R에서 로지스틱 회귀 방정식: 예제로 이해하기
- Name
- Rajiv Chandra
업데이트
로지스틱 회귀는 이진 분류 문제에 사용되는 가장 대중적인 통계 기술 중 하나입니다. 로지스틱 함수를 사용하여 종속 변수와 하나 이상의 독립 변수 간의 관계를 모델링합니다. 로지스틱 회귀의 목표는 입력 기능과 출력 변수 간의 최상의 관계를 찾는 것입니다. 이 글에서는 R에서 예제와 함께 로지스틱 회귀 방정식을 설명합니다.
Python Pandas 데이터프레임에서 코드 없이 데이터 시각화를 빠르게 생성하려면?
PyGWalker는 시각화와 함께 탐색적 데이터 분석을 위한 Python 라이브러리입니다. PyGWalker (opens in a new tab)는 pandas 데이터프레임 (그리고 polars 데이터프레임)을 Tableau 스타일의 사용자 인터페이스로 변환하여 데이터 분석 및 데이터 시각화 워크플로우를 단순화할 수 있습니다.

로지스틱 회귀 방정식
로지스틱 회귀 방정식은 다음과 같이 정의할 수 있습니다:
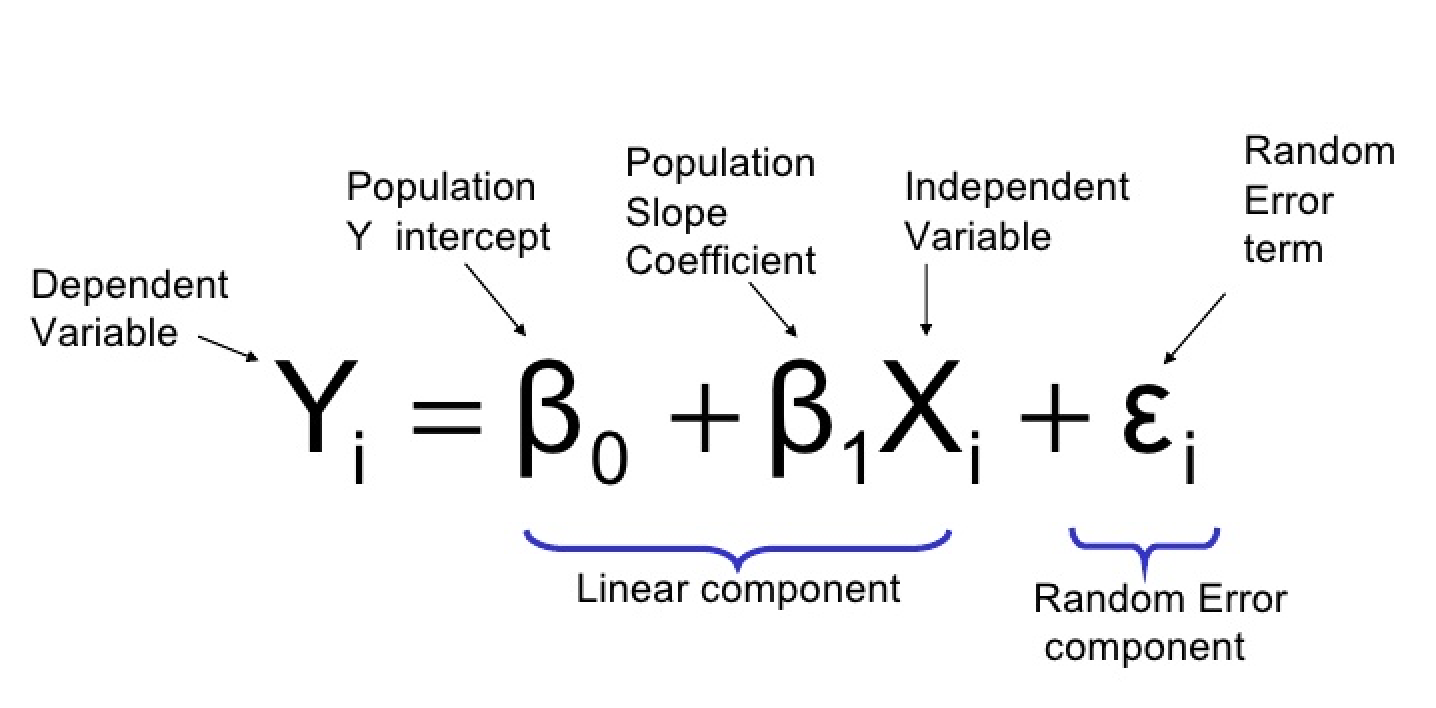
여기서:
- Y: 종속 변수 또는 응답 변수 (이진)
- X1, X2, …, Xp: 독립 변수 또는 예측 변수
- β0, β1, β2, …, βp: 베타 계수 또는 모델 매개 변수
로지스틱 회귀 모델은 베타 계수 값을 추정합니다. 베타 계수는 해당 독립 변수가 1 단위 변경될 때 종속 변수의 로그 오즈(log-odds)가 변경되는 양을 나타냅니다. 로지스틱 함수(시그모이드 함수라고도 함)는 그런 다음 로그 오즈를 0과 1 사이의 확률로 변환합니다.
R에서 로지스틱 회귀 적용하기
이 절에서는 RSample 패키지에서 hr_analytics 데이터셋을 사용하여 로지스틱 회귀 모델을 구축하고 훈련하는 데 glm() 함수를 사용합니다.
데이터 로딩
먼저 필요한 패키지와 데이터셋을 불러옵니다:
library(RSample)
data(hr_analytics)hr_analytics 데이터셋은 특정 회사의 직원에 대한 정보를 포함하며, 그들의 나이, 성별, 교육 수준, 부서, 그리고 회사에서 떠난 여부를 포함합니다.
데이터 준비
우리는 대상 변수 left_company를 이진 변수로 변환합니다:
hr_analytics$left_company <- ifelse(hr_analytics$left_company == "Yes", 1, 0)다음으로, 데이터셋을 훈련 셋과 테스트 셋으로 분할합니다:
set.seed(123)
split <- initial_split(hr_analytics, prop = 0.7)
train <- training(split)
test <- testing(split)모델 구축
glm() 함수를 사용하여 로지스틱 회귀 모델을 적합시킵니다:
logistic_model <- glm(left_company ~ ., data = train, family = "binomial")이 예제에서는 독립 변수(age, gender, education, department)를 모두 사용하여 종속 변수(left_company)를 예측합니다. family 인수는 적합할 모델의 유형을 지정합니다. 이진 분류 문제를 다루기 때문에 family를 "binomial"로 지정합니다.
모델 평가
모델의 성능을 평가하기 위해 summary() 함수를 사용합니다:
summary(logistic_model)출력 결과:
Call:
glm(formula = left_company ~ ., family = "binomial", data = train)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.389 -0.640 -0.378 0.665 2.866
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.721620 0.208390 -3.462 0.000534 ***
age -0.008328 0.004781 -1.742 0.081288 .
genderMale 0.568869 0.086785 6.553 5.89e-11 ***
educationHigh School 0.603068 0.132046 4.567 4.99e-06 ***
educationMaster's -0.175406 0.156069 -1.123 0.261918
departmentHR 1.989789 0.171596 11.594 < 2e-16 ***
departmentIT 0.906366 0.141395 6.414 1.39e-10 ***
departmentSales 1.393794 0.177948 7.822 5.12e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 6589.7 on 4799 degrees of freedom
Residual deviance: 5878.5 on 4792 degrees of freedom
AIC: 5894.5
Number of Fisher Scoring iterations: 5출력 결과는 모델의 계수(beta 계수), 해당 계수들의 표준 오차, z-값, p-값 등을 보여줍니다. 계수들은 다음과 같이 해석할 수 있습니다:
- p-값이 유의수준 (p < 0.05)보다 작은 계수들은 통계적으로 유의미하며 결과에 큰 영향을 미칩니다. 해당 예제에서는 age, gender, education, and department가 직원의 이직 여부를 예측하는 데 유의미한 예측 변수입니다.
- p-값이 유의수준보다 큰 계수들은 통계적으로 유의하지 않으며 결과에 큰 영향을 미치지 않습니다. 해당 예제에서는 education level(Master's)이 유의하지 않은 예측 변수입니다.
예측하기
새로운 데이터에 대해 예측하기 위해 predict() 함수를 사용합니다:
predictions <- predict(logistic_model, newdata = test, type = "response")newdata 인수는 우리가 예측하려는 새 데이터를 지정합니다. type 인수는 우리가 원하는 출력 형식을 지정합니다. 이진 분류를 다루고 있으므로 타입으로 "response"를 지정합니다.
예측 평가
마지막으로, 혼동 행렬을 사용하여 예측을 평가합니다.
table(Predicted = ifelse(predictions > 0.5, 1, 0), Actual = test$left_company)출력:
Actual
Predicted 0 1
0 1941 334
1 206 419혼동 행렬은 참긍정, 거짓긍정, 참부정 및 거짓부정의 수를 보여줍니다. 이러한 값을 사용하여 정확도, 재현율 및 F1 점수와 같은 성능 평가 지표를 계산할 수 있습니다.
결론
이 문서에서는 로지스틱 회귀 방정식 및 독립 변수와 종속 이진 변수 간의 관계를 모델링하는 데 사용되는 방법에 대해 논의했습니다. glm() 함수를 사용하여 R에서 샘플 데이터 집합을 기반으로 로지스틱 회귀 모델을 구축, 학습 및 평가하는 방법도 설명했습니다. 로지스틱 회귀는 이진 분류 문제에서 강력한 기술이며 머신 러닝에서 널리 사용됩니다.