Qwen3-VL: 고급 비전을 갖춘 오픈소스 멀티모달 AI

TL;DR — Qwen이 최신 open‑weight 비전‑언어 시리즈인 Qwen3‑VL을 공개했습니다. 플래그십 Qwen3‑VL‑235B‑A22B(Instruct + Thinking)는 Apache‑2.0 하에 공개되며, native 256K context(최대 1M까지 확장 가능), 더 강한 공간/비디오 추론, 32개 언어의 OCR을 제공합니다. 단순 인식이 아니라 더 깊은 멀티모달 추론과 agentic UI control까지 겨냥합니다. 모델이 매우 큽니다(가중치 약 471 GB) — 대부분의 팀은 API나 호스팅된 추론으로 시작할 것입니다. (GitHub (opens in a new tab))
무엇이 공개되었고(왜 중요한가)
Qwen3‑VL은 Qwen 팀의 최신 비전‑언어 계열입니다. 저장소와 모델 카드에는 텍스트 이해, 시각 지각/추론, 장문맥 비디오 이해, 그리고 에이전트 상호작용(예: PC/모바일 GUI 조작) 전반의 업그레이드가 강조되어 있습니다. 아키텍처 측면에서는 장기 비디오용 Interleaved‑MRoPE, 다단 ViT 융합을 위한 DeepStack, 정밀한 비디오 시간적 모델링을 위한 Text–Timestamp Alignment가 도입됩니다. (GitHub (opens in a new tab))
첫 공개 가중치는 ≈235B‑parameter MoE 모델(A22B = 토큰당 활성 전문가 약 22B)로, Instruct와 Thinking 에디션이 Apache‑2.0 라이선스로 제공됩니다. 이 모델은 STEM/멀티모달 추론, 공간 지각/2D–3D grounding, 장‑비디오 이해, 32개 언어의 OCR을 중점적으로 지원합니다. (Hugging Face (opens in a new tab))
출시일: Qwen은 Qwen3‑VL‑235B‑A22B Instruct 및 Thinking 가중치의 출시일을 2025년 9월 23일로 기재합니다. (GitHub (opens in a new tab))
주요 스펙 한눈에 보기
| 기능 | Qwen3‑VL 세부사항 |
|---|---|
| Open‑weight 버전 | 235B A22B Instruct 및 Thinking (Apache‑2.0) |
| 컨텍스트 길이 | native 256K, Qwen 가이드 기준 1M까지 확장 가능 |
| 비전/비디오 | 공간 추론 강화, 장‑비디오 시간적 grounding |
| OCR | 32개 언어, 저조도/블러/기울기에 강인 |
| Agentic | PC/mobile 작업을 위한 GUI 읽기와 액션 계획 가능 |
| 크기 | HF 카드 기준 ≈236B params; 커뮤니티 추산 가중치 약 471 GB |
| 프레임워크 지원 | 2025년 9월 중순 기준 공식 Transformers 통합 |
출처: 리포지토리+카드의 기능/에디션, 컨텍스트 길이와 agent 관련 주장; Transformers 통합은 HF 문서; 실제 가중치 크기 메모는 Simon Willison. (GitHub (opens in a new tab))
Qwen2.5‑VL 대비 무엇이 새로웠나?
- 더 날카로운 시간/공간 모델링: Interleaved‑MRoPE + Text–Timestamp Alignment로 기존 T‑RoPE 접근 대비 장‑비디오 전반의 이벤트를 더 정밀하게 로컬라이즈하는 것을 목표로 합니다. DeepStack은 정교한 이미지–텍스트 정렬을 강화합니다. (GitHub (opens in a new tab))
- 더 긴 컨텍스트와 더 넓은 모달리티 범위: 기본 256K 토큰에 1M 확장 경로; GUI, 문서, 장‑비디오 이해가 개선되었습니다. (GitHub (opens in a new tab))
- 더 큰, 추론 튜닝 에디션: Thinking 버전은 멀티모달 추론 과제를 겨냥합니다. 선택 벤치마크에서 일부 독점 멀티모달 베이스라인과 경쟁하거나 앞선다고 Qwen은 주장합니다(자가 보고). (Simon Willison’s Weblog (opens in a new tab))
Qwen의 블로그와 소셜 게시물은 지각 중심 벤치마크에서 Gemini 2.5 Pro와 동급/우위, 여러 멀티모달 추론 세트에서 SOTA를 주장합니다 — 독립 검증이 필요합니다. (Simon Willison’s Weblog (opens in a new tab))

릴리스 아티팩트와 실행 위치
-
GitHub: 코드 스니펫(Transformers), 쿠크북(OCR, grounding, 비디오, 에이전트). 논문은 “coming.” (GitHub (opens in a new tab))
-
Hugging Face:
- Qwen3‑VL‑235B‑A22B‑Instruct (Apache‑2.0) (Hugging Face (opens in a new tab))
- Qwen3‑VL‑235B‑A22B‑Thinking (Apache‑2.0) (Hugging Face (opens in a new tab))
-
Transformers 지원: Qwen3‑VL이 2025년 9월 중순에 Transformers docs에 반영되었습니다. (Hugging Face (opens in a new tab))
-
호스팅 옵션: OpenRouter가 API용 Qwen3‑VL 235B를 제공하며, Alibaba Cloud의 Model Studio는 Qwen‑Plus/Qwen3‑VL‑Plus API SKU를 thinking vs non‑thinking 모드 및 요금제로 제공합니다. (OpenRouter (opens in a new tab))
명명 관련 주의: HN 독자들이 Qwen3‑VL‑Plus(API)와 Qwen‑VL‑Plus(이전 시리즈)가 다르며, qwen‑plus‑2025‑09‑11 같은 스냅샷 네이밍이 초심자를 혼동시킨다고 지적합니다. 당신만 그런 게 아닙니다. (Hacker News (opens in a new tab))
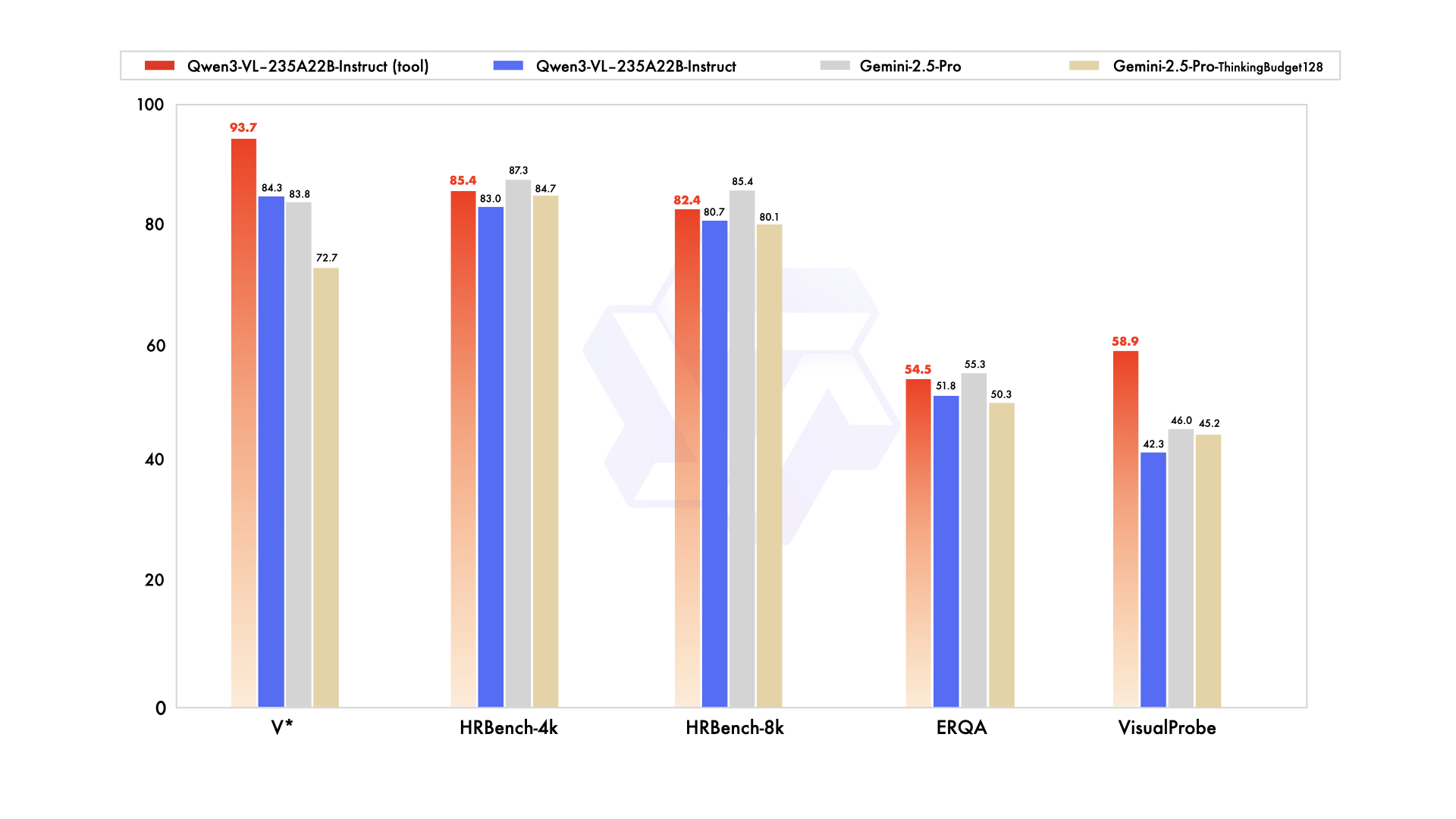
벤치마크(주의해서 읽기)
Qwen의 발표 채널은 Instruct가 지각 중심 테스트에서 Gemini 2.5 Pro를 “대등/상회”하고, Thinking이 여러 멀티모달 추론 스위트에서 SOTA라고 주장합니다. 이 수치는 자가 보고이며, 특히 데이터 큐레이션의 영향이 큰 chart/table 이해, diagram 추론, video QA에서는 독립 평가가 중요합니다. (Simon Willison’s Weblog (opens in a new tab))
한편 초기 커뮤니티 노트들은 공통 세트(e.g., HallusionBench, MMMU‑Pro, MathVision)에서 Qwen3‑Omni → Qwen3‑VL‑235B를 비교하며 유의미한 향상을 시사합니다 — 역시 아직 동료 평가 전입니다. (Reddit (opens in a new tab))
학계가 왜 Qwen을 선택해 왔고 Qwen3‑VL을 빠르게 도입할 가능성이 높은가
많은 비즈니스 앱이 편의성과 SLA 때문에 GPT/Claude/Gemini를 기본으로 삼지만, 연구 그룹에는 재현성, 감사, 어블레이션, 도메인 파인튜닝을 위한 open weights가 자주 필요합니다. Qwen의 카탈로그는 이를 쉽게 만들었습니다:
- 다양한 스케일의 open weights(소형 sub‑2B부터 235B+ MoE까지)로, 연구실 GPU에 맞춘 실험에서 시작해 나중에 확장 가능. (Qwen (opens in a new tab))
- 관대한 라이선스(Apache‑2.0 체크포인트 다수)로 학계/산업 협업 마찰을 줄임. (Hugging Face (opens in a new tab))
- 논문에서의 활용 입증: 예) BioQwen 생의학 바이링구얼 모델; Qwen2.5 베이스를 사용한 long CoT/domain merging 연구인 RCP‑Merging; 다수의 의료 VLM RL‑튜닝 연구가 Qwen2.5에서 출발. (ciblab.net (opens in a new tab))
Qwen3‑VL은 장‑비디오와 공간 grounding을 개선하면서도 open‑weight를 유지하므로, 문서 인텔리전스, 과학 다이어그램, 의료 VQA, embodied/agentic 연구에서 멀티모달 학술 프로젝트의 기본 베이스라인이 될 가능성이 큽니다.
프로덕트 팀을 위한 실전 안내
- 호스팅으로 시작하고 최적화로 전환: 플래그십 모델은 매우 큽니다(커뮤니티 메모: 가중치 약 471 GB). 멀티‑GPU(A100/H100/MI300) 클러스터가 없다면 API(OpenRouter, Alibaba Model Studio 등)로 시작하고, Qwen2.5‑VL이 72B/32B/7B/3B로 그랬듯 더 작은 Qwen3‑VL이 나오면 로컬/엣지 배포를 재검토하세요. (Simon Willison’s Weblog (opens in a new tab))
- “Thinking”이 항상 더 나은 건 아님: Qwen API는 thinking vs non‑thinking 모드로 토큰 예산과 가격이 다릅니다. 긴/모호한 멀티모달 과제에 한해 선택적으로 thinking을 쓰세요. (AlibabaCloud (opens in a new tab))
- 컨텍스트 비용 유의: 256K–1M context는 강력하지만 비쌉니다. 문서/비디오를 똑똑하게 청크하고, 프리‑파싱(OCR/layout)과 RAG로 프롬프트 팽창을 최소화하세요. (GitHub (opens in a new tab))
- Agentic UX: 스크린샷이나 화면 스트림에서 UI‑automation이 필요하다면 Qwen3‑VL의 비주얼 에이전트 기능을 파일럿해 볼 가치가 있습니다. 다만 견고한 tool API와 가드레일에 투자하세요. (GitHub (opens in a new tab))
퀵스타트(Transformers)
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor # HF >= 4.57
model_id = "Qwen/Qwen3-VL-235B-A22B-Instruct" # or ...-Thinking
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(model_id, dtype="auto", device_map="auto")
processor = AutoProcessor.from_pretrained(model_id)
messages = [{"role": "user", "content": [
{"type": "image", "image": "https://.../app-screenshot.png"},
{"type": "text", "text": "What button should I tap to turn on dark mode? Explain briefly."}
]}]
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(processor.batch_decode(outputs[:, inputs["input_ids"].shape[1]:], skip_special_tokens=True)[0])이는 Qwen의 model‑card 예제를 반영합니다(가능하다면 FlashAttention‑2 활성화). 다중 이미지나 video의 경우, 여러 {"type": "image"} 항목을 전달하거나 저장소에 보인 대로 프레임/픽셀 제어와 함께 {"type": "video"} 항목을 사용하세요. (Hugging Face (opens in a new tab))
자주 겪는 함정과 주의점
- 네이밍 드리프트: “Qwen3‑VL‑Plus”(API) vs. “Qwen‑VL‑Plus”(이전 open‑weight 라인)는 동일하지 않습니다. 실제로 로드하는 Model Studio 문서와 HF 페이지를 확인하세요. (Hacker News (opens in a new tab))
- 메모리 착시: 235B MoE는 open weights이지만, “MoE”가 곧 추론 시 작아진다는 뜻은 아닙니다. 메모리와 대역폭을 충분히 예산하세요. 커뮤니티는 가중치를 약 471 GB로 봅니다. (Simon Willison’s Weblog (opens in a new tab))
- 자가 보고 리더보드: 마케팅 차트는 가설로 취급하세요. 특히 charts/tables, 문서, video QA에 대해 자체 평가를 재실행하세요.
FAQ
Q: Qwen3‑VL‑235B‑A22B에서 “A22B”는 무엇을 의미하나요? A: Mixture‑of‑Experts 모델로 총 파라미터는 약 235B이며, 토큰당 활성 파라미터는 약 22B입니다 — 연산 효율과 용량을 절충합니다. (Qwen (opens in a new tab))
Q: Instruct vs Thinking — 언제 무엇을 고를까요? A: Instruct는 일반 용도 정렬로 보통 더 빠르고 저렴합니다. Thinking은 내부 추론 트레이스(API는 “thinking mode” 제공)를 포함해 구성적/장기 과제에 도움이 될 수 있으나 토큰 비용이 큽니다. 자체 평가셋에서 둘 다 시도해 보세요. (Hugging Face (opens in a new tab))
Q: 정말 Gemini 2.5 Pro보다 “더 낫다”고 할 수 있나요? A: Qwen은 선택된 지각 벤치마크에서의 승리와 여러 멀티모달 과제에서의 SOTA를 주장하지만, 이는 자가 보고입니다. 독립 비교에는 시간이 걸립니다 — 커뮤니티 평가와 당신의 도메인별 테스트를 주시하세요. (Simon Willison’s Weblog (opens in a new tab))
Q: 로컬 실행이 가능한가요? A: 고사양 하드웨어(대용량 RAM의 멀티‑GPU)가 있다면 가능합니다. 대부분의 팀은 먼저 호스팅 추론(OpenRouter, Model Studio 등)을 사용할 것입니다. 소규모 로컬 실험은 더 작은 Qwen3‑VL이 나올 때까지 기존 Qwen2.5‑VL(72B/32B/7B/3B)을 고려하세요. (OpenRouter (opens in a new tab))
Q: 라이선스는 어떻게 되나요? A: 공개된 Qwen3‑VL‑235B‑A22B 가중치는 HF 모델 카드 기준 Apache‑2.0입니다. 항상 특정 체크포인트의 라이선스를 확인하세요. (Hugging Face (opens in a new tab))
Q: 연구자들이 계속 Qwen을 선택하는 이유는? A: 다양한 사이즈의 open weights, 관대한 라이선스, 강력한 다국어 능력 — 그리고 BioQwen, long‑CoT 모델 머징, Qwen2.5 기반 의료 VQA RL‑튜닝 등 Qwen 기반 파인튜닝 사례가 풍부하기 때문입니다. (ciblab.net (opens in a new tab))
커뮤니티 반응과 토론
Hacker News 스레드에서는 빠르게 네이밍 혼동(Qwen3‑VL‑Plus vs qwen‑plus‑2025‑09‑11 같은 스냅샷)과 실전 배포 질문이 제기되었지만, open‑weight 릴리스의 속도에 대한 기대도 큽니다. 초기 수용자 정서를 엿볼 수 있습니다. (Hacker News (opens in a new tab))
개발자 커뮤니티의 간결한 요약은 Simon Willison의 노트를 참고하세요 — 모델 크기에 대한 현실 점검과 향후 더 작은 버전의 등장 속도를 가늠하는 데 유용합니다. (Simon Willison’s Weblog (opens in a new tab))
최종 정리
Qwen3‑VL은 “이 이미지를 인식하라”를 넘어 이미지, 문서, 비디오 전반에서 “추론하고 행동하라”로 확장하며, 익숙한 오픈 툴링 스택(Transformers)에 안착한 open‑weight 멀티모달 모델의 기준을 끌어올립니다. 연구용으로는 분명한 신규 베이스라인입니다. 프로덕트 팀에는 플래그십이 당장 자체 호스팅하기엔 너무 크지만, API를 통해 문서 인텔리전스, 화면 이해, video QA에서 즉각적인 가치를 제공합니다. Qwen2.5의 전례처럼 더 작은 Qwen3‑VL이 뒤따를 때 진짜 변곡점이 올 것입니다.
참고 및 추가 읽을거리
- Repo: QwenLM/Qwen3‑VL — 기능, 아키텍처 노트, 쿠크북, 릴리스 로그. (GitHub (opens in a new tab))
- Model cards: Instruct와 Thinking(Apache‑2.0), 퀵스타트와 성능 차트 포함. (Hugging Face (opens in a new tab))
- Transformers docs: Qwen3‑VL 통합. (Hugging Face (opens in a new tab))
- Qwen3 overview & MoE sizes(A22B 설명, open‑weighted 라인업). (Qwen (opens in a new tab))
- HN discussion: 커뮤니티 인상과 네이밍 혼란. (Hacker News (opens in a new tab))
- API/pricing: Alibaba Cloud Model Studio(thinking vs non‑thinking, 토큰 예산). (AlibabaCloud (opens in a new tab))
- Qwen을 활용한 연구 예시: BioQwen; RCP‑Merging; Qwen2.5 기반 의료 VQA RL‑튜닝. (ciblab.net (opens in a new tab))