Python向けオープンソースのDataFrameライブラリ トップ9

Pythonは、開発者やデータ愛好家にとって定番の言語として定着しています。データ処理におけるその人気の主要な理由は、特にDataFramesに焦点を当てた膨大なライブラリエコシステムにあります。これらの強力なテーブル状の構造は、構造化データの簡単な操作や分析を可能にし、データセットを扱う人々にとって欠かせないものとなっています。
Pythonを使ってデータ分析を行ったことがあるなら、最も有名で愛されているDataFrameライブラリであるPandasに遭遇したことがあるでしょう。しかし、データが大きく複雑になるにつれて、スケール、速度、パフォーマンスの課題に対処するために新しいライブラリが登場しました。この記事では、Pythonで最も人気のあるオープンソースのDataFrameライブラリをいくつか紹介し、それぞれの独自の特徴を探りながらデータを最大限に活用する方法を探ります。
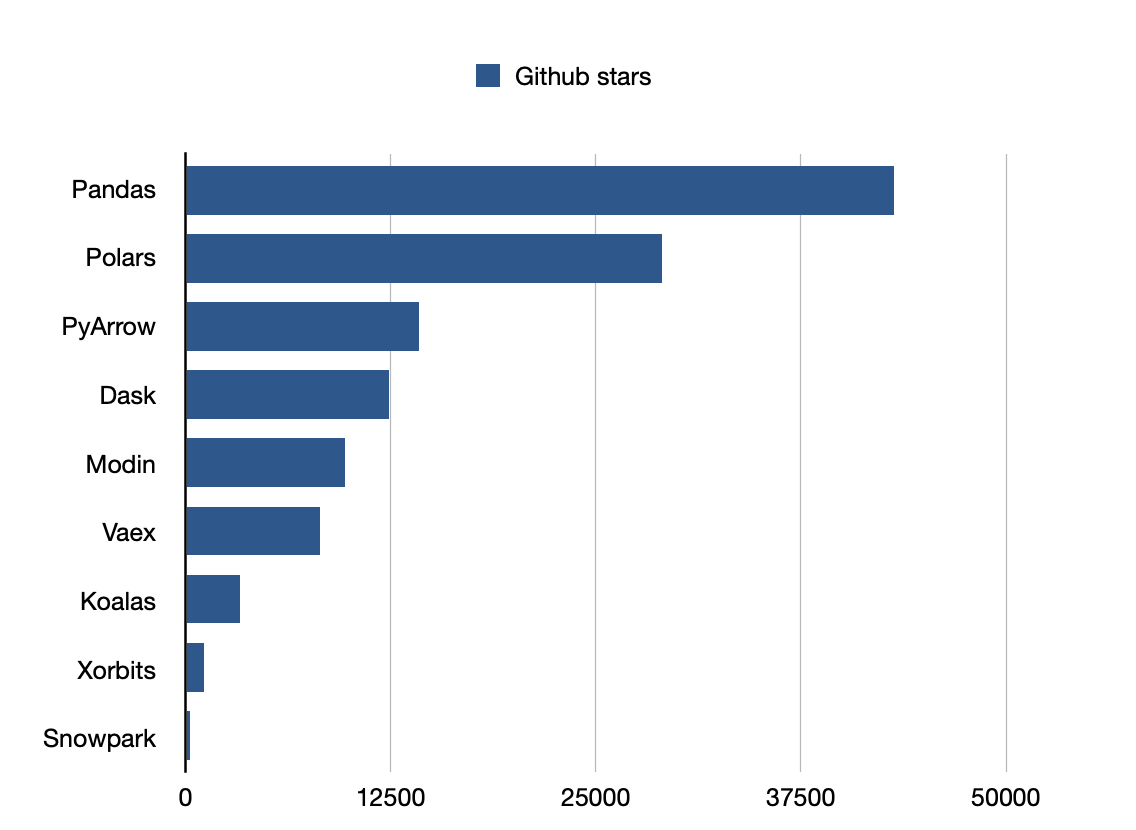
Pandasは最も人気のあるライブラリです。
1. Pandas: データサイエンスのベテラン
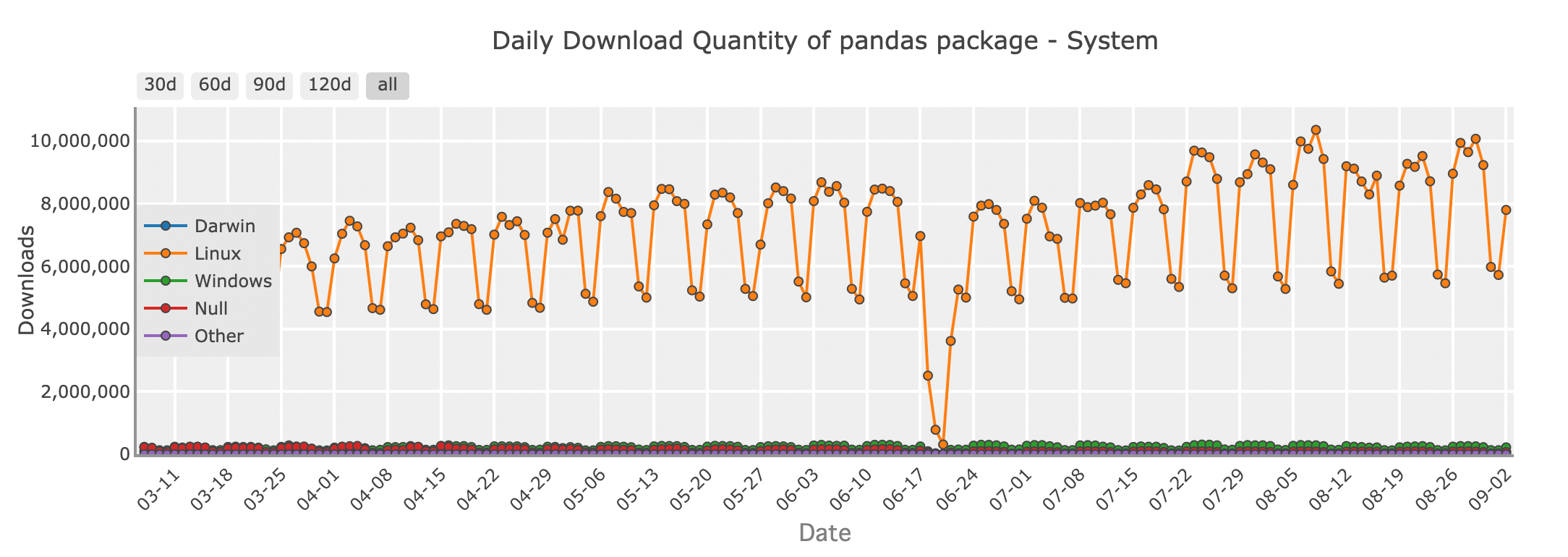
Pandasパッケージの日次ダウンロード量 - system
多くのPython開発者にとって、PandasはDataFramesを扱う際に最初に思い浮かぶライブラリです。その豊富な機能セットと直感的なAPIにより、データのロード、操作、分析が容易になります。例えば、乱雑なデータセットのクリーンアップ、複数のソースからのデータ統合、統計分析の実行など、Pandasは使い慣れたスプレッドシートのような形式でこれらすべてのツールを提供します。
import pandas as pd
# DataFrameを作成
data = {
'Name': ['Amy', 'Bob', 'Cat', 'Dog'],
'Age': [31,27,16,28],
'Department': ['HR', 'Engineering', 'Marketing', 'Sales'],
'Salary': [70000, 80000, 60000, 75000]
}
df = pd.DataFrame(data)
# DataFrameの表示
print(df)Pandasは、コンピュータのメモリに快適に収まる小規模から中規模のデータセットの処理に優れています。日常的なデータタスクから、Jupyterノートブックでのデータ探索、より複雑なパイプラインの構築に最適です。ただし、データセットが大きくなるとPandasの限界が見えてくるかもしれません。そんな時に他のDataFrameライブラリが役立ちます。
Github stars: 43200
2. Modin: Pandasの新たな高みにスケール
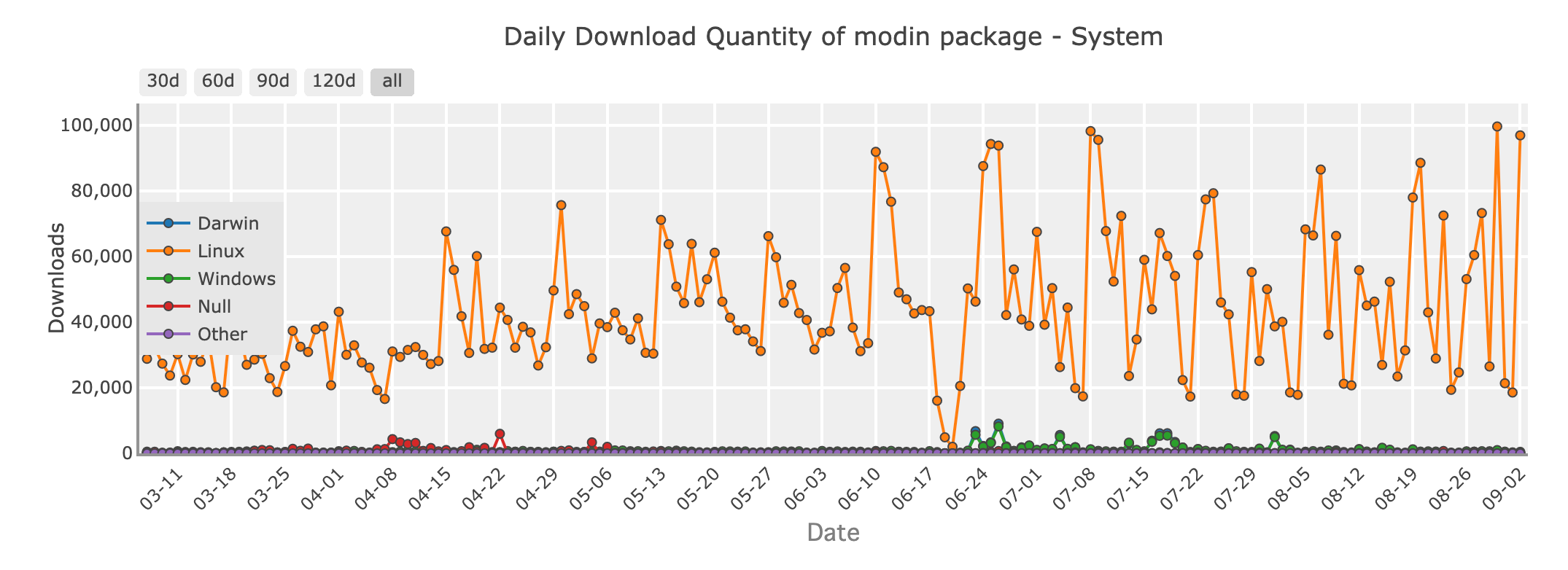
Modinパッケージの日次ダウンロード量 - system
もし、データセットが大きすぎてPandasで効率的に処理できない場合、コードベースを全面的に書き換えたくはないけれど、速度とスケーラビリティが必要だとしたら、Modinが登場します。
ModinはPandasのドロップイン置換として設計されているため、既存のPandasコードをわずかにインポート文を変更するだけで並列実行可能にします。バックグラウンドでは、ModinはRayやDaskといった強力なフレームワークを使用して計算を複数のコアやマシンのクラスターに分散します。これによりデータ操作の処理時間が速くなります。
Modinを使用すると、従来のPandas APIを利用しつつ、大きなデータセットを処理し、ハードウェアの性能を最大限に引き出すことができます。
Github stars: 9700
3. Polars: スピードと効率の再定義
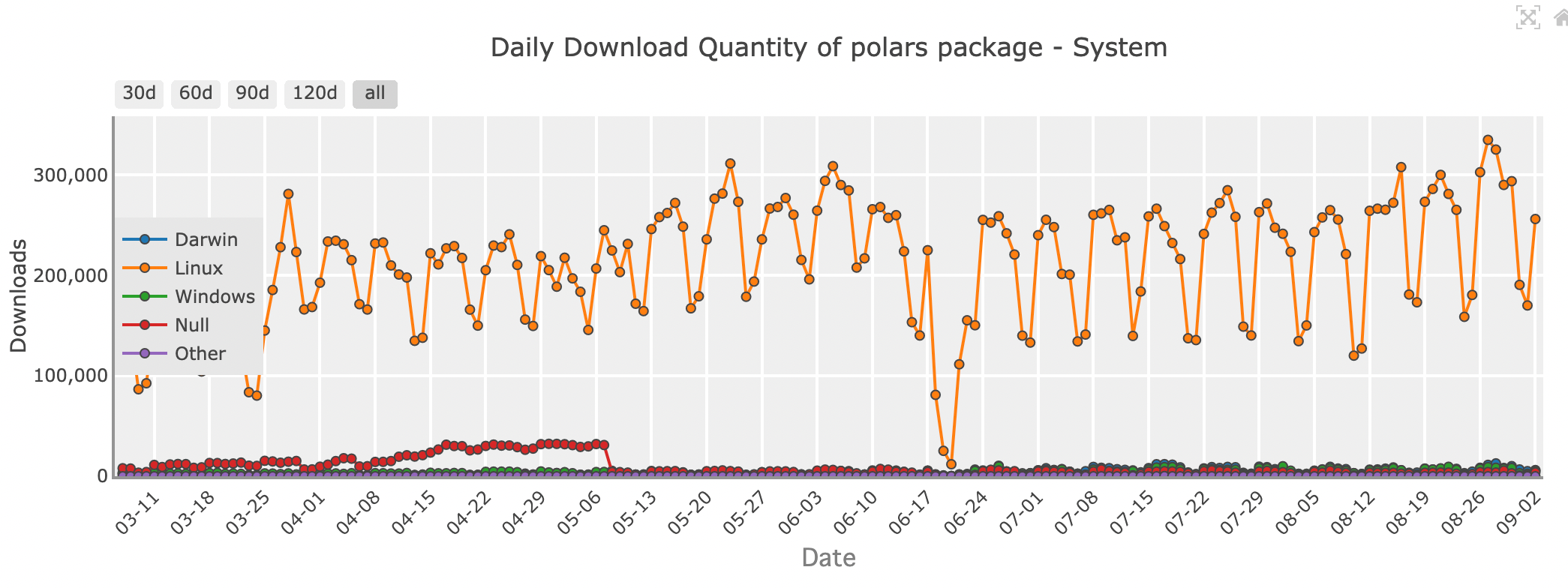
Polarsパッケージの日次ダウンロード量 - system
生のスピードと効率に関しては、Polarsがデータサイエンスコミュニティで注目を集めています。Rustで書かれたPolarsは、そのパフォーマンスと安全性で知られるプログラミング言語の利点を生かしています。大規模なデータセットを扱ったり、複雑な操作を迅速に実行する必要がある場合、Polarsが適しているかもしれません。
Polarsは遅延評価という手法を採用しており、必要なときにだけ操作を実行します。これにより、計算パイプライン全体を最適化し、必要最小限の時間とリソースで済ませることができます。さらに、Polarsはマルチスレッドを念頭に設計されているため、マシンのすべてのコアを効率的に利用でき、パフォーマンスが重要なタスクに最適です。
Polarsはその速度に驚かされますが、慣れるまでには学習曲線があります。PandasとはAPIが異なるため、少し時間がかかるかもしれません。しかし、時間をかける価値があると感じたなら、他のライブラリでは不可能なパフォーマンスとデータセット処理能力を提供します。
Github stars: 29000
| 機能/側面 | Pandas | Modin | Polars |
|---|---|---|---|
| アーキテクチャ | シングルスレッド、Python/Cython | マルチスレッド、分散 (Ray/Dask) | マルチスレッド、Rustで記述 |
| パフォーマンス | 小規模から中規模のデータセットに適している | 複数のコアやクラスターにスケール | 非常に高速、大規模データセットに対応 |
| メモリ使用量 | 高メモリ使用量 | Pandasと類似 | 低メモリ使用量、out-of-coreサポート |
| 使いやすさ | 非常に使いやすい、広範なコミュニティサポート | Pandasからの移行が容易 | 直感的だが異なるAPI |
| エコシステム | 成熟し、他のライブラリと統合が進んでいる | Pandasエコシステムと互換性あり | 小規模エコシステムだが成長中 |
| 使用ケース | 小規模から中規模のデータセット、データ操作 | 大規模データセット、Pandas操作のスケーリング | 高性能コンピューティング、大規模データセット |
| インストール | pip install pandas | pip install modin[all] | pip install polars |
4. Dask: 大規模データ用の分散DataFrame
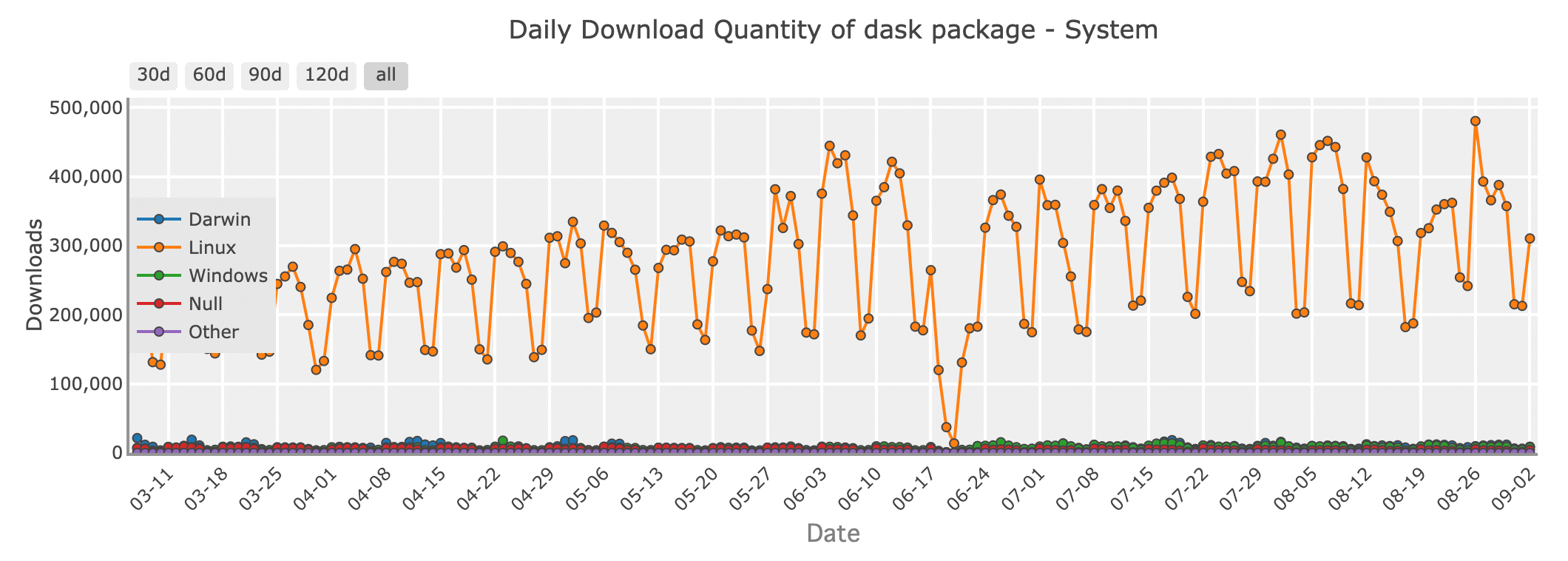
Daskパッケージの日次ダウンロード量 - system
データが大きくなってメモリに収まらなくなったとき、Daskがその強力なアシスタントとして活躍します。Daskは、PandastypeAPIを拡張し、1つのマシンに収まりきらないデータセットを扱うことができる並列計算ライブラリです。
Daskは大規模なDataFrameを小さなチャンクに分割し、ローカルマシンやクラスター全体で並行に処理します。これにより、メモリが足りなくなる心配をせずに計算をスケールさせることができます。大規模データの処理や、数千のタスクにスケールするデータパイプラインの構築には、Daskが提供する柔軟性とパワーが欠かせません。
Github stars: 12400
5. PyArrow: Apache Arrowによる高速データ交換
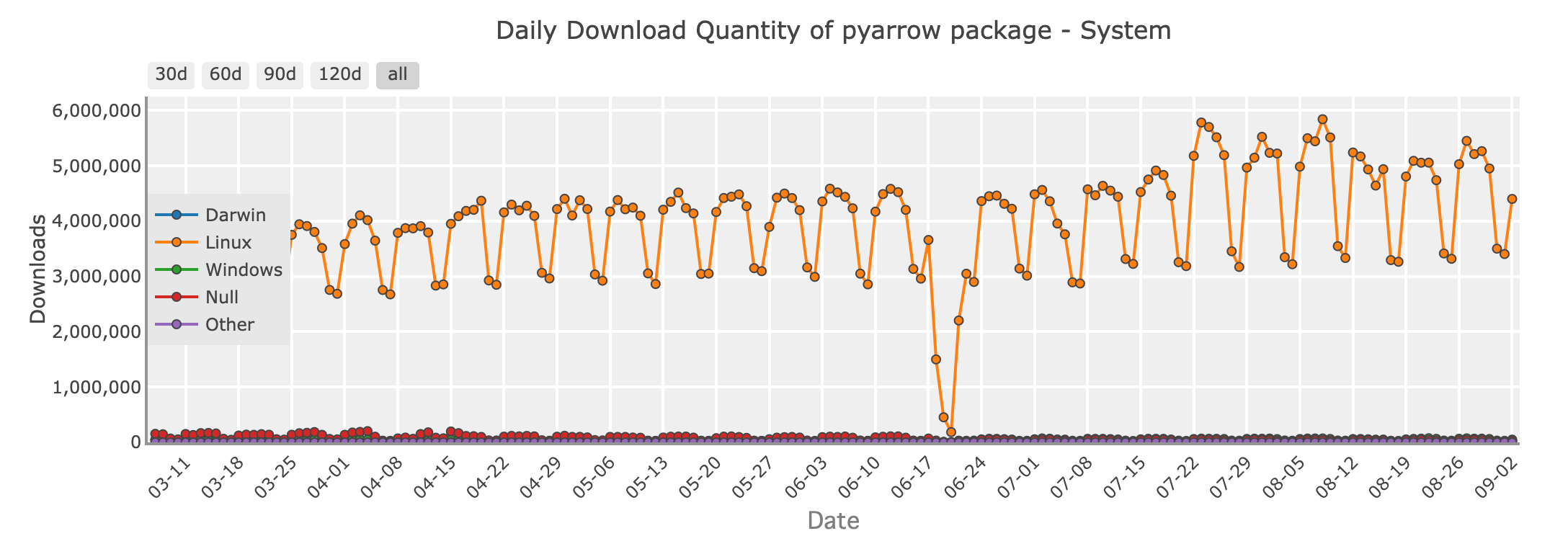
PyArrowパッケージの日次ダウンロード量 - system
データエンジニアリングの分野では、PyArrowは効率的なデータ交換のための重要なライブラリとして輝いています。Apache Arrowフォーマットの上に構築されたPyArrowは、大規模データセットに対してゼロコピー読み取りを可能にする素晴らしいカラムナメモリフォーマットを提供します。これにより、パフォーマンスと相互運用性が重要なシナリオで選ばれることが多いです。
PyArrowはPython、R、Javaなどの言語間で高速なデータ転送を可能にし、多くの大規模データ処理フレームワークで重要な役割を果たしています。特にデータを異なるツールやプラットフォーム間で共有する必要がある大規模データパイプラインを扱う際には、PyArrowが強力なツールとなります。
Github stars: 14200
6. Snowpark: SnowflakeによるクラウドでのDataFrame操作
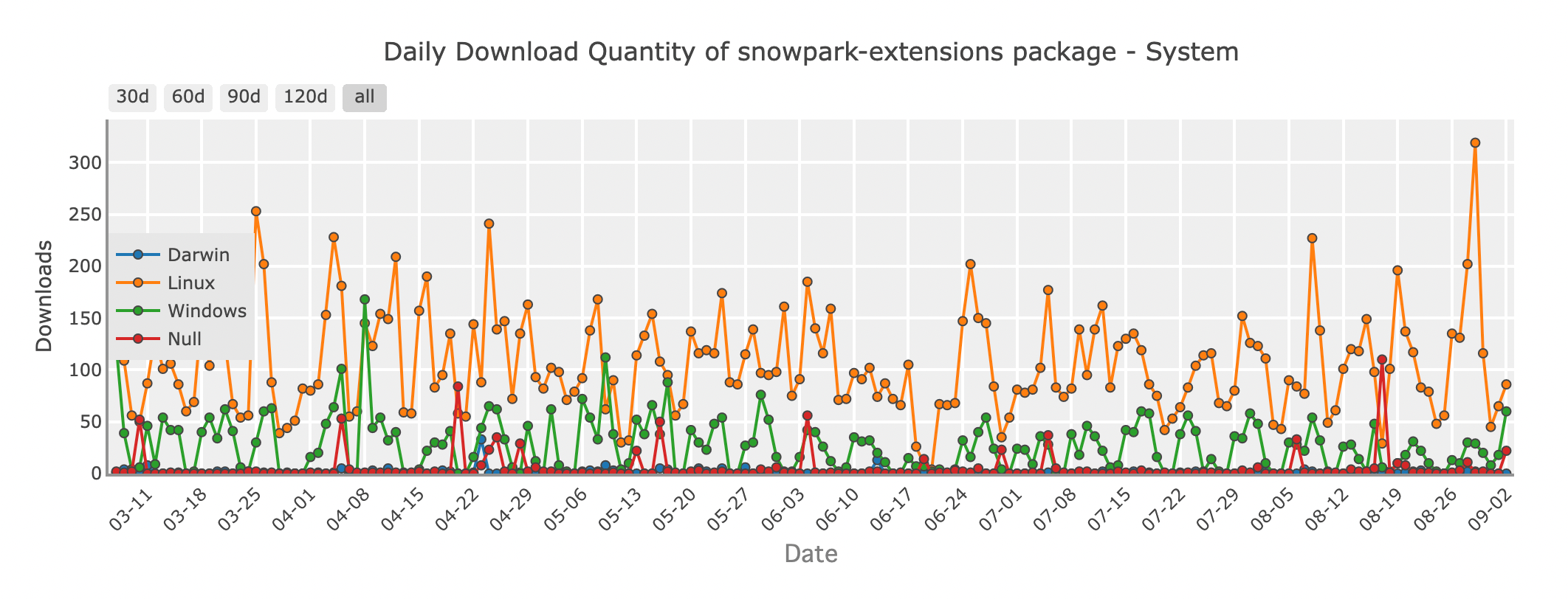
Snowparkパッケージの日次ダウンロード量 - system
多くの組織がデータ業務をクラウドに移行する中で、SnowparkはPython開発者のための革新的なソリューションとして登場しました。Snowparkは、クラウドベースのデータウェアハウスであるSnowflakeの機能の1つで、Snowflake環境内でDataFrameスタイルの操作を直接行うことができます。これにより、データをSnowflakeから移動せずに複雑なデータ変換や分析を行うことができ、待ち時間を減らし効率を高めます。
Snowparkを使用すると、Pythonコードを記述し、Snowflakeのインフラストラクチャ上でネイティブに実行させることができ、クラウドのパワーを活用して大規模データセットを楽に処理できます。すでにSnowflakeを使用しているチームにとって、データ処理ワークフローを合理化するのに最適な選択です。
Github stars: 253
7. Xorbits: データサイエンスのスケーリングのための統一ソリューション
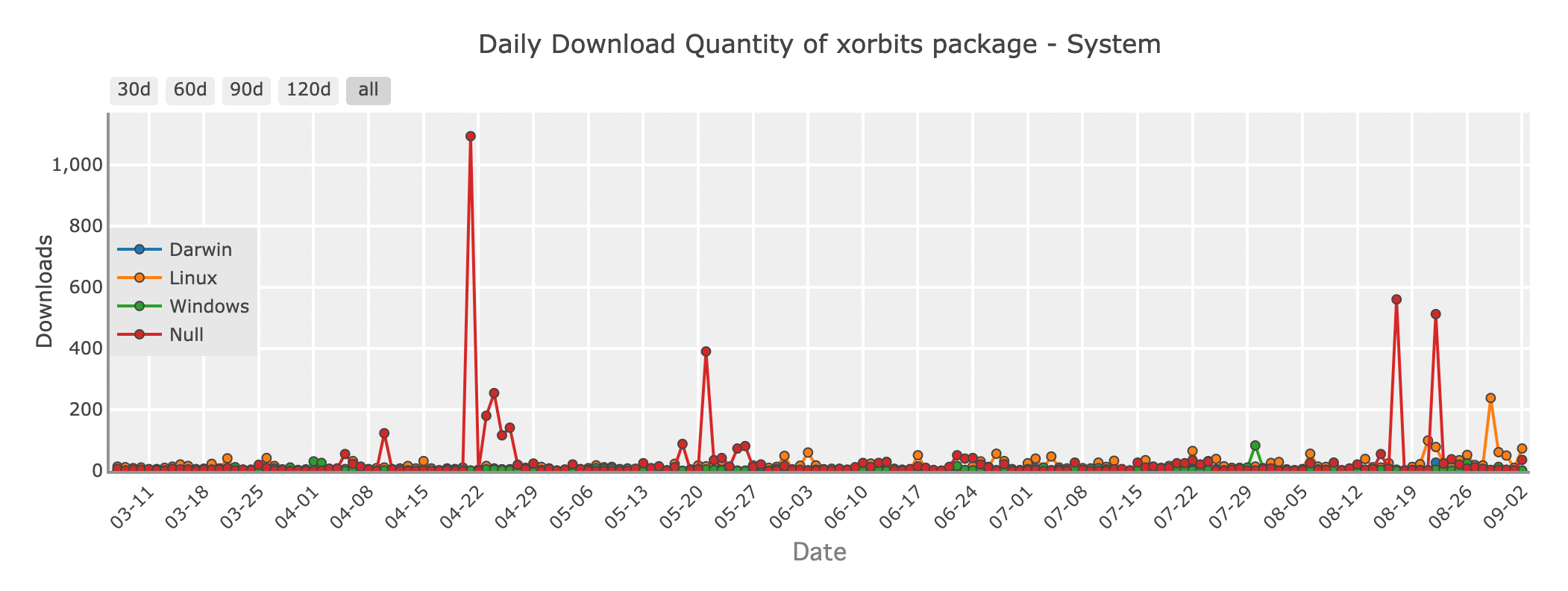
Xorbitsパッケージの日次ダウンロード量 - system
Xorbitsは、分散環境でデータサイエンス操作をスケールするために設計された強力なフレームワークです。分散コンピューティングの複雑さを抽象化する統一APIを提供し、基礎的なインフラストラクチャを気にせずにDataFrame操作を複数のノードにわたってスケールできます。
XorbitsはPandas、Dask、PyTorchなどの既存ツールと簡単に統合でき、機械学習やデータサイエンスのアプリケーションに柔軟性を提供します。大規模なモデルのトレーニングや大量のデータ処理が必要な場合、Xorbitsはフレキシビリティとパワーを提供します。
Github stars: 1100
8. Vaex: 効率的な分析のためのアウト・オブ・コアDataFrame
Vaexパッケージの日次ダウンロード量 - system
もし、システムのメモリを超える巨大なデータセットを扱いながらも、Pandasのシンプルさを維持したいなら、Vaexを試してみる価値があります。Vaexはアウト・オブ・コア計算を目的としています。これは、データを一度にすべてメモリにロードするのではなく、チャンク単位で処理することを意味します。
Vaexは速度に最適化されており、高速なフィルタリング、グルーピング、集計といった機能を低メモリ使用量で提供します。特にデータ探索や統計分析、さらには大規模データセット上での機械学習などに役立ちます。
Github stars: 8200
9. Koalas: Apache Sparkを使ったPandasの大規模データ対応
