파이썬의 판다스 라이브러리, PySpark, R 및 PygWalker를 사용하여 CSV 파일을 데이터프레임으로 읽는 방법

CSV 파일은 테이블 형식 데이터를 저장하고 공유하는 인기 있는 방법입니다.이 종합 가이드에서는 파이썬의 Pandas 라이브러리, PySpark, R 및 PygWalker GUI를 사용하여CSV 파일을 데이터프레임으로 읽는 방법을 살펴보겠습니다.사용자 지정 구분 기호, 행 및 헤더 건너뛰기, 누락된 데이터 처리, 사용자 지정 열 이름 설정, 데이터 유형 변환과 같은 다양한 시나리오를 다룹니다.이러한 강력한 도구를 사용하여 데이터 조작 기술을 향상시키고 데이터 분석을 더욱 효율적으로 수행하세요.
- Runcell Science: Claude Science를 대체할 오픈소스 AI 연구 워크스페이스
- 맥 잠자기 방지: 맥북 닫아도 Codex와 Claude Code 계속 실행하기
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026년에 어떤 AI 에이전트 스택을 선택해야 할까?
- Claude Code로 Jupyter 노트북을 분석하는 방법 | Data Science 실무 가이드와 한계
- Claude Code 루틴 사용법: AI 에이전트 cron 작업과 자동 트리거
- Claude Code Desktop에서 Bypass permissions 켜는 법
- Google의 A2A 프로토콜을 사용한 두 개의 Python 에이전트 빌드하기 - 단계별 튜토리얼
- 2025년 파이썬에서 가장 성장하는 상위 10개 데이터 시각화 라이브러리
팬더에서 CSV 파일 읽기
Pandas는 데이터 조작 및 분석에 사용되는 인기 있는 Python 라이브러리입니다.대용량 데이터 세트를 효율적으로 저장하고 조작하기 위한 데이터 구조를 제공합니다.Pandas의 read_csv () 함수는 CSV 파일을 데이터 프레임으로 읽는 데 사용할 수 있습니다.예를 들면 다음과 같습니다.
코드_블록_플레이스홀더_0
이 예제에서는 read_csv () 함수를 사용하여 'sample.csv '라는 CSV 파일을 데이터 프레임으로 읽습니다.그런 다음 print () 함수를 사용하여 결과 데이터 프레임을 인쇄합니다.
Pandas에서 사용자 지정 구분 기호 지정하기
기본적으로 Pandas는 CSV 파일의 값이 쉼표로 구분된다고 가정합니다.그러나 항상 그런 것은 아닙니다.'delimiter' 매개 변수를 사용하여 사용자 지정 구분 기호를 지정할 수 있습니다.
코드_블록_플레이스홀더_1 여기서는 CSV 파일의 구분 기호를 '; '로 지정했습니다.
Pandas에서 행과 머리글 건너뛰기
CSV 파일을 읽을 때 특정 행이나 헤더를 건너뛰고 싶을 때가 있습니다.'skiprows' 및 '헤더' 파라미터를 사용하여 이 작업을 수행할 수 있습니다.
코드_블록_플레이스홀더_2
여기서는 CSV 파일의 처음 두 행을 건너뛰고 첫 번째 행을 열 이름으로 사용하지 않습니다.
Pandas에서 누락된 데이터 처리하기
CSV 파일에는 데이터가 누락되어 데이터 프레임으로 읽을 때 문제가 발생할 수 있습니다.기본적으로 Pandas는 누락된 데이터를 'NaN' 값으로 대체합니다.na_values 매개 변수를 사용하여 누락된 데이터를 대체할 사용자 지정 값을 지정할 수 있습니다.
코드_블록_플레이스홀더_3
여기서는 'n/a' 및 'NaN' 값을 누락된 데이터로 처리하도록 지정했습니다.
Pandas에서 사용자 지정 열 이름 설정하기
기본적으로 Pandas는 CSV 파일의 첫 번째 행을 열 이름으로 사용합니다.names 매개 변수를 사용하여 사용자 지정 열 이름을 지정할 수 있습니다.
코드_블록_플레이스홀더_4
여기서는 열 이름을 '이름', '나이', '성별'로 지정했습니다.
Pandas의 데이터 유형 변환
때로는 열의 데이터 유형을 변환하고 싶을 수 있습니다.예를 들어 문자열 열을 정수 또는 부동 소수점 열로 변환하고 싶을 수 있습니다.dtype 매개 변수를 사용하여 이 작업을 수행할 수 있습니다.
코드_블록_플레이스홀더_5 여기서는 'Age' 열을 정수 데이터 유형으로 변환하도록 지정했습니다.
Pandas의 데이터 프레임으로 텍스트 파일 읽기
CSV 파일 외에도 Pandas는 텍스트 파일을 데이터 프레임으로 읽을 수도 있습니다.예를 들면 다음과 같습니다.
코드_블록_플레이스홀더_6
이 예제에서는 'sample.txt '라는 텍스트 파일을 데이터 프레임으로 읽고 있습니다.텍스트 파일의 구분 기호를 탭으로 지정했습니다.
파이스파크에서 CSV를 데이터그램으로
PySpark에서 데이터프레임으로 CSV 파일 읽기
PySpark에서는 SparkSession 객체의 read () 메서드를 사용하여 CSV 파일을 읽고 데이터 프레임을 생성할 수 있습니다.read () 메서드는 구분 기호, 헤더 및 스키마 지정과 같은 CSV 리더를 구성하는 옵션을 제공합니다.
다음은 PySpark에서 CSV 파일을 데이터프레임으로 읽는 방법의 예입니다.
코드_블록_플레이스홀더_7
이 예제에서는 SparkSession 객체를 만들고 CSV 형식 옵션과 함께 read () 메서드를 사용합니다.또한 CSV 파일의 첫 번째 행에 헤더가 포함되도록 지정하고 데이터에서 스키마를 유추하도록 지정합니다.마지막으로 CSV 파일의 경로를 지정하고 이를 데이터프레임에 로드합니다.그런 다음 show () 메서드를 사용하여 결과 데이터 프레임을 인쇄합니다.
PySpark에서 여러 CSV 파일을 하나의 데이터프레임으로 읽기
PySpark는 여러 CSV 파일을 단일 데이터프레임으로 쉽게 읽을 수 있는 강력한 빅데이터 처리 프레임워크입니다.이는 SparkSession 객체의 read () 메서드를 사용하고 CSV 파일 경로에 와일드카드 문자 (*) 를 지정하여 수행할 수 있습니다.예를 들면 다음과 같습니다.
코드_블록_플레이스홀더_8
이 예제에서는 SparkSession 객체를 만들고 와일드카드 문자가 있는 load () 메서드를 사용하여 지정된 디렉터리에 있는 모든 CSV 파일을 읽습니다.그런 다음 show () 메서드를 사용하여 결과 데이터 프레임을 인쇄합니다.
CSV를 R의 데이터프레임으로
R의 데이터프레임으로 CSV 파일 읽기
Python의 Pandas 라이브러리 외에도 R에는 CSV 파일을 데이터 프레임으로 읽는 내장 함수가 있습니다.이를 위해 read.csv () 함수를 사용할 수 있습니다.예를 들면 다음과 같습니다.
코드_블록_플레이스홀더_9
이 예제에서는 read.csv () 함수를 사용하여 'sample.csv '라는 CSV 파일을 데이터 프레임으로 읽습니다.그런 다음 print () 함수를 사용하여 결과 데이터 프레임을 인쇄합니다.
R에서 CSV 파일을 데이터프레임으로 변환
R에서는 as.data.frame () 함수를 사용하여 CSV 파일을 데이터 프레임으로 변환할 수도 있습니다.예를 들면 다음과 같습니다.
코드_블록_플레이스홀더_10
이 예제에서는 read.csv () 함수를 사용하여 'sample.csv '라는 이름의 CSV 파일을 읽은 다음 as.data.frame () 함수를 사용하여 이를 데이터 프레임으로 변환합니다.그런 다음 print () 함수를 사용하여 결과 데이터 프레임을 인쇄합니다.
CSV를 피그워커에서 데이터 시각화로
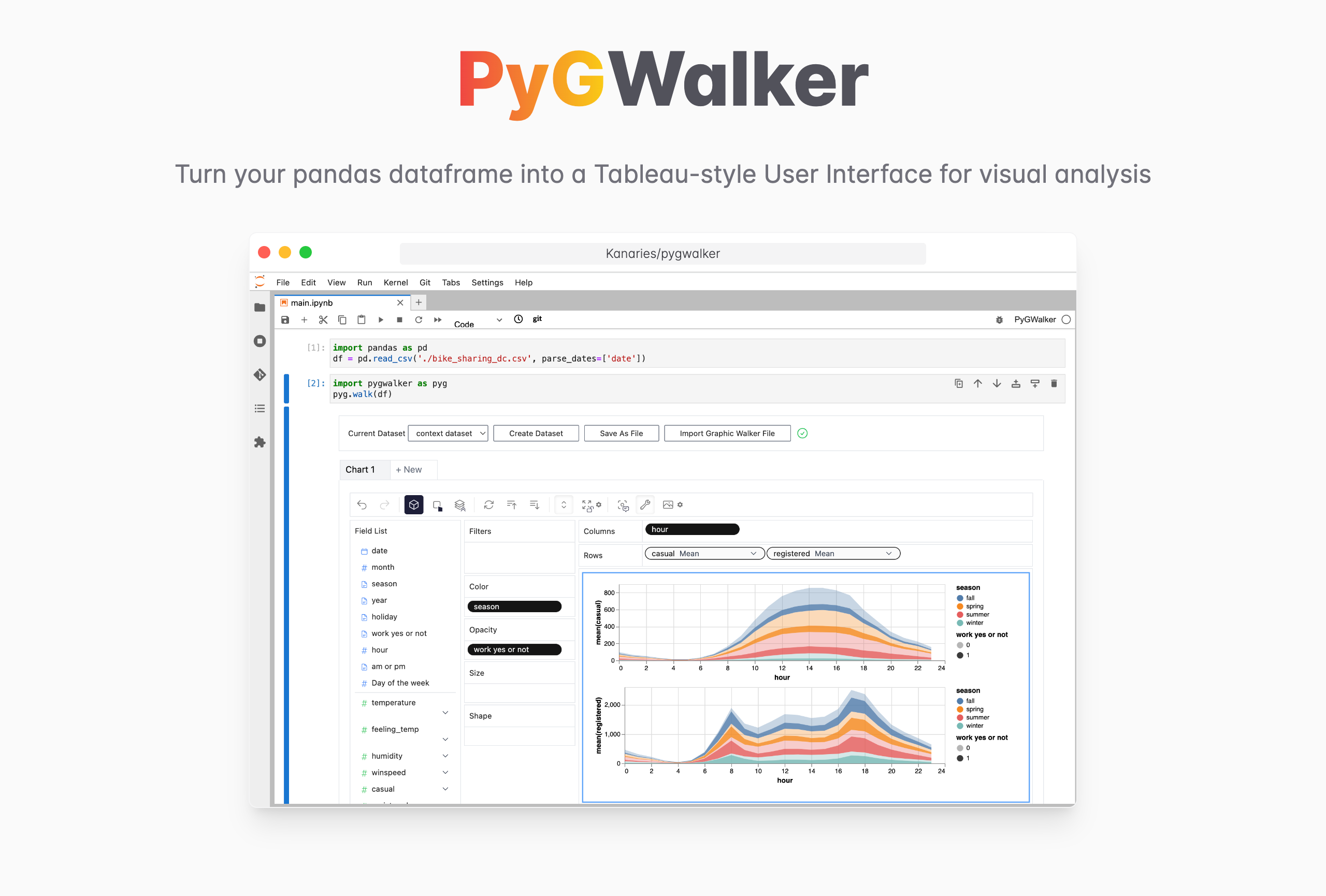
PygWalker (opens in a new tab) 는 판다 데이터 프레임 (및 폴라 데이터 프레임) 을 시각적 탐색을 위한 Tableau 스타일의 사용자 인터페이스로 전환하여 데이터 분석 및 데이터 시각화 워크플로를 단순화할 수 있습니다.주피터 노트북 (또는 기타 주피터 기반 노트북) 을 Tableau의 다른 유형의 오픈 소스 대안인 그래픽 워커 와 통합합니다.이를 통해 데이터 과학자는 간단한 드래그 앤 드롭 조작으로 데이터를 분석하고 패턴을 시각화할 수 있습니다.
피그워커는 오픈 소스입니다.PygWalker GitHub (opens in a new tab) 를 확인하고 ⭐️ 를 남기는 것을 잊지 마세요!
CSV 파일을 데이터프레임으로 읽기
이 예제에서는 주피터 노트북에서 PygWalker를 실행할 것입니다.바인더 (opens in a new tab), 구글 콜랩 (opens in a new tab) 또는 Kaggle Code (opens in a new tab) 를 방문하여 온라인으로 PygWalker를 실행할 수도 있습니다.
| 런 인 캐글 (opens in a new tab) | 콜랩에서 실행 (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) |  (opens in a new tab) (opens in a new tab) |
Python 환경에서 다음 코드를 실행하여 "bike_sharing_dc.csv" CSV 파일을 Pandas로 가져옵니다.
코드_블록_플레이스홀더_11
Polars를 선호하는 경우 다음 코드를 사용하여 CSV를 팬더 데이터프레임으로 가져오세요.
코드_블록_플레이스홀더_12
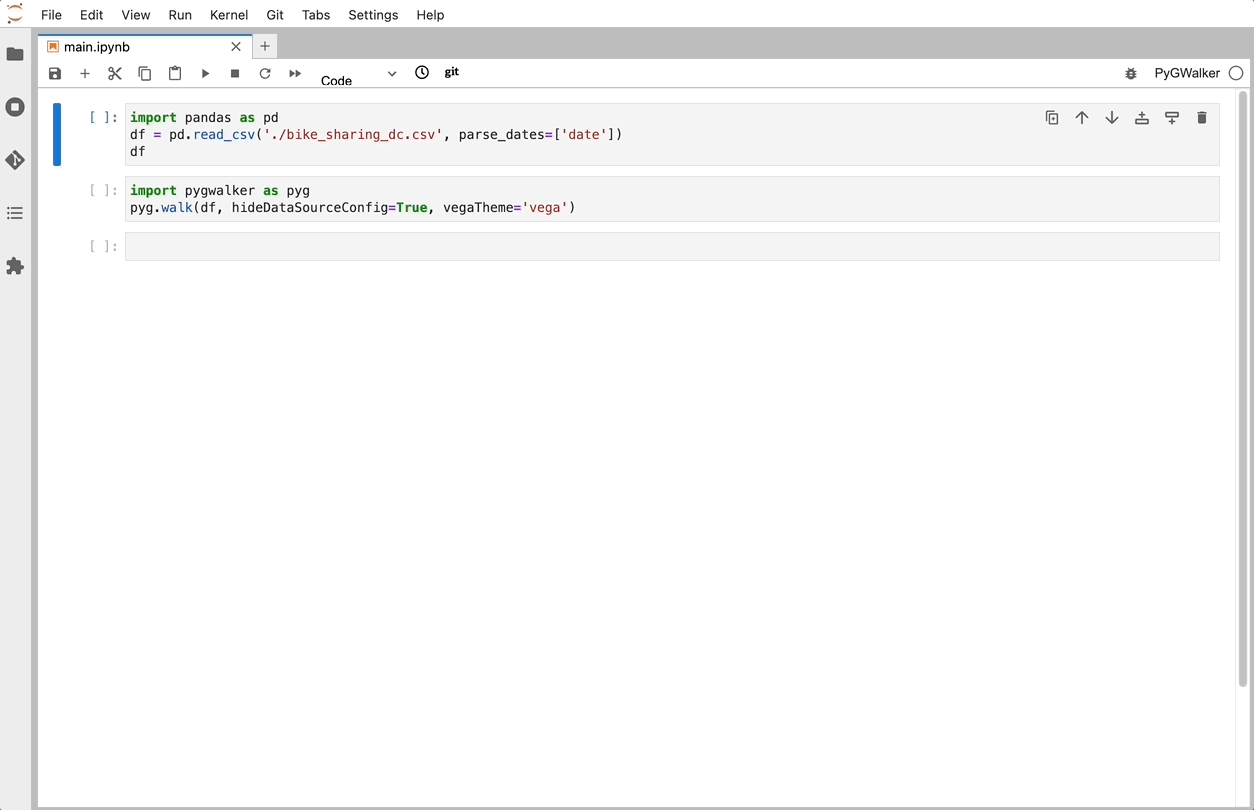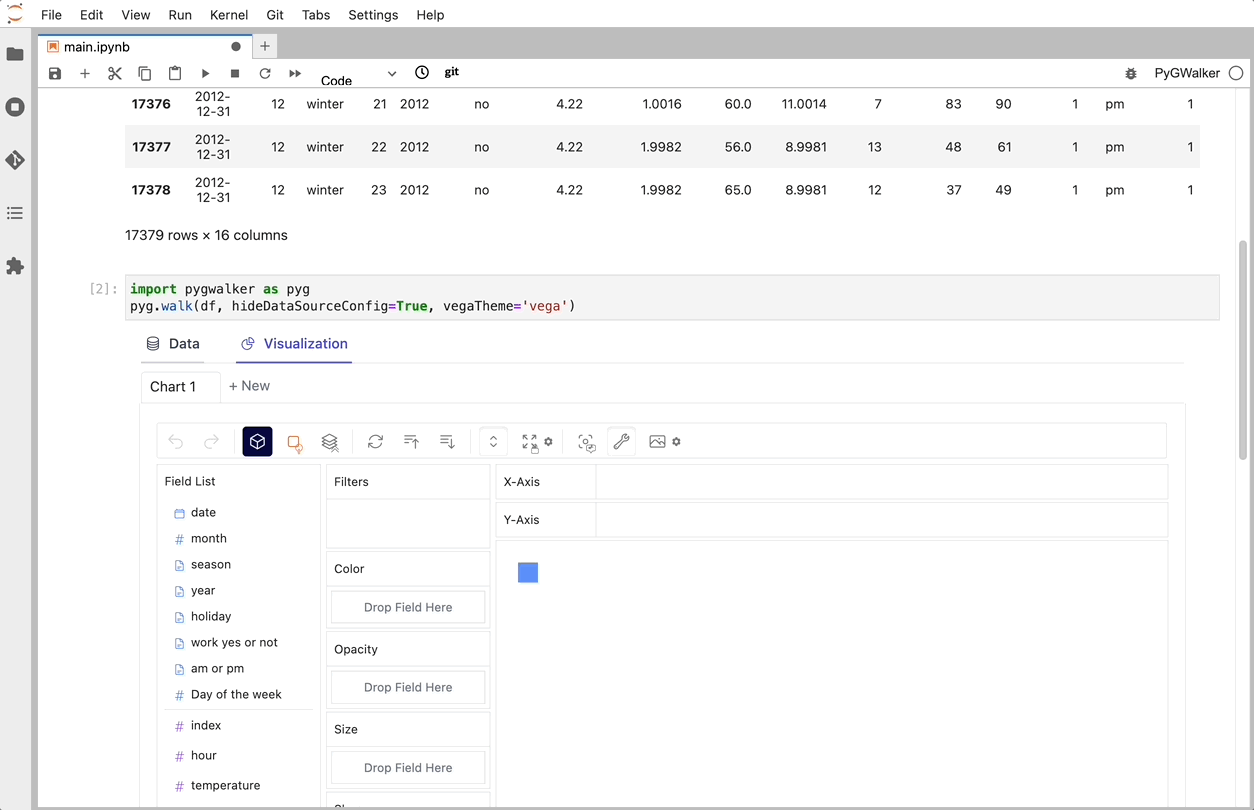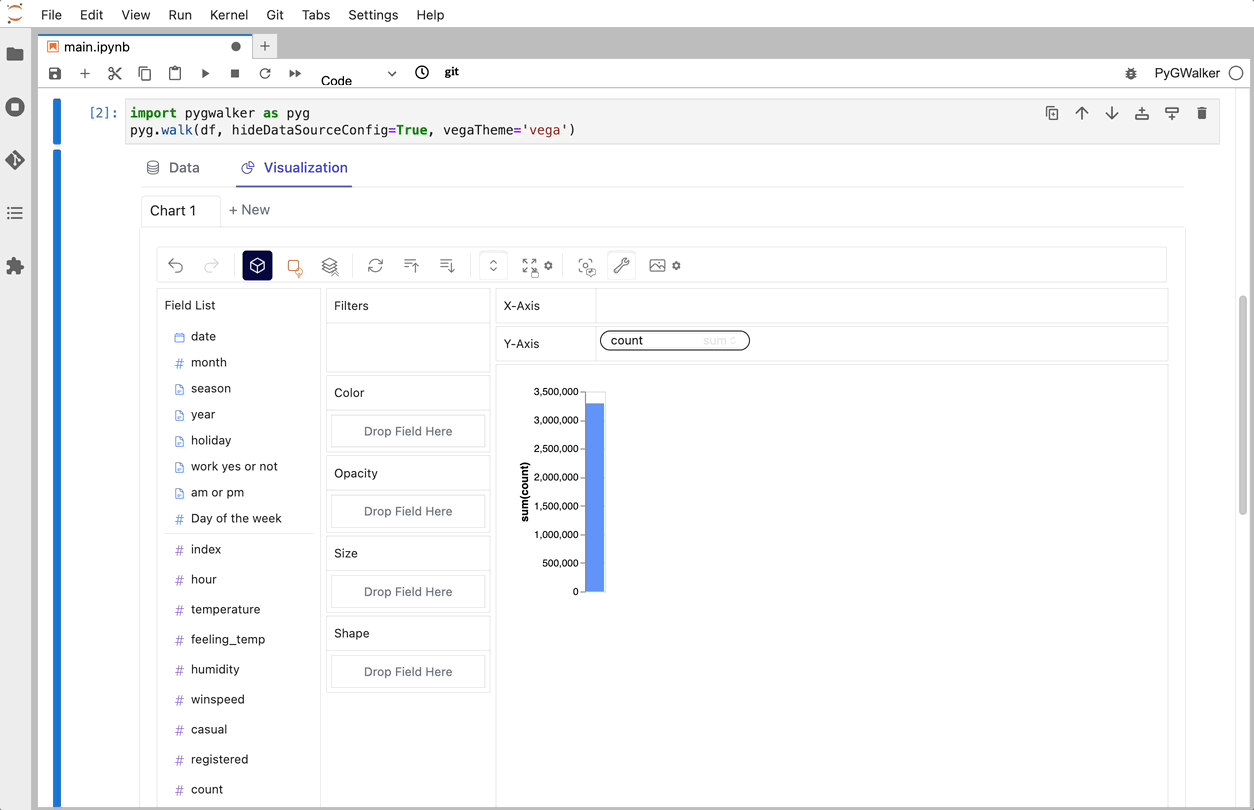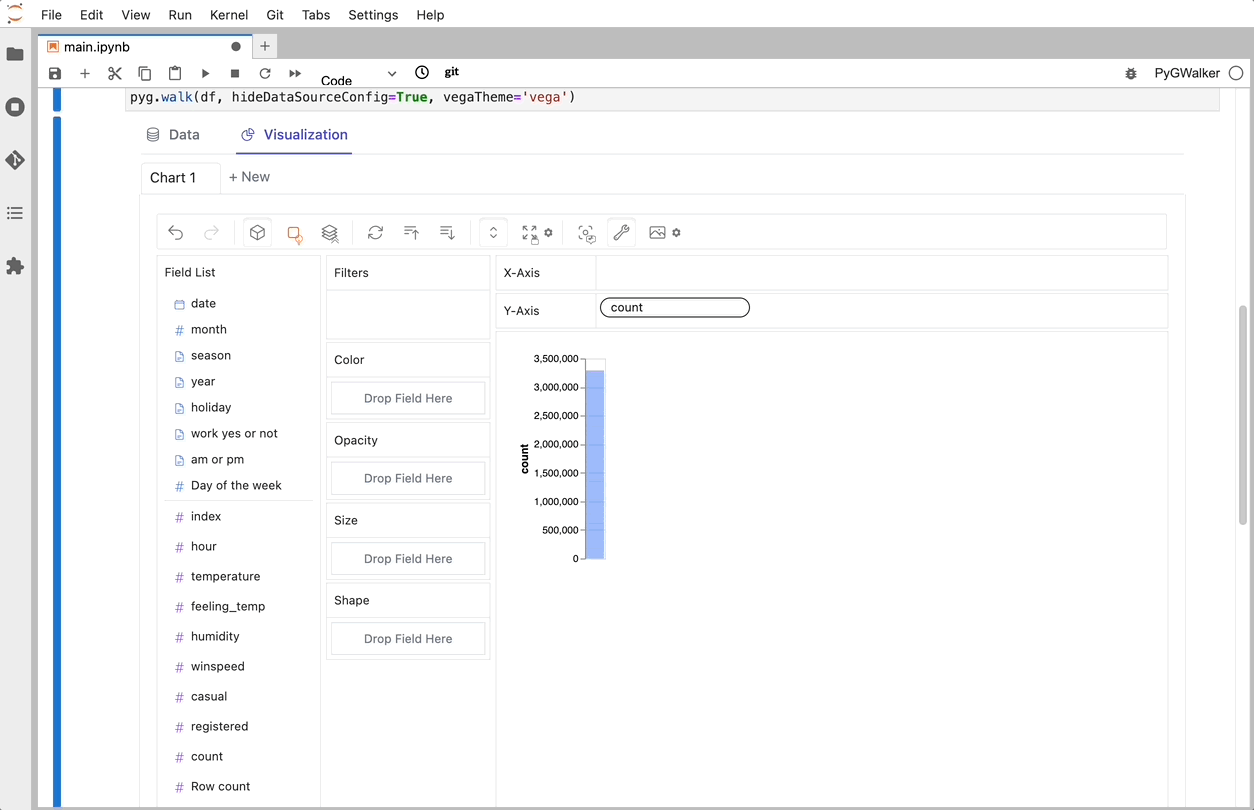
피그워커를 통해 CSV를 데이터 시각화로 전환
CSV를 Pandas 데이터 프레임으로 가져온 후 PygWalker를 호출하여 Tableau와 유사한 사용자 인터페이스를 사용하여 변수를 끌어서 놓는 방식으로 데이터를 분석하고 시각화할 수 있습니다.
코드_블록_플레이스홀더_13
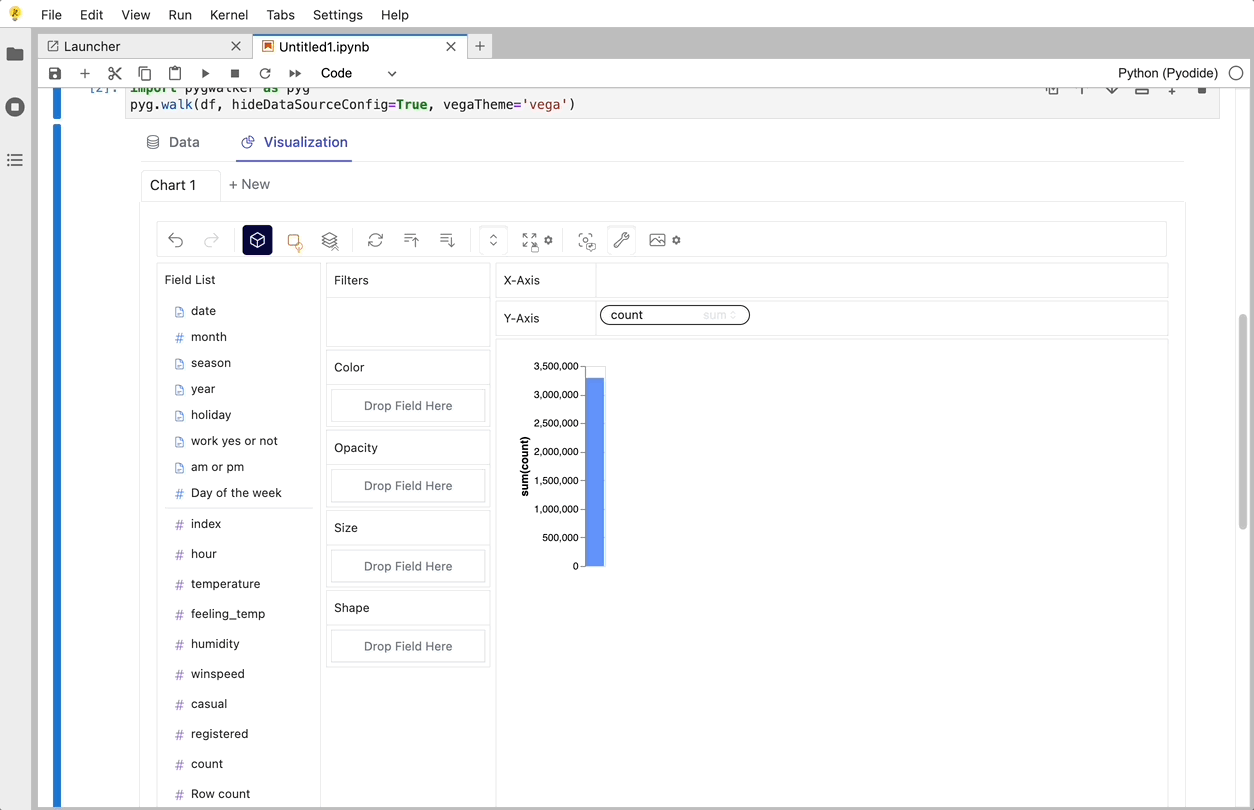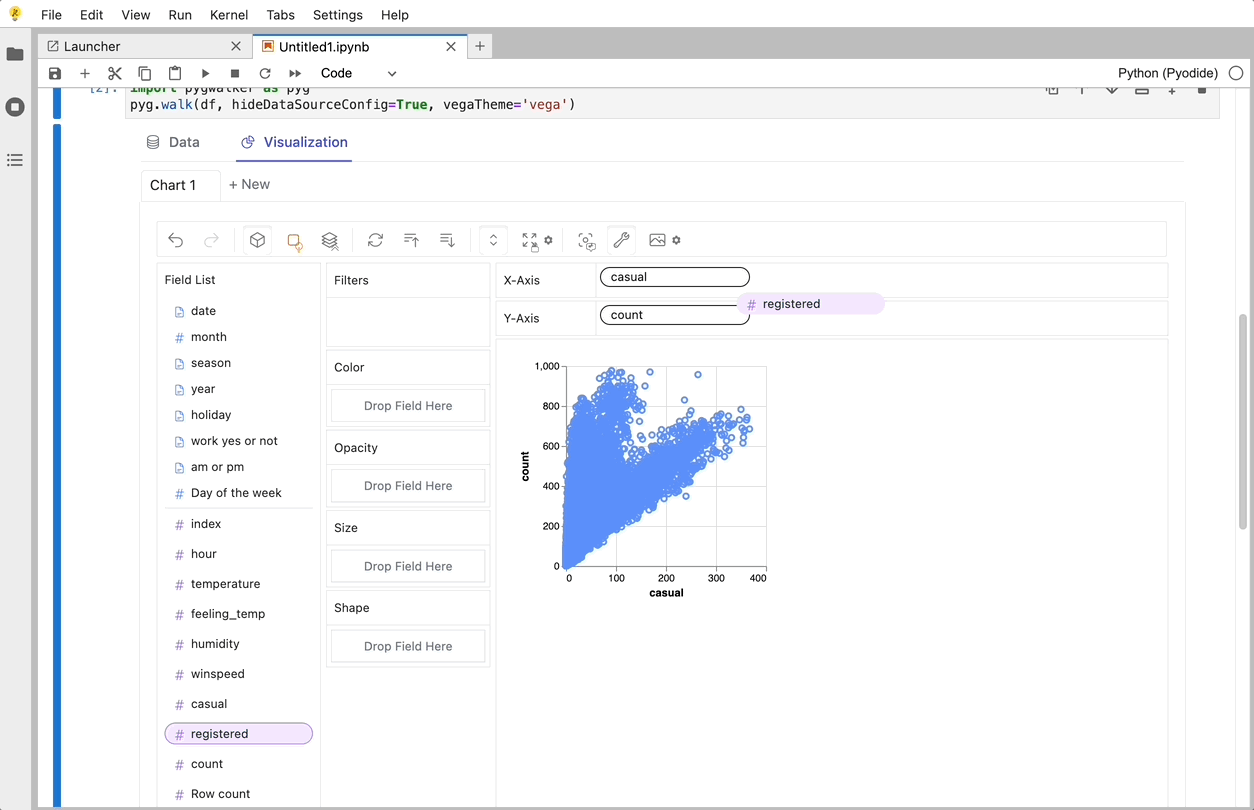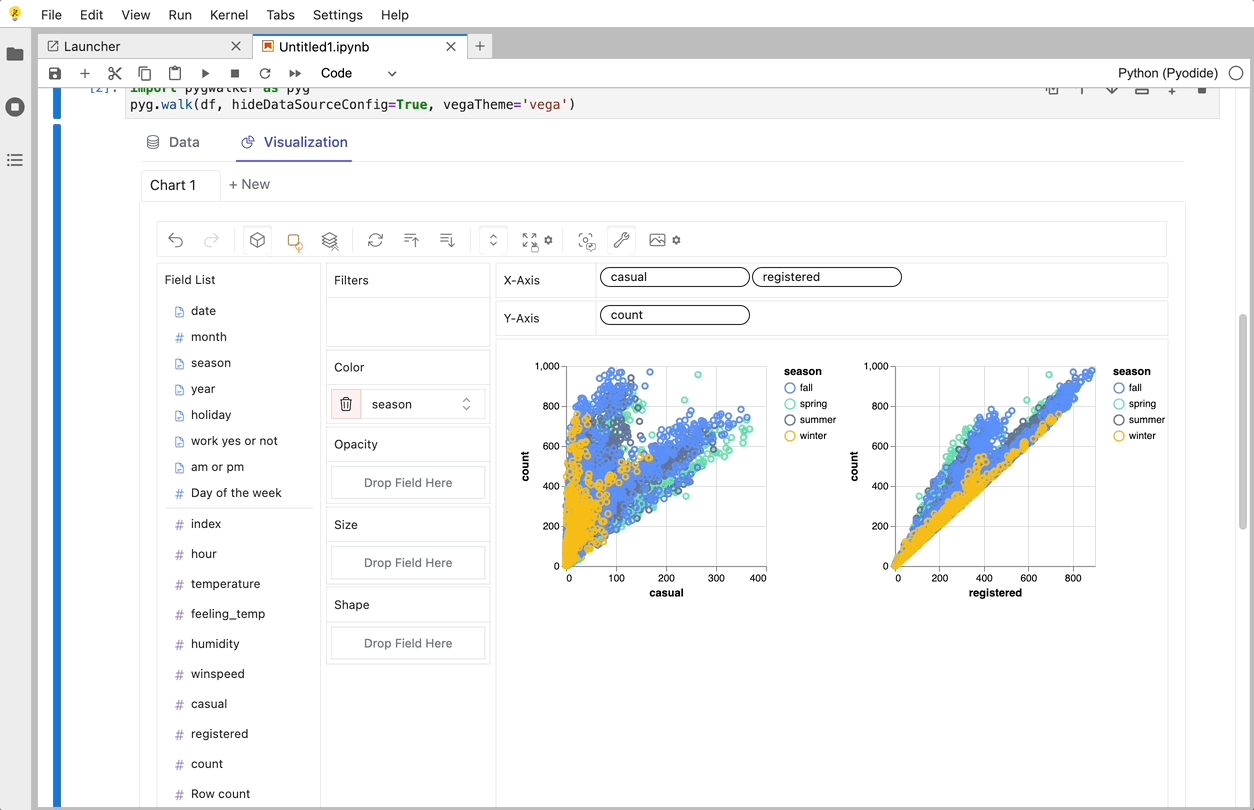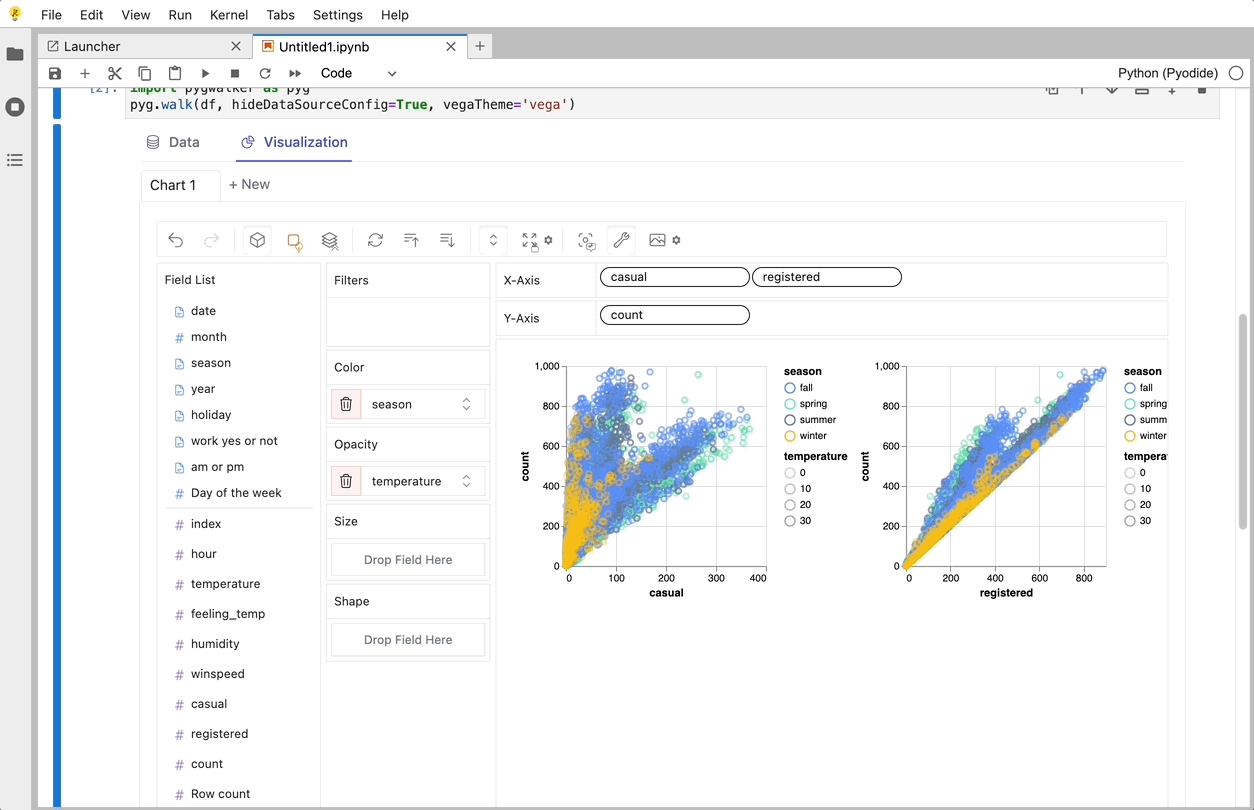
Graphic Walker를 사용하여 변수 드래그 앤 드롭을 지원하는 UI를 사용하여 이러한 차트를 만들 수 있습니다.
막대 그래프 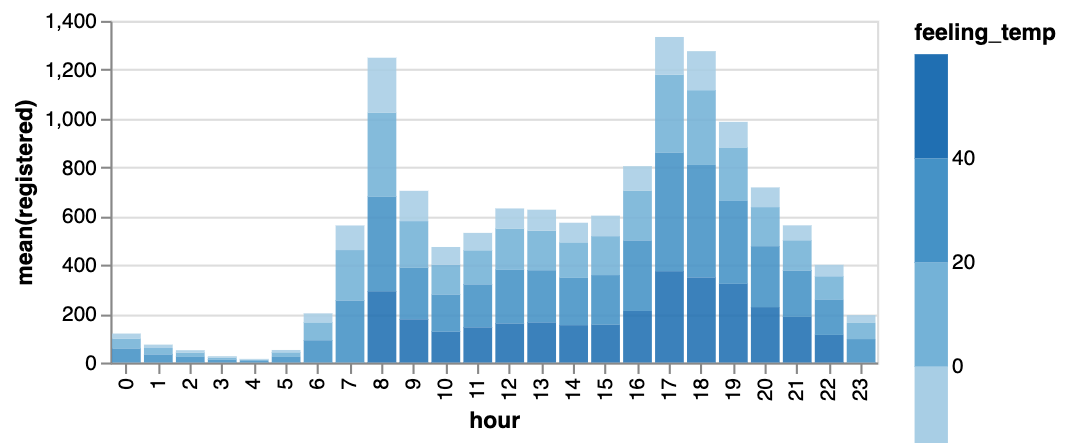 | 선 그래프 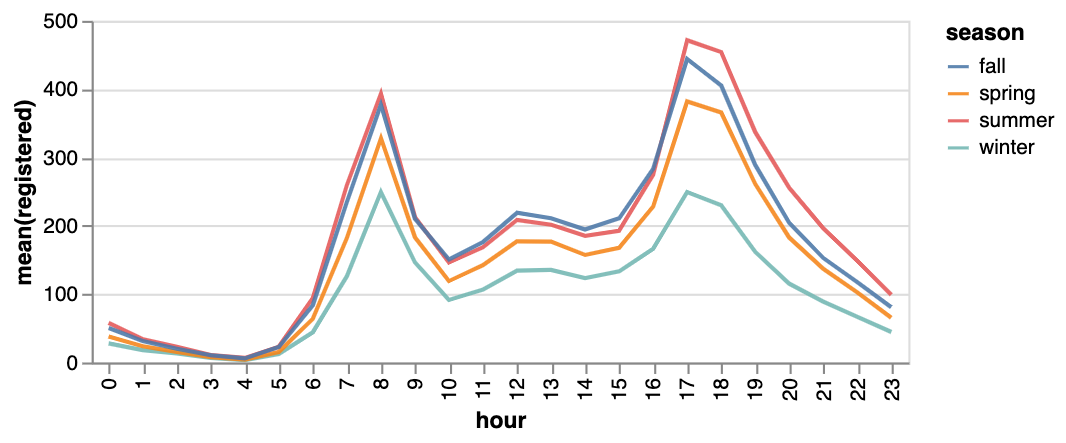 | 면적 그래프 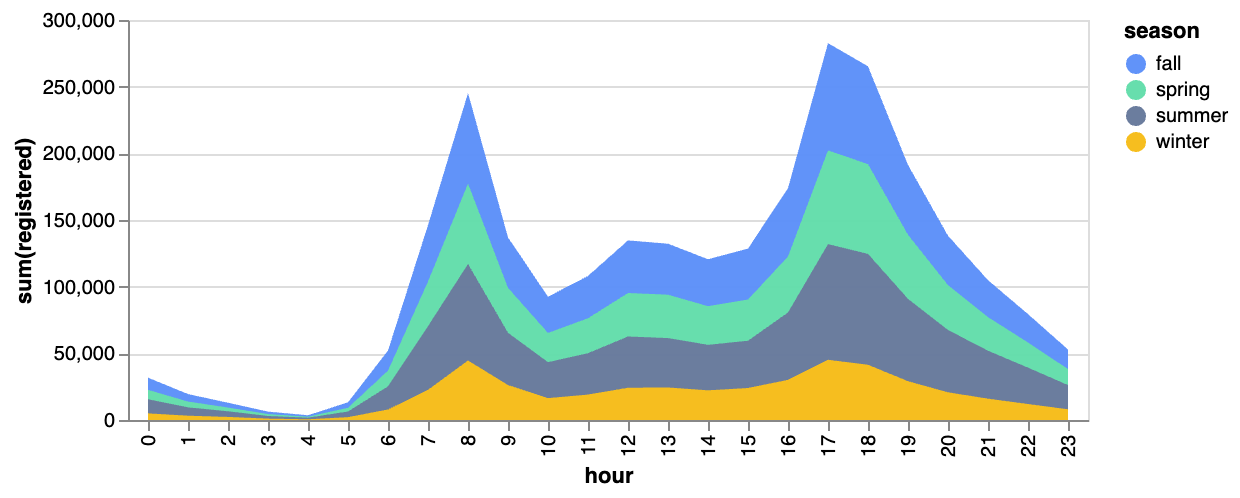 |
|---|---|---|
트레일 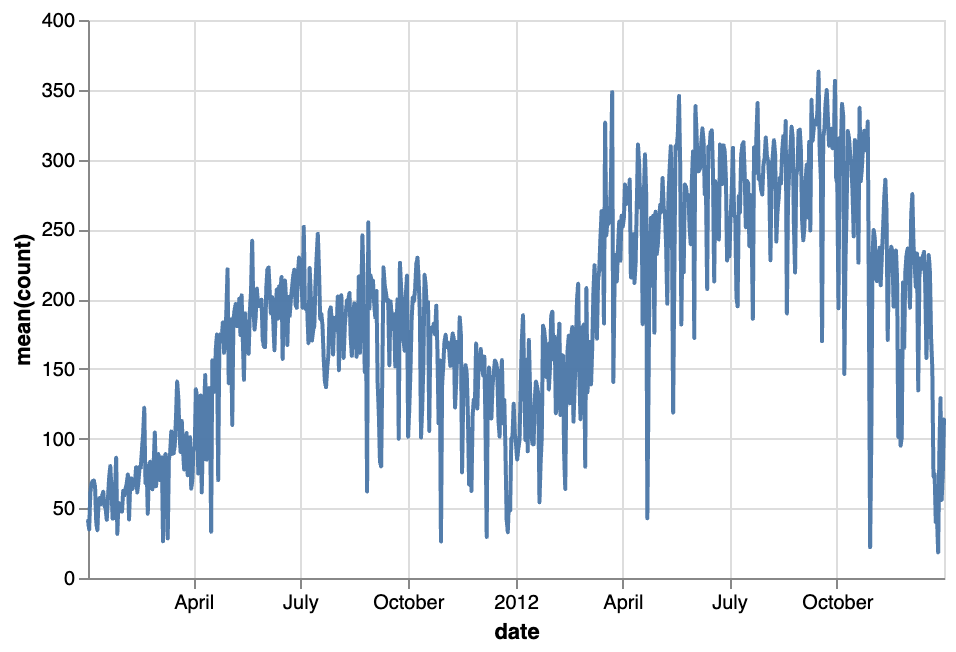 | 산점도 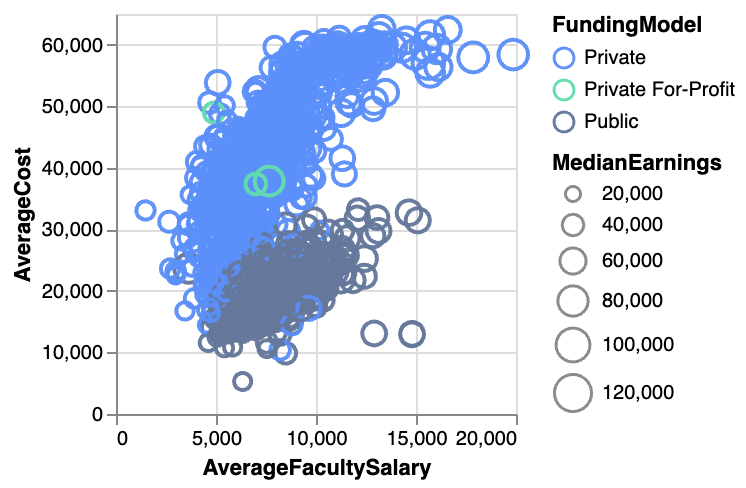 | 원 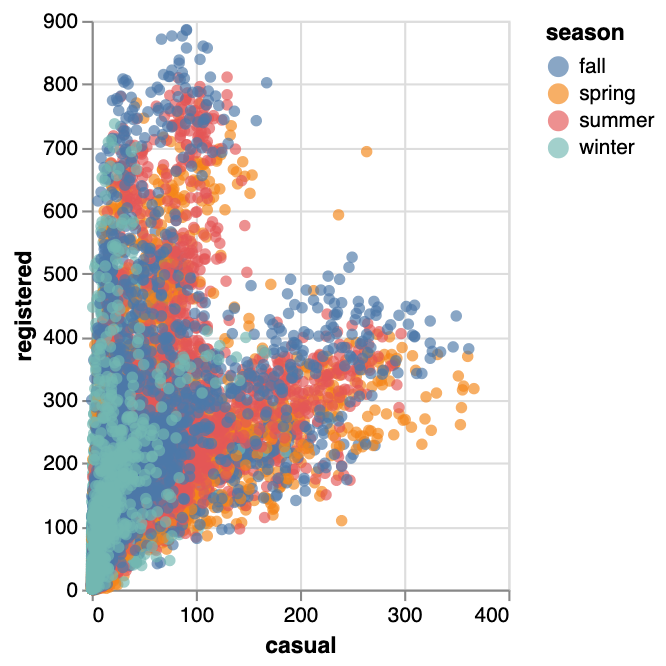 |
틱 플롯 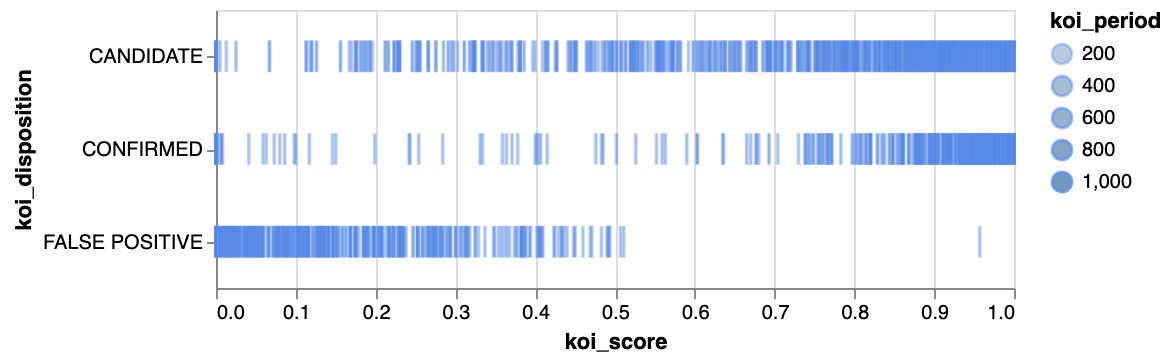 | 사각형  | 아크 다이어그램  |
박스 플롯  | 히트맵  |
더 많은 예제는 데이터 시각화 갤러리에서 확인하실 수 있습니다.
결론
CSV 파일을 데이터프레임으로 읽는 것은 데이터 과학 및 분석에서 일반적인 작업입니다.파이썬의 Pandas 라이브러리와 R 모두 이러한 목적을 위한 함수를 제공합니다.이 기사에서는 CSV 파일을 읽는 방법에 대해 설명했습니다. 사용자 지정 구분 기호, 행 및 헤더 건너뛰기, 누락된 데이터 처리, 사용자 지정 열 이름 설정, 데이터 유형 변환과 같은 다양한 시나리오뿐만 아니라 Pandas 및 R을 사용하여 데이터 프레임으로 변환할 수 있습니다.
자주 묻는 질문
1.CSV 파일이란 무엇입니까? A: CSV 파일은 표 형식 데이터를 일반 텍스트 형식으로 저장하는 데 사용되는 파일 유형으로, 각 줄은 행을 나타내고 각 값은 구분 기호로 구분합니다.
2.데이터프레임이란 무엇인가요? A: 데이터 프레임은 Python과 R에서 테이블 형식 데이터를 저장하고 조작하는 데 사용되는 2차원 데이터 구조입니다.
3.사용자 지정 구분 기호를 사용하여 CSV 파일을 Pandas 데이터 프레임으로 읽으려면 어떻게 해야 하나요?
A: read_csv () 함수에서 구분자 매개 변수를 사용하여 사용자 지정 구분 기호를 지정할 수 있습니다.예를 들어, df = pd.read_csv ('sample.csv', 구분자='; ') .
4.Pandas 데이터 프레임에서 문자열 열을 정수 열로 변환하려면 어떻게 해야 합니까?
A: read_csv () 함수에서 dtype 매개 변수를 사용하여 열의 데이터 유형을 지정할 수 있습니다.예를 들어, df = pd.read_csv ('sample.csv', dtype= {'Age': int}) .
5.CSV 파일을 R 데이터프레임으로 읽을 때 행과 헤더를 건너뛰려면 어떻게 해야 하나요?
A: read.csv () 함수에서 건너뛰기 및 헤더 매개 변수를 사용하여 행과 헤더를 각각 건너뛸 수 있습니다.예를 들어, df <- read.csv ('sample.csv', 건너뛰기=2, 헤더=거짓) .