를 분석해 보겠습니다. 목표는 어떤 요인들이 Outcome(당뇨병 진단)에 가장 큰 영향을 미치며, 서로 어떻게 상호작용하는지 이해하는 것입니다.
데이터 준비 및 정제
- 데이터셋을 RATH에 가져옵니다.
BMI,BloodPressures,SkinThickness값이0인 잘못된 레코드를 제거합니다.
DataSource 탭에서:- Clean Method를 클릭합니다.
- drop null records를 선택해 잘못된 값을 가진 행을 필터링합니다.
데이터 정제가 완료되면, Start Analysis 버튼 오른쪽의 드롭다운 메뉴를 열고 Causal Analysis를 선택하여 워크플로우를 시작합니다.
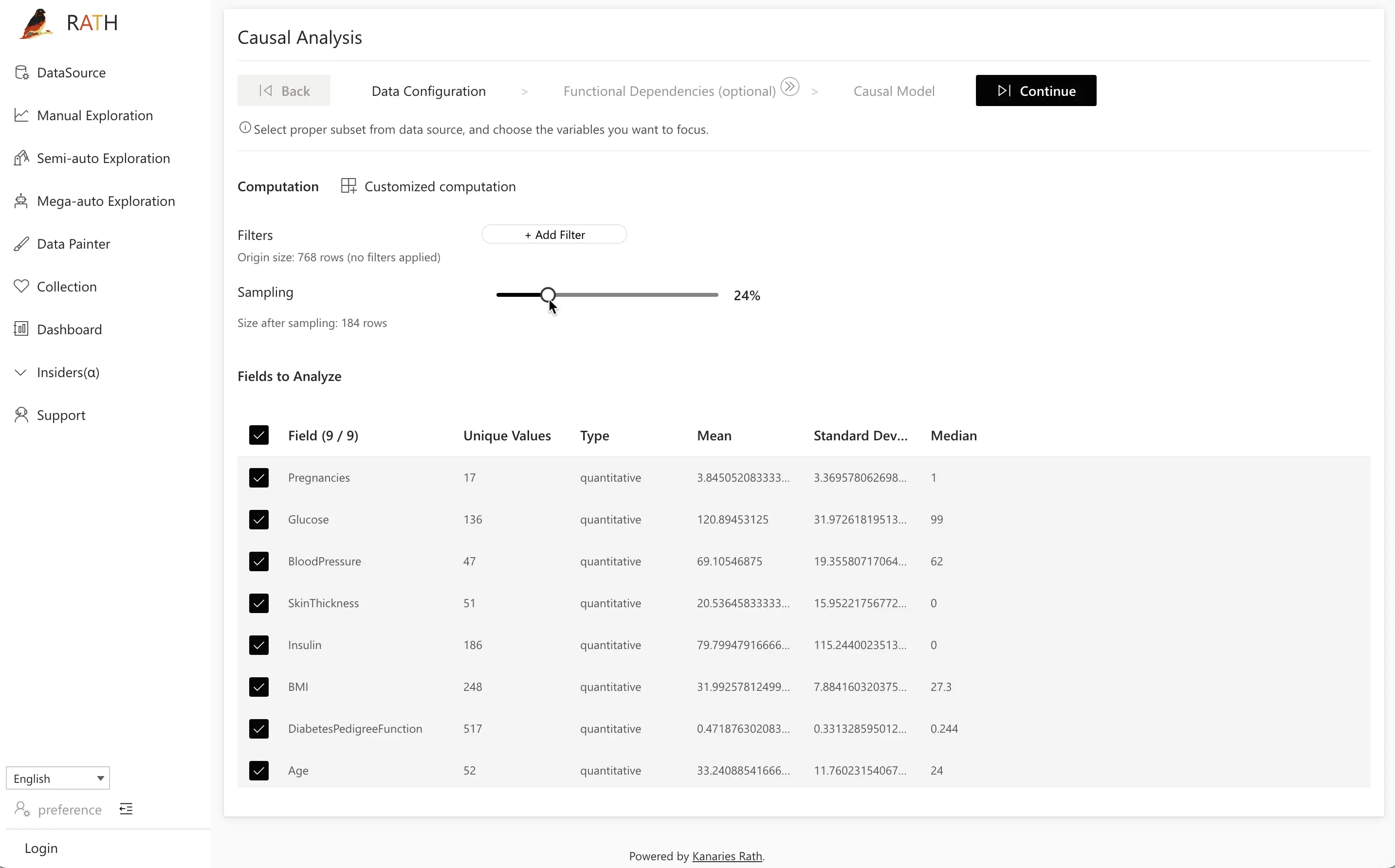
Step 1: Data Configuration
Data Configuration 단계에서는 인과 분석에 포함할 필드를 선택합니다.
- 예를 들어,
Pregnancies,Glucose,BloodPressure,SkinThickness,Insulin,BMI,DiabetesPedigreeFunction,Age,Outcome등을 선택합니다. - 명백히 무관하거나 노이즈가 심한 필드는 제외할 수 있습니다.
선택을 마쳤다면 Next를 클릭하여 다음 단계로 이동합니다.
팁: 초반에는 관련 가능성이 있는 변수들을 모두 포함한 뒤, 인과 모델과 예측 결과를 보면서 점진적으로 정제하는 것이 좋습니다.
Step 2: (선택 사항) Functional Dependencies
많은 데이터셋에서 일부 필드는 다른 필드로부터 파생됩니다(예: 계산된 비율, 포맷팅된 ID, SQL 수식으로 생성된 필드 등). 이러한 관계를 미리 선언해두면, RATH가 잘못된 인과 링크를 학습하는 것을 방지하는 데 도움이 됩니다.
Functional Dependencies 단계에서 할 수 있는 작업:
- RATH가 데이터를 자동으로 분석해 제안하는 종속성을 수락할 수 있습니다.
- 이미 알고 있는 관계를 직접 지정할 수 있습니다(예:
TotalAmount = Quantity × UnitPrice).
RATH는 서로 다른 변수들의 값을 분석해 가능한 함수적 관계를 계산합니다. 사용자는 제안된 종속성을 수락하거나 수정하거나, 직접 추가할 수 있습니다.
베스트 프랙티스:
데이터 일부가 정규식이나 SQL 수식으로 생성된 경우, 여기서 해당 종속성을 선언해 두는 것이 좋습니다. 파생 필드가 RATH 내부에서 생성된 것이라면, 대부분의 경우 RATH가 자동으로 처리하므로 별도의 작업이 필요하지 않습니다.
Step 3: Causal Model
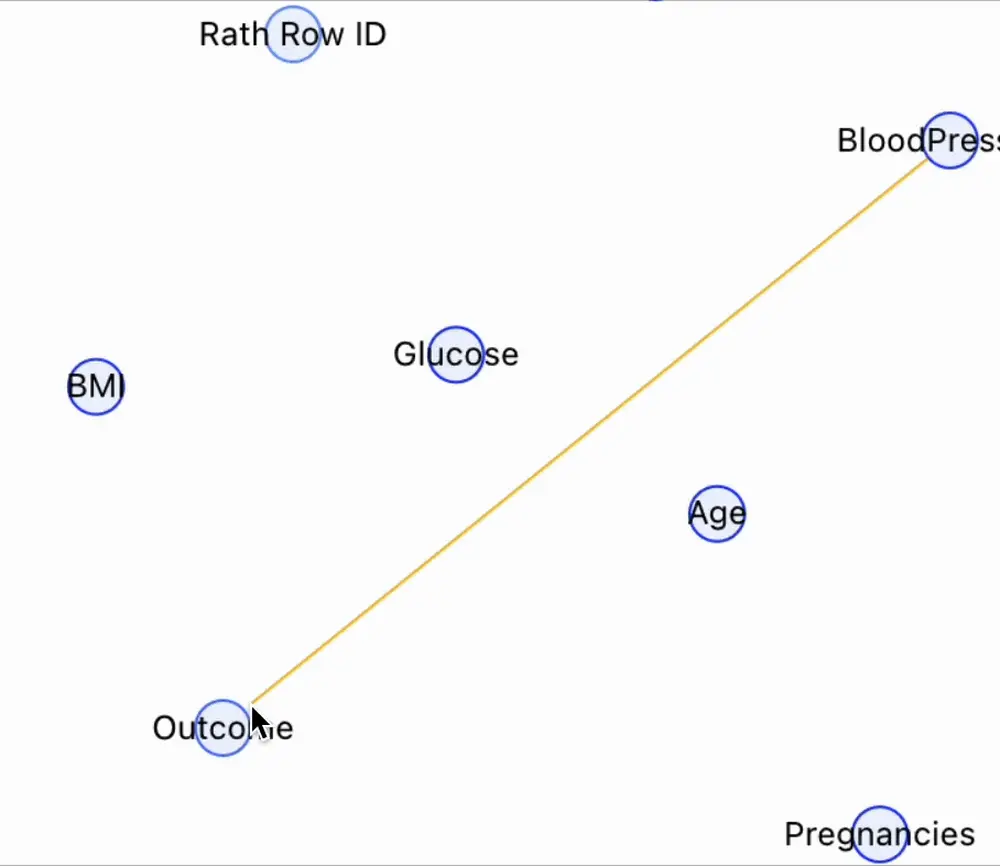
Causal Discovery를 클릭하면, 설정한 필드들을 기반으로 RATH가 인과 모델을 추론합니다.
아래 스크린샷은 당뇨병 데이터셋에 대한 전형적인 인과 발견 결과 예시입니다:
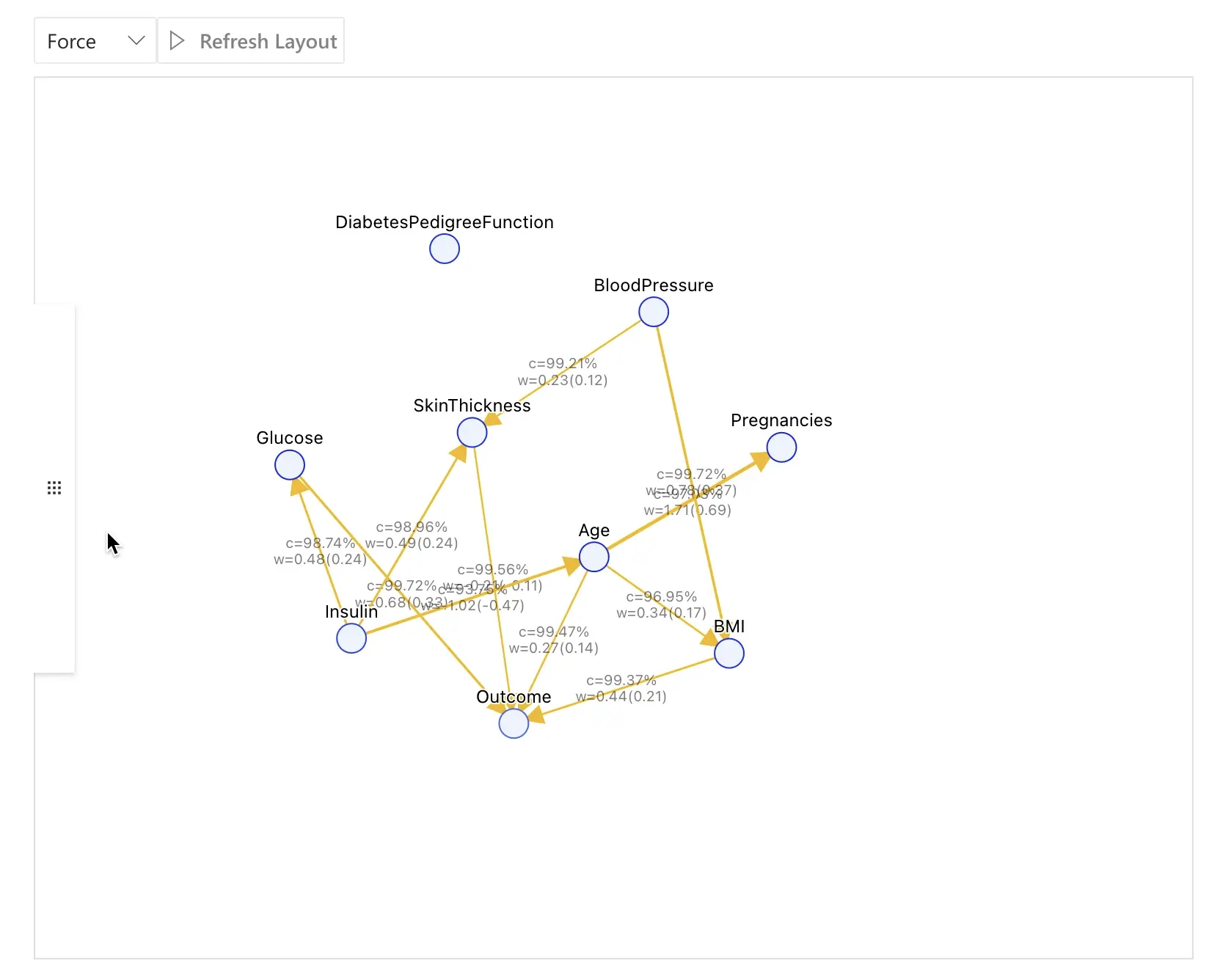
이 예에서 주요 관계는 다음과 같습니다:
Glucose→Outcome
포도당 수치가 높을수록 당뇨병 진단이 양성일 가능성이 증가합니다.Insulin→Glucose→Outcome
인슐린은 포도당에 영향을 주고, 포도당이 다시 당뇨병 결과에 영향을 줍니다.Age→Outcome(관련 건강 요인에 의해 영향을 받기도 함)
나이는 당뇨병 여부에 대한 확률에 기여합니다.
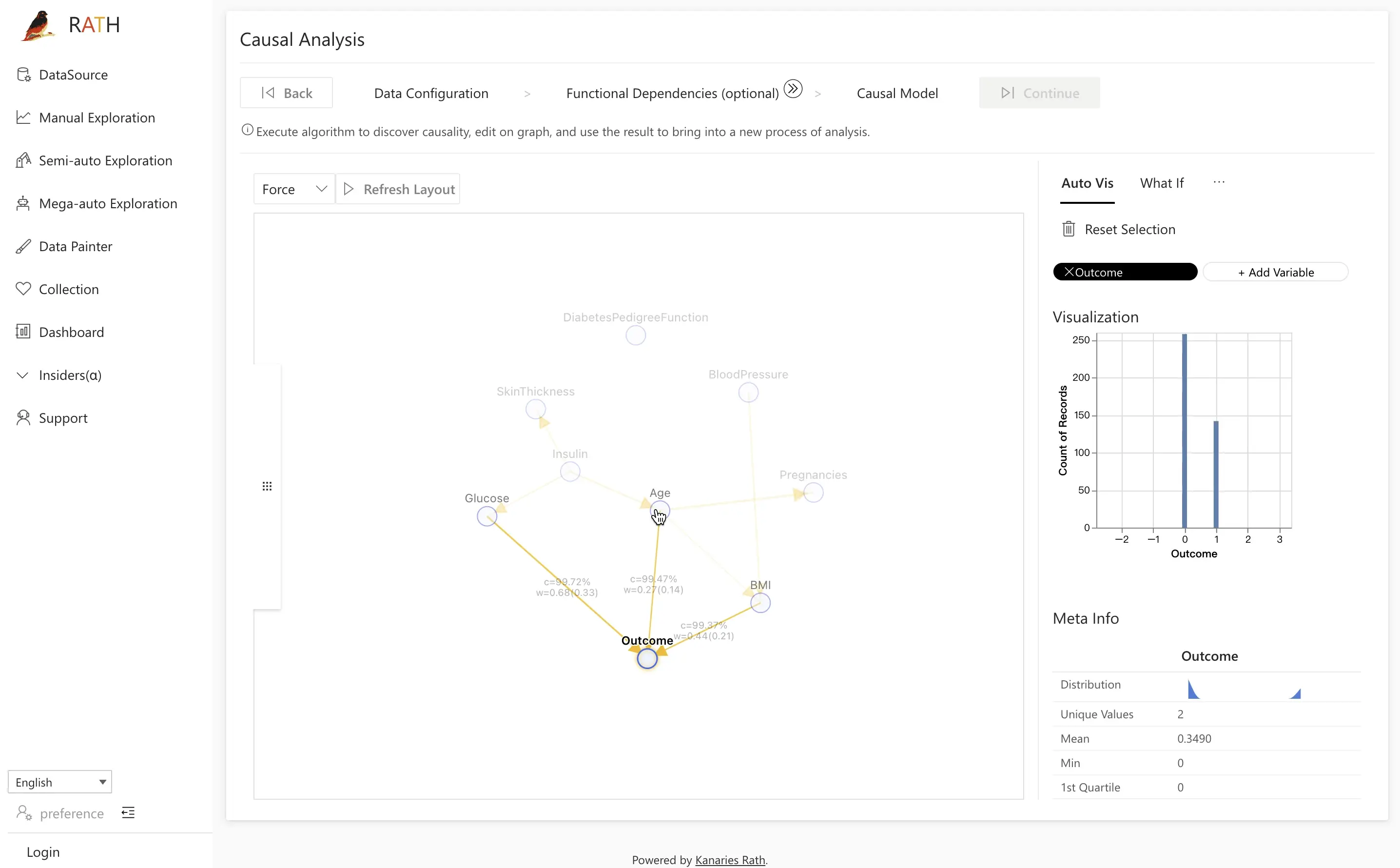
인터랙티브 그래프는 분석의 중심 작업 공간입니다:
- 노드를 클릭하여 해당 변수의 직접적인 원인과 결과를 강조 표시합니다.
- 엣지 두께나 강도 지표를 통해 관계의 강도를 파악합니다.
- 오른쪽 패널에서 선택된 변수에 초점을 맞춘 다양한 도구(Field Insights, Manual Exploration, Mutual Inspection, Prediction Test)를 사용할 수 있습니다.
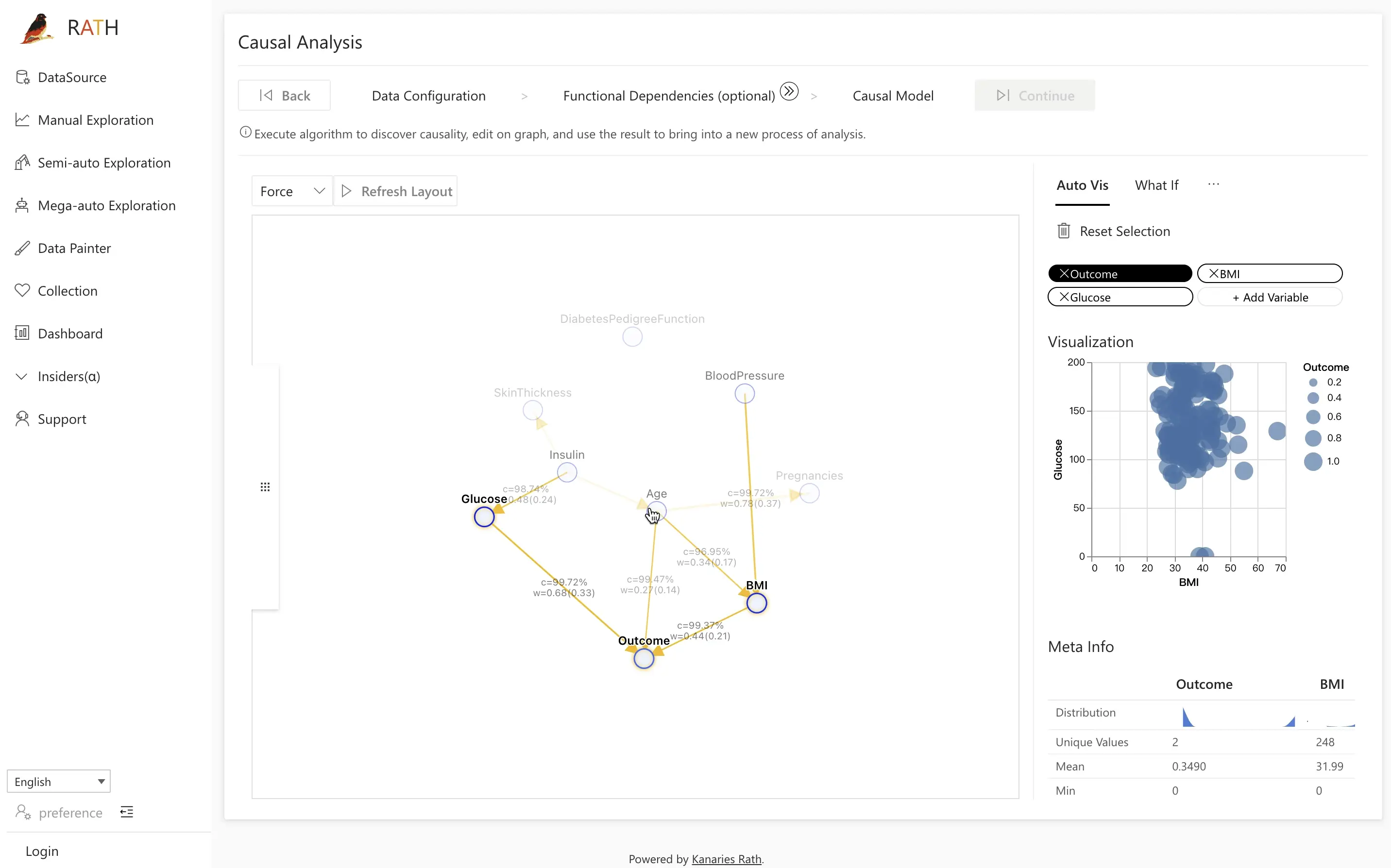
Step 3.1: Field Insights를 활용한 비교 분석
비교 분석(Comparative analysis) 은 두 그룹을 비교하고 — 예를 들어, 당뇨병이 있는 환자와 없는 환자 — 인과 모델을 사용해 그 차이를 설명할 수 있도록 합니다.
RATH는 다음과 같은 여러 비교 모드를 지원합니다:
- Subset vs. Whole
(예: 1월 vs. 전체 연도) - Subset vs. Complement
(1월 vs. “1월을 제외한 나머지 모든 기간”) - Subset vs. Another Subset
(1월 vs. 6월)
이를 활용해 다음과 같은 작업을 수행할 수 있습니다:
- 이상치나 특이 패턴 뒤에 있는 잠재적 인과 요인을 조사합니다.
- 실제 분포를 이용해 인과 가설을 검증·정교화합니다.
예: Outcome 분석
- Field Insight 탭을 엽니다.
- 왼쪽에서
Outcome노드를 클릭합니다. - 오른쪽에서 당뇨병이 있는 사람과 없는 사람의 분포를 확인합니다.
- 하나의 분포(예: 양성 결과)를 클릭해 비교 분석을 실행합니다.
이후, 대조군과 관심 있는 주요 변수(예: Glucose)를 선택한 후 Causal Discovery를 클릭하면, RATH가 잠재적 원인을 분석합니다. RATH는 인과 다이어그램을 이용해 관측된 차이에 대한 설명을 제안합니다.
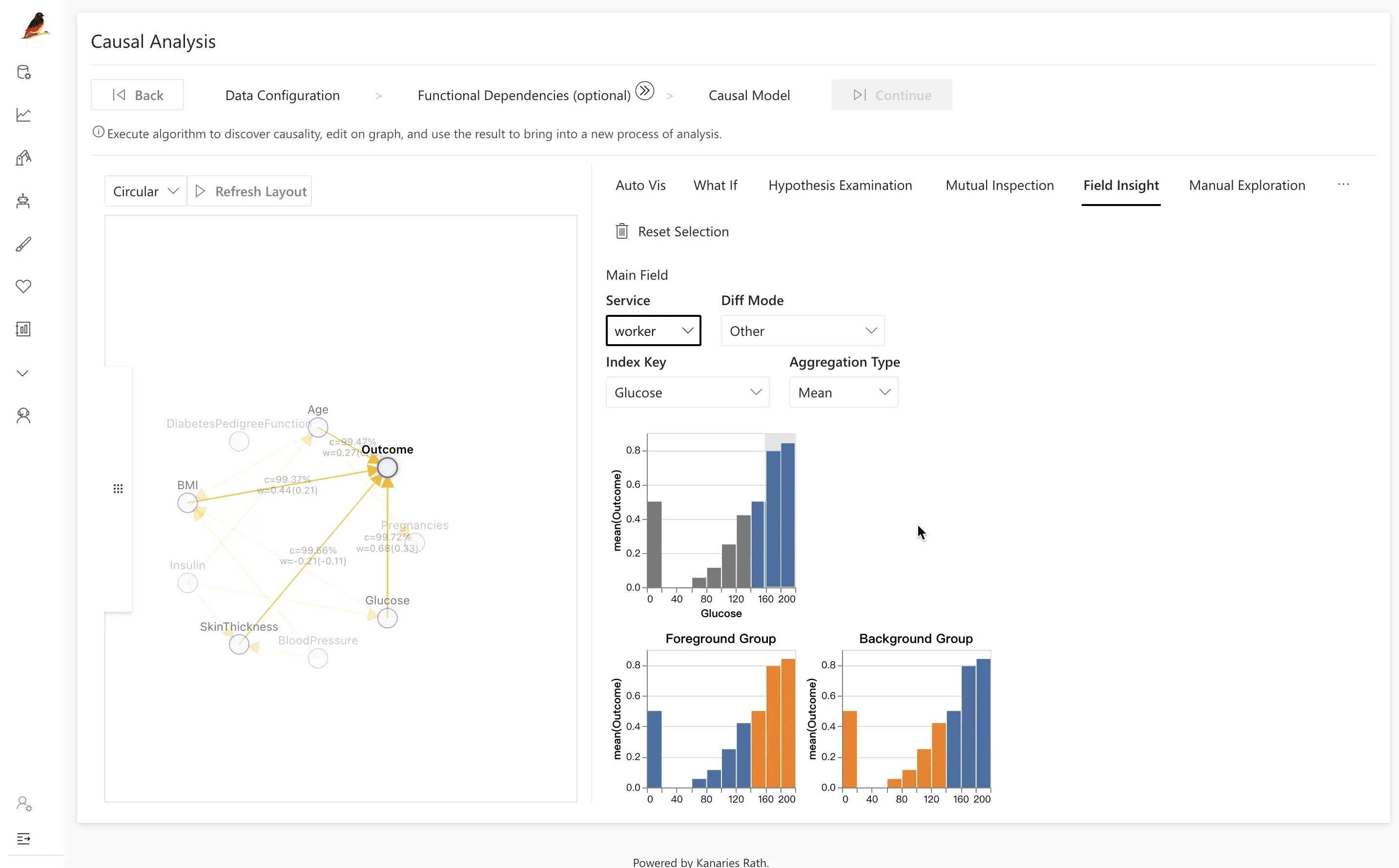
당뇨병 예제에서는, 당뇨병 환자와 비환자 그룹을 비교할 때 주로 다음 변수들이 차이를 이끄는 요인으로 나타납니다:
BMIAgeGlucose
잠재 요인(latent factor)인 Glucose를 클릭하면, 당뇨병 그룹(주황색으로 강조)의 포도당 분포가 비당뇨 그룹보다 유의하게 높다는 것을 확인할 수 있습니다.
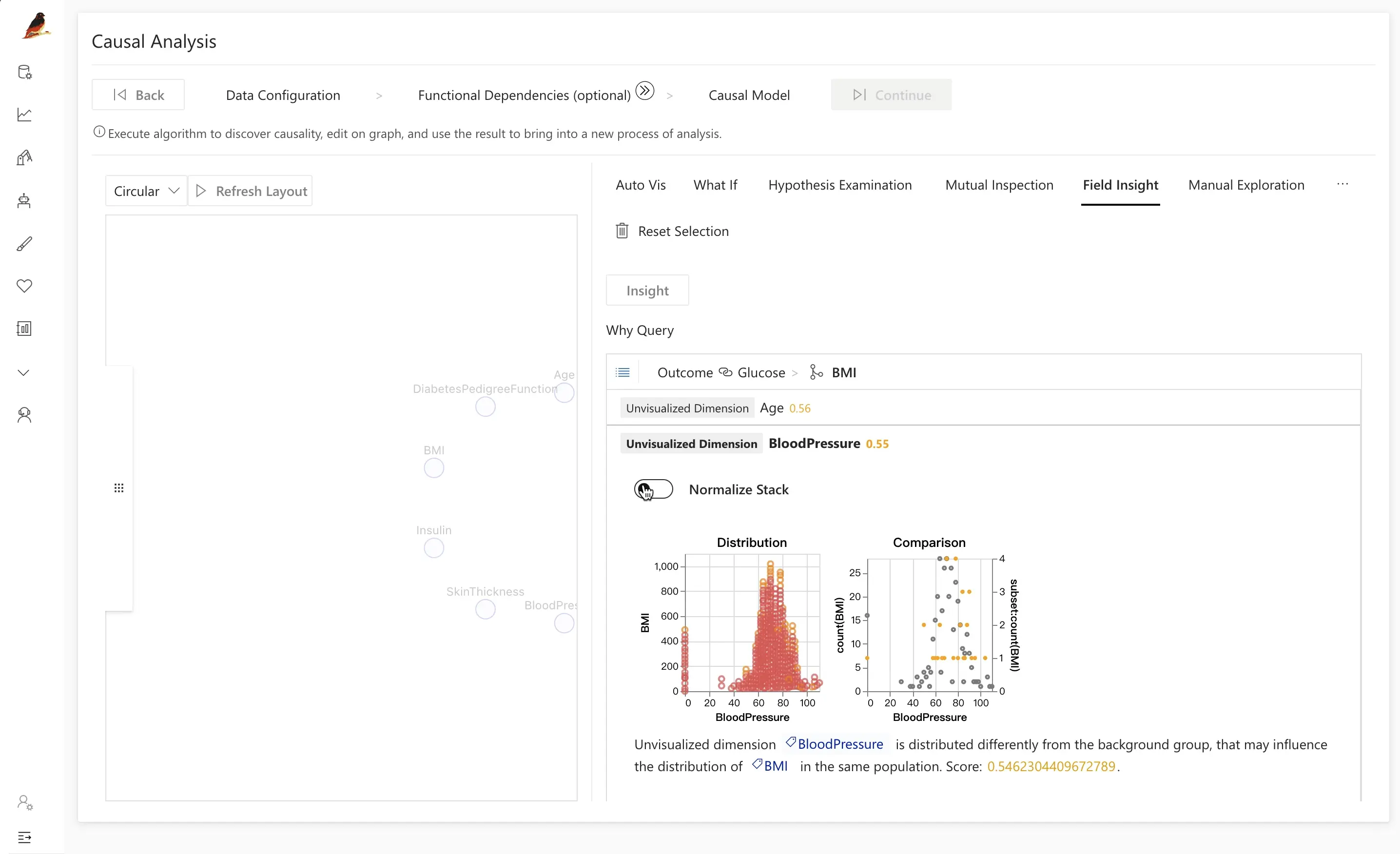
Step 3.2: Manual Exploration
Manual exploration 기능을 사용하면, 특정 인과 가정을 시각적으로 직접 시험해볼 수 있습니다.
당뇨병 데이터셋에서 예를 들어 다음을 확인해 볼 수 있습니다:
Insulin이Outcome의 직접적인 원인인지 여부Insulin을 통제했을 때Glucose와Outcome간 관계가 어떻게 달라지는지
Manual exploration을 활용하면 다음과 같은 작업을 할 수 있습니다:
Outcomevs.Glucose를 그려, 질병 보유 그룹과 건강한 그룹 간 분포를 비교합니다.- 조건부 변수로
Insulin을 추가하여(예: 인슐린 수치 구간으로 데이터를 나누어) 관계를 세분화해 살펴봅니다.
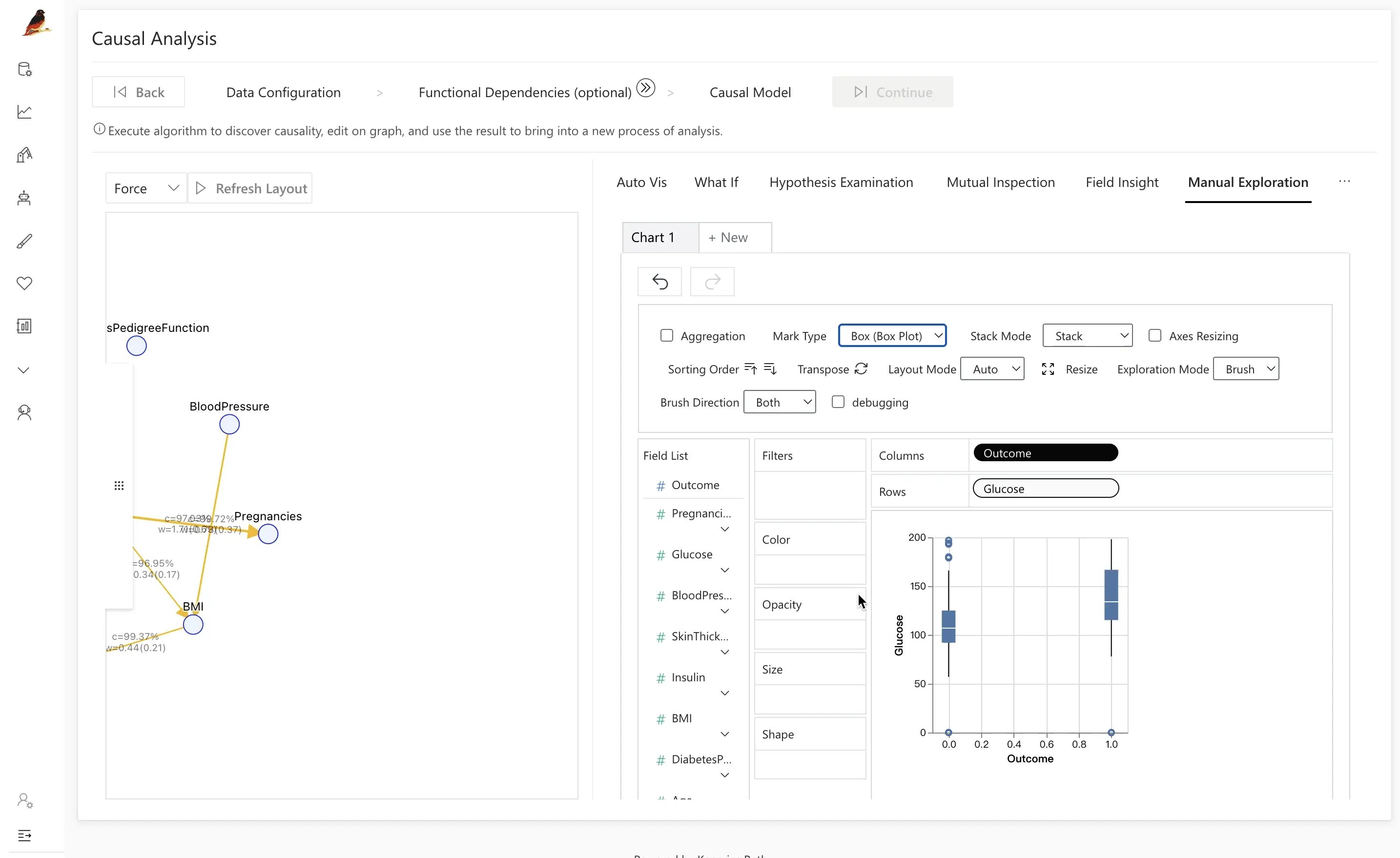
전통적인 분석은 상관관계나 피처 중요도에서 멈추는 경우가 많아, 특정 변수가 어떻게 영향을 미치는지까지는 잘 드러내지 못합니다. RATH의 Causal Analysis를 활용하면, 이런 작동 메커니즘을 파악하고 겉보기 효과가 실제로는 다른 변수에 의해 설명되는 부분인지 파악할 수 있습니다.
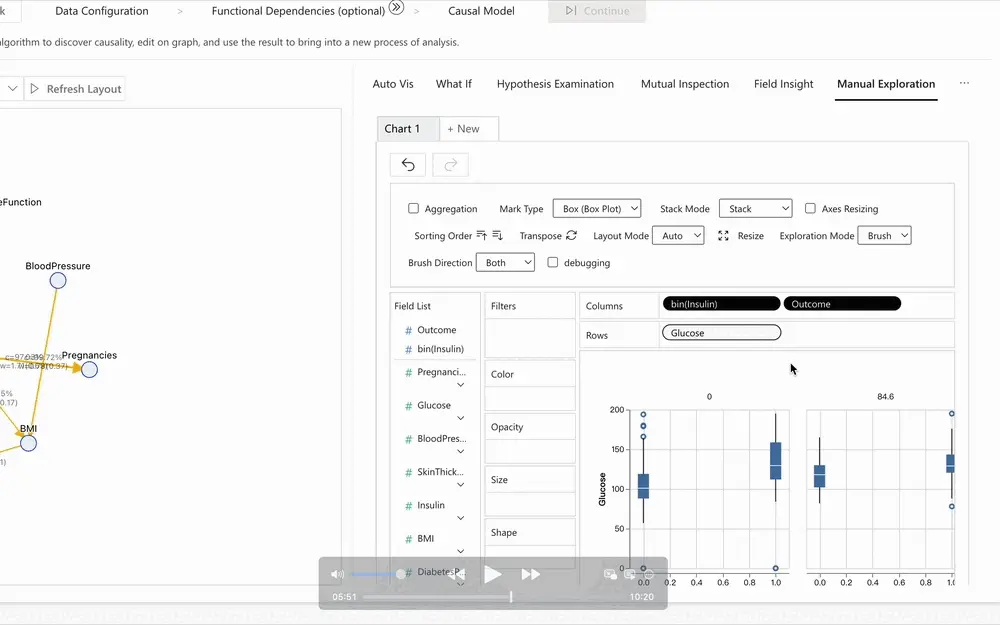
예를 들어, Outcome과 Glucose 사이에 Insulin을 도입한 후:
- 서로 다른
Insulin구간으로 통제하면, 질병 그룹과 건강 그룹 간 인슐린 차이가 사라질 수 있습니다. - 이는,
Insulin의 영향을 고려했을 때Outcome과Glucose사이의 직접적인 관계가 처음 보았던 것보다 약해진다는 것을 시사합니다.
Step 3.3: Mutual Inspection
Mutual Inspection 도구는 인과 관계를 점검하고 가정을 검증하는 또 다른 방식입니다.
동작 방식:
- 인과 그래프에서 노드를 클릭해, 해당 변수의 분포를 오른쪽 검증 모듈에 추가합니다.
- 예를 들어,
Glucose와Outcome의 관계를 탐색하려면 두 변수를 모두 추가합니다. Glucose범위를 선택한 뒤 드래그하면서,Outcome분포가 어떻게 변하는지 관찰합니다.
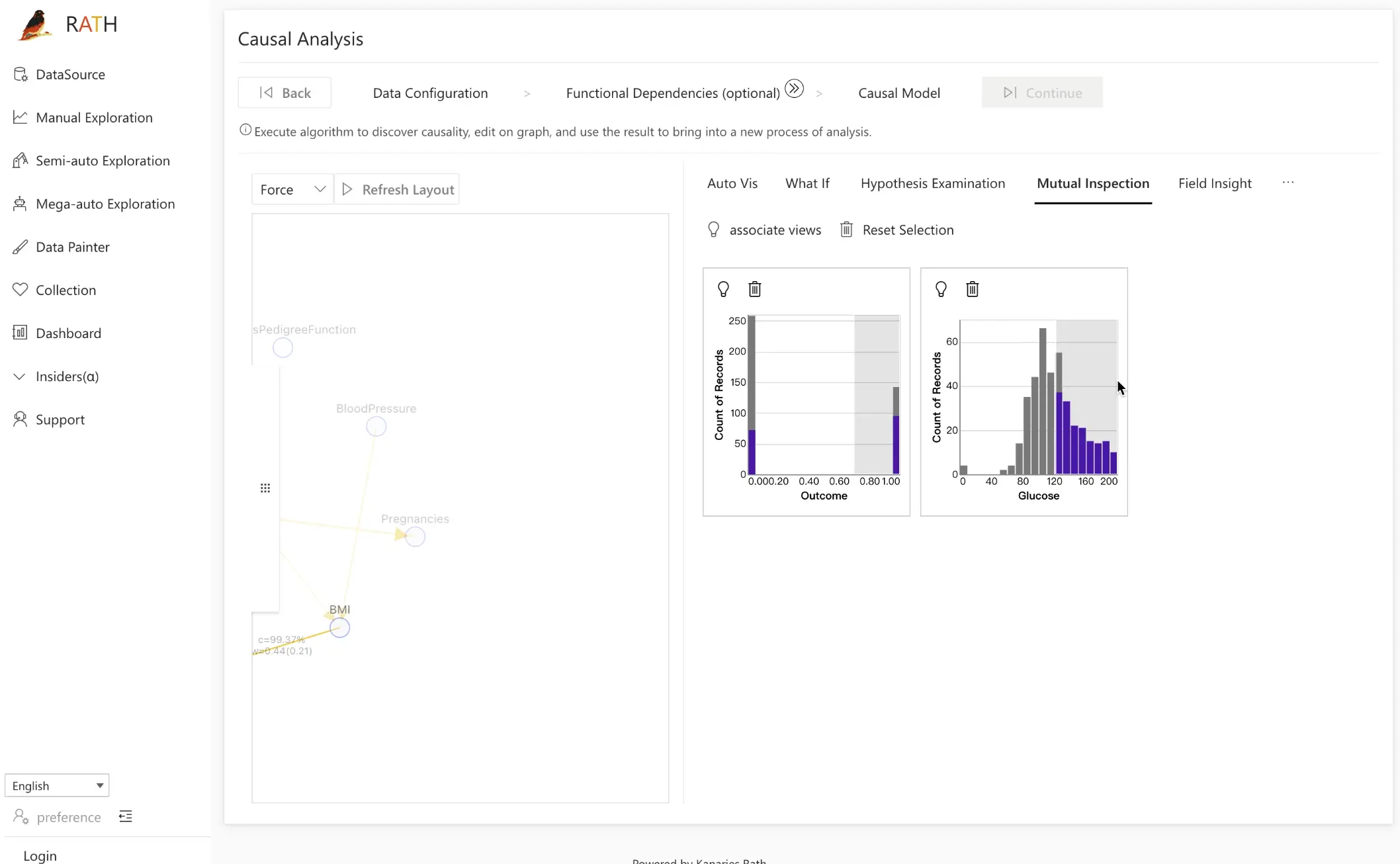
이처럼 포도당 수치 범위를 이동해 가며 결과 분포 변화를 살펴보면, 데이터 전반에서 양의 상관관계가 어느 정도 강도로 유지되는지 시각적으로 확인할 수 있습니다.
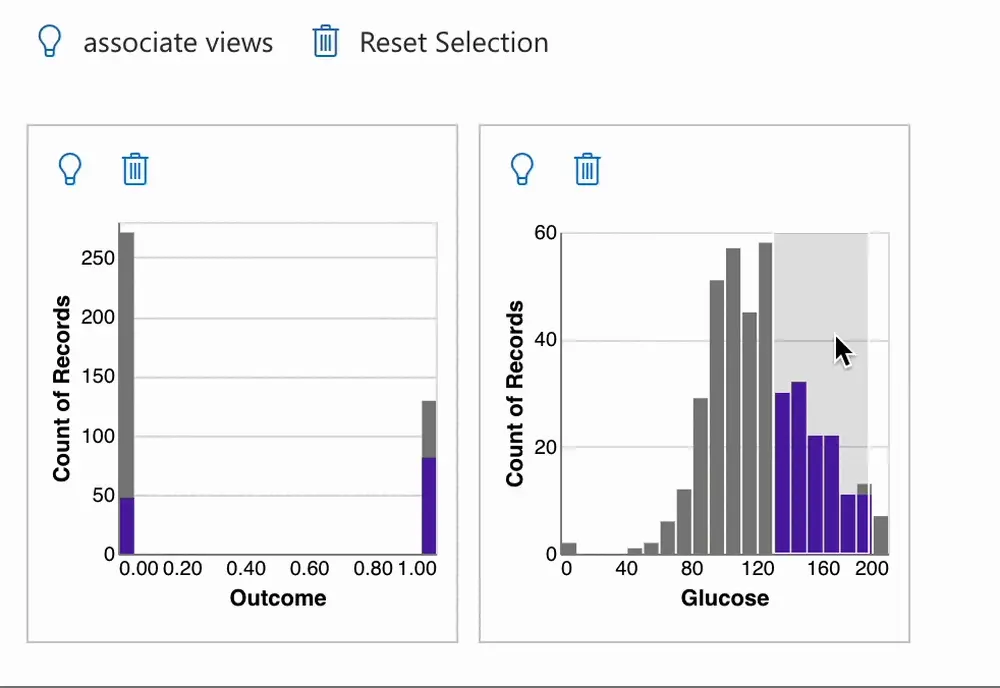
더 나아가려면 associate views를 클릭해 Semi-auto Exploration을 활성화합니다. 그러면 RATH가 선택된 변수들 간의 잠재적 관계를 강조하는 scatter plot 등 시각화를 추천해, 추가 패턴을 더 빠르게 발견하도록 도와줍니다.
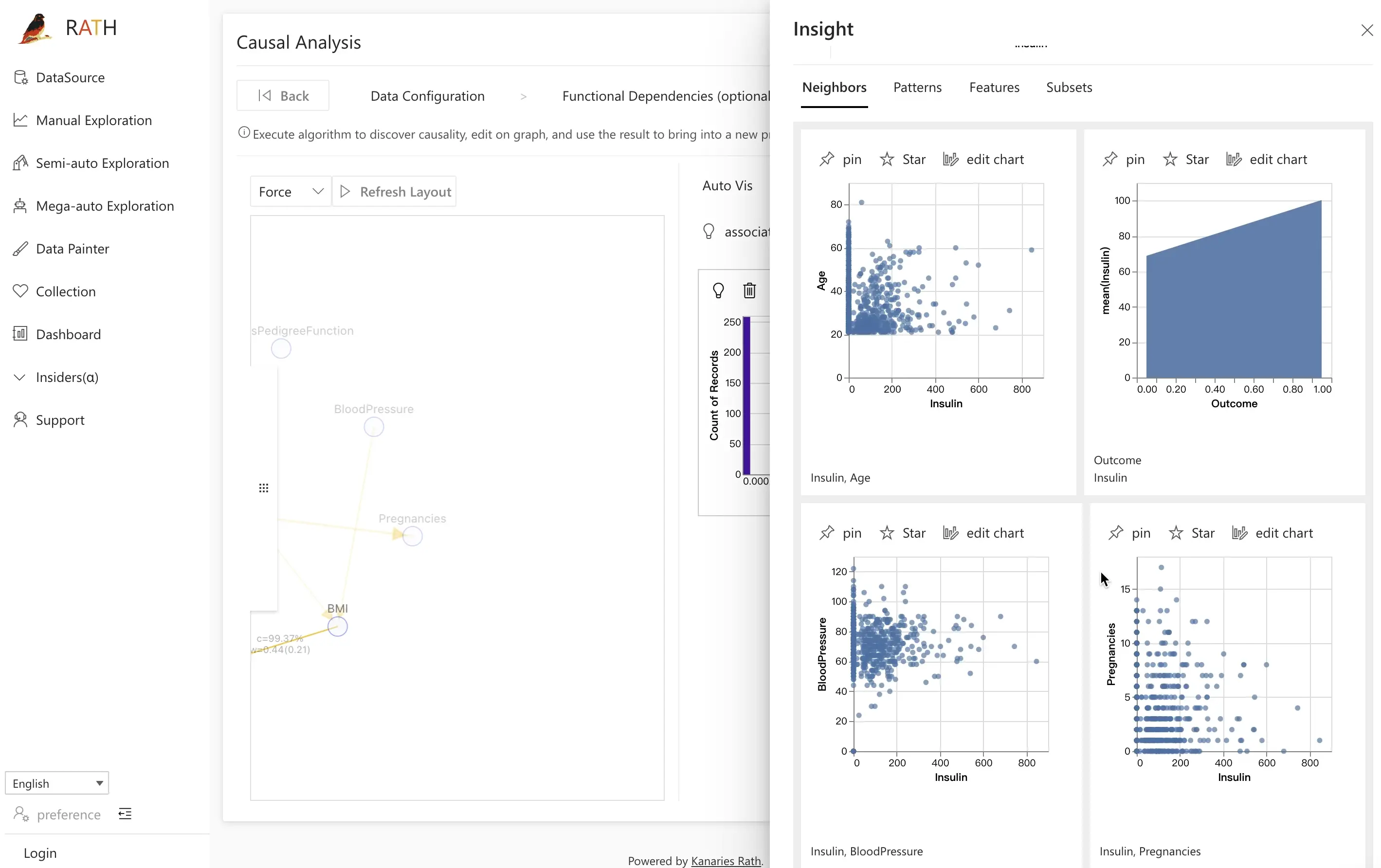
Step 3.4: Prediction Test
인과 모델을 얻었다면, 이를 기반으로 예측용 머신러닝 모델을 만들고 Prediction Test로 성능을 평가할 수 있습니다.
- 인과 그래프에서
Outcome변수를 클릭합니다.
그러면 RATH가 인과 부모 및 관련 변수를 사용해 간단한 분류 또는 회귀 모델을 자동으로 구성합니다.
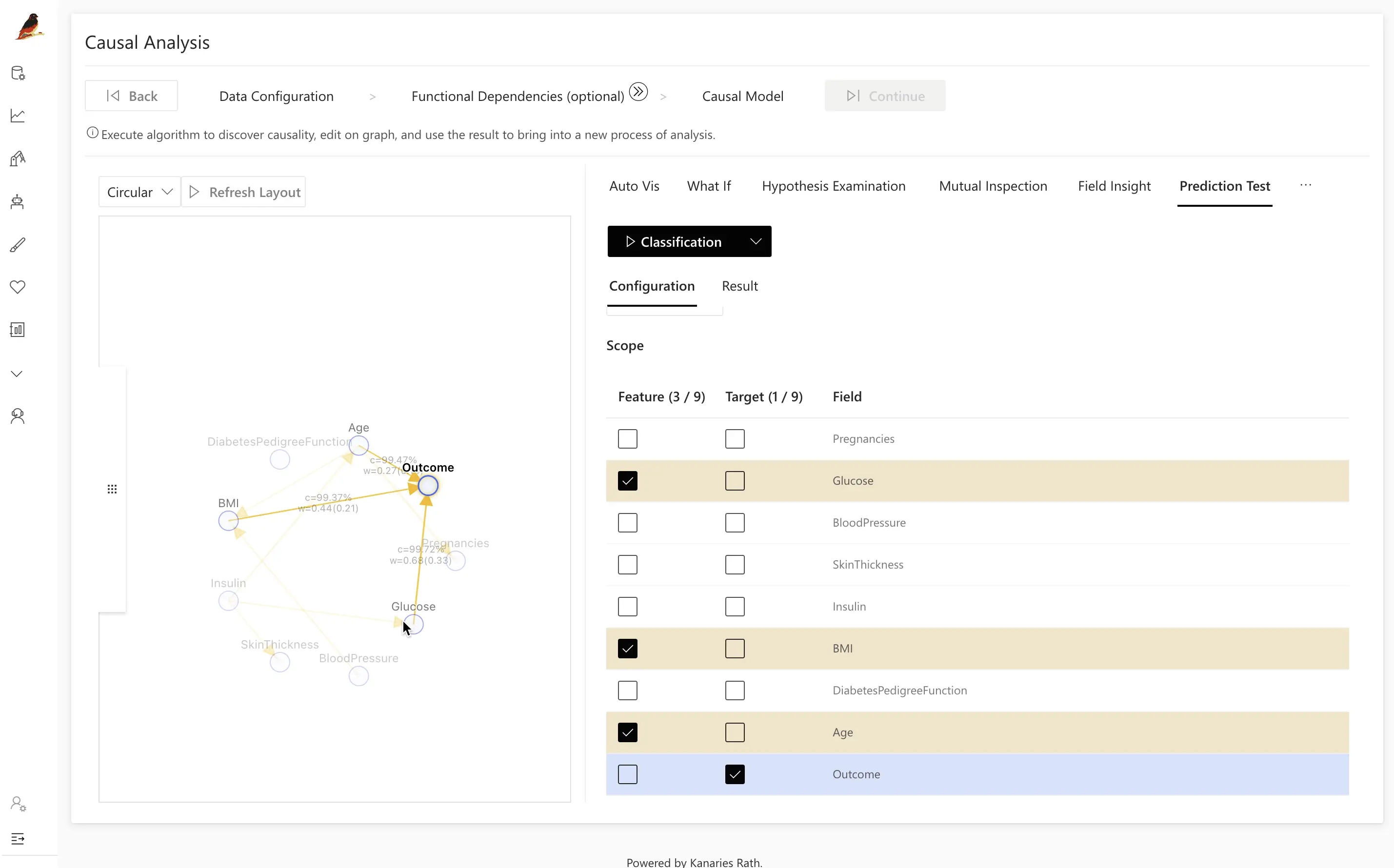
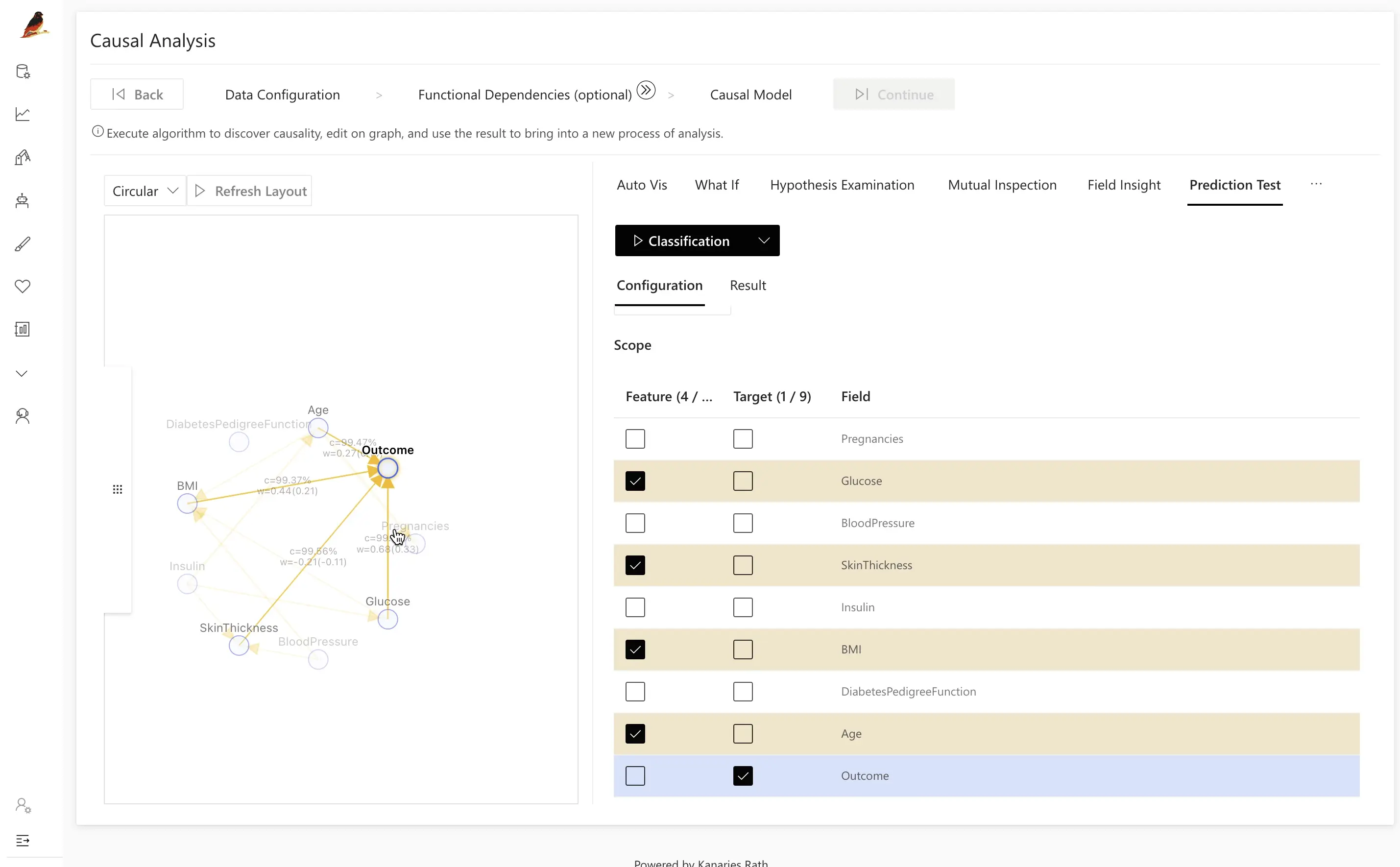
- Classification을 클릭해 모델을 학습시키고, Accuracy(및 설정에 따라 다른 지표)를 계산합니다.

- 테스트 전략을 조정합니다:
- 인과 그래프를 활용해 더 효율적이거나 해석 가능한 피처 세트를 선택합니다.
- 인과 피처 기반 모델과 임의 피처 부분집합 기반 모델을 비교합니다.
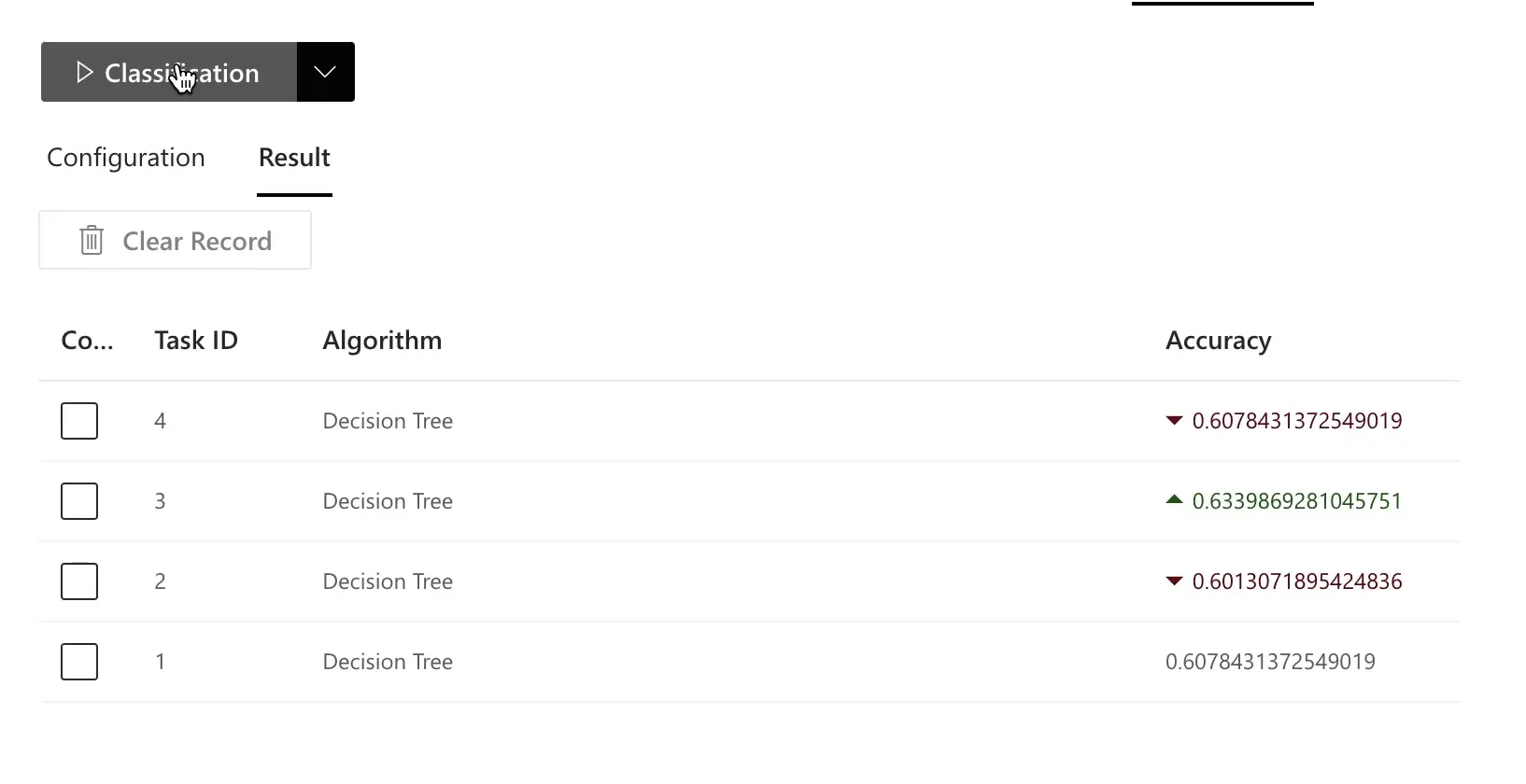
예를 들어, RATH의 인과 분석이 제안한 피처를 의도적으로 제외한 경쟁 모델을 만들고, 두 모델의 결과를 비교해 볼 수 있습니다:
일반적으로, 인과 그래프를 기반으로 한 모델은 단순한 피처 선택보다 더 높은 정확도와 더 좋은 일반화 성능을 보입니다:
RATH는 특히 변수 수가 많은 대규모 고차원 데이터셋에 적합합니다. 인과 분석을 통해 더 나은 피처를 자동으로 찾아내어, 보다 정확하고 해석 가능한 머신러닝 모델을 구축할 수 있습니다.
인과 모델 편집
현실 세계의 데이터는 깔끔하지 않습니다. 다음과 같은 이유로 RATH의 자동 인과 그래프가 도메인 지식과 일치하지 않을 수 있습니다:
- 데이터 노이즈
- 샘플 수 부족
- 누락된 변수
- 알고리즘이 스스로 추론할 수 없는 제약 조건
이럴 때는 인과 모델을 직접 편집할 수 있습니다.
- 왼쪽 패널을 엽니다.
- Modify Constraints를 켭니다.
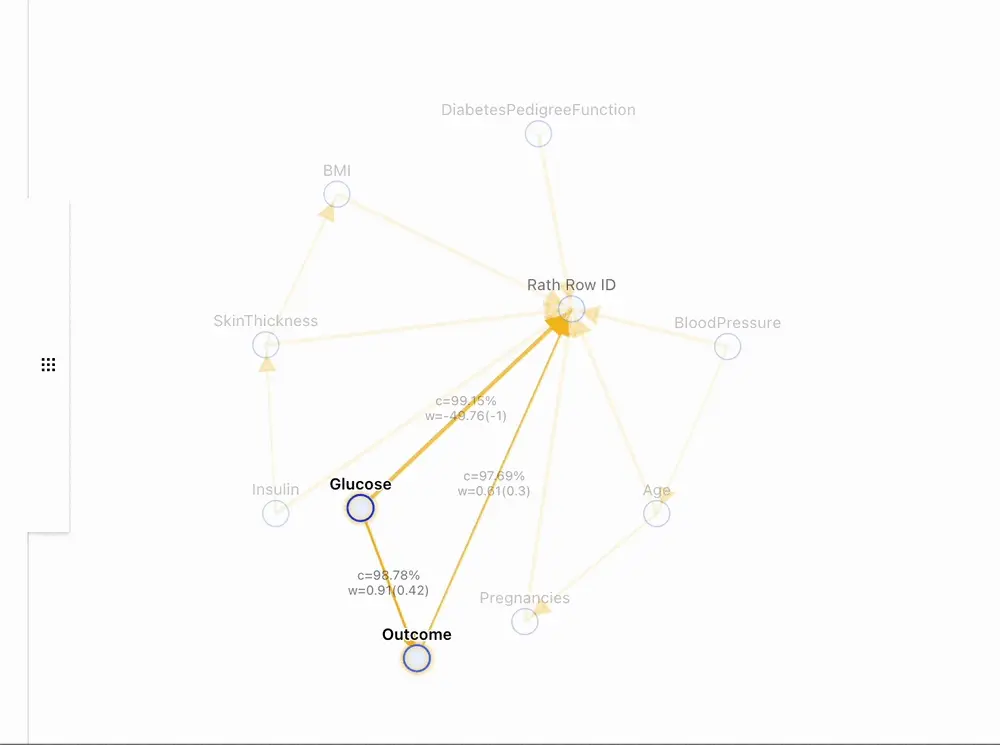
그 다음:
- 노드를 드래그 앤 드롭해 엣지를 추가·삭제하거나 방향을 바꿉니다.
- “변수 A는 변수 B에 의해 원인으로 설명될 수 없다”와 같은 도메인 지식을 모델에 반영합니다.
- RATH가 이러한 제약을 존중하면서 새로운 인과 모델을 다시 생성하도록 합니다.
이처럼 자동 발견과 수동 정교화를 빠르게 반복하여, 통계적으로 그럴듯하면서도 전문가의 이해와도 잘 맞는 인과 모델에 수렴할 수 있습니다.
다음 단계
인과 모델을 구축한 뒤에는 RATH에서 다음과 같은 작업으로 확장할 수 있습니다:
- What-if Analysis 챕터를 통해 what-if 스타일 인과 분석을 학습합니다. 인과 모델에서 직접 “
Glucose를 X만큼 낮추면Outcome은 어떻게 변할까?”와 같은 개입을 시뮬레이션할 수 있습니다. - Text Pattern Extraction을 사용해 텍스트 필드에서 패턴을 추출한 뒤, 이렇게 얻은 피처를 다시 인과 분석에 활용합니다.
RATH는 또한 인과 그래프의 구조와 추정치를 기반으로, 인과 모델에 대한 서술형 텍스트 설명과 의사결정에 대한 제안을 자동으로 생성하는 방향으로 발전하고 있습니다.
시각적 인과 발견, 인터랙티브 탐색, 예측 모델링을 결합함으로써, RATH는 단순한 정적 대시보드를 넘어 데이터셋을 실제 행동 가능한 설명 가능 인사이트로 전환해 줍니다.