Pandasのデータ可視化:ステップバイステップのチュートリアル
- Name
- Rajiv Chandra
更新日
PythonのPandasライブラリは、データサイエンティストやアナリストが世界中で日常的に使用する強力なツールです。その中でも最も魅力的な機能の1つは、堅牢なデータ可視化機能です。この記事では、Pandasを使用して魅力的なプロットを作成するプロセスを案内し、生データを洞察に富んだチャートに変換するためのスキルを提供します。
Pandasのプロットは、単にデータをきれいに見せるためのものではありません。数字の中に隠れたストーリーを解き放つことが目的です。新しいデータセットを探索したり、最新の発見結果を共有する準備をする場合には、可視化がデータ駆動型の洞察を伝える上で重要です。
まずは、より詳細な説明とサンプルコードスニペットで、各セグメントにより深く入り込んでみましょう。
Pandasのデータ可視化におけるプロット関数の使用
Pandasは、可視化に非常に適した高レベルで柔軟なデータ構造であるDataFrameを提供しています。 .plot() 関数を使うことで、ライン、バー、スキャッターなどさまざまなプロットを生成することができます。この関数は、汎用的なMatplotlibライブラリのラッパーであり、複雑な可視化をより簡単に作成することができます。
たとえば、Pandasの使用を始めたばかりの場合、データの有益なトレンドを明らかにする基本的なラインプロットをすぐに作成することができます。ラインプロットは、時間にわたるデータの表示に優れており、時系列データ分析に最適です。
以下に、Pandasでラインプロットを作成する簡単な例を示します。
import pandas as pd
import numpy as np
# DataFrameの作成
df = pd.DataFrame({
'A': np.random.rand(10),
'B': np.random.rand(10)
})
df.plot(kind='line')このコードでは、まず必要なライブラリをインポートします。次に、2つの列を持つDataFrameを作成し、それぞれの列にランダムな数値を埋めます。最後に、 .plot() 関数を使用してラインプロットを作成します。
ただし、コードなしでPandasのデータフレームをプロットするためのビジュアルUIを使用したい場合はどうでしょうか。幸いにも、この問題を解決するためのPandasデータフレームがあります。
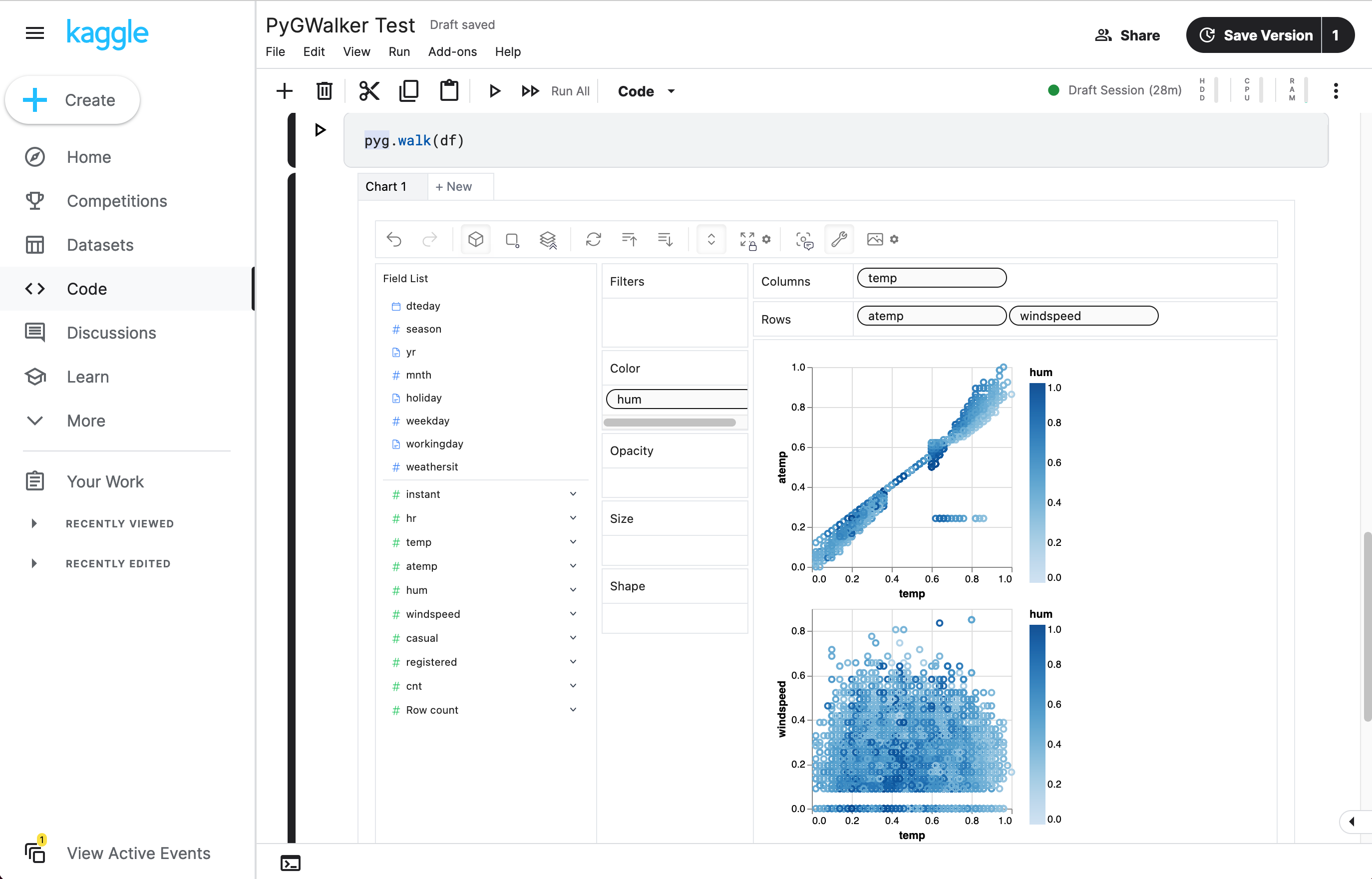
Pandasのデータ可視化におけるPyGWalkerの使用
PyGWalkerは、探索的データ分析と簡単なデータ可視化向けに設計されたPythonライブラリです。Jupyter Notebook内でオープンソースのTableauを実行しているようなものと考えてください。複雑なコーディングチュートリアルを確認する代わりに、変数をドラッグアンドドロップするだけで簡単に可視化を作成できます。
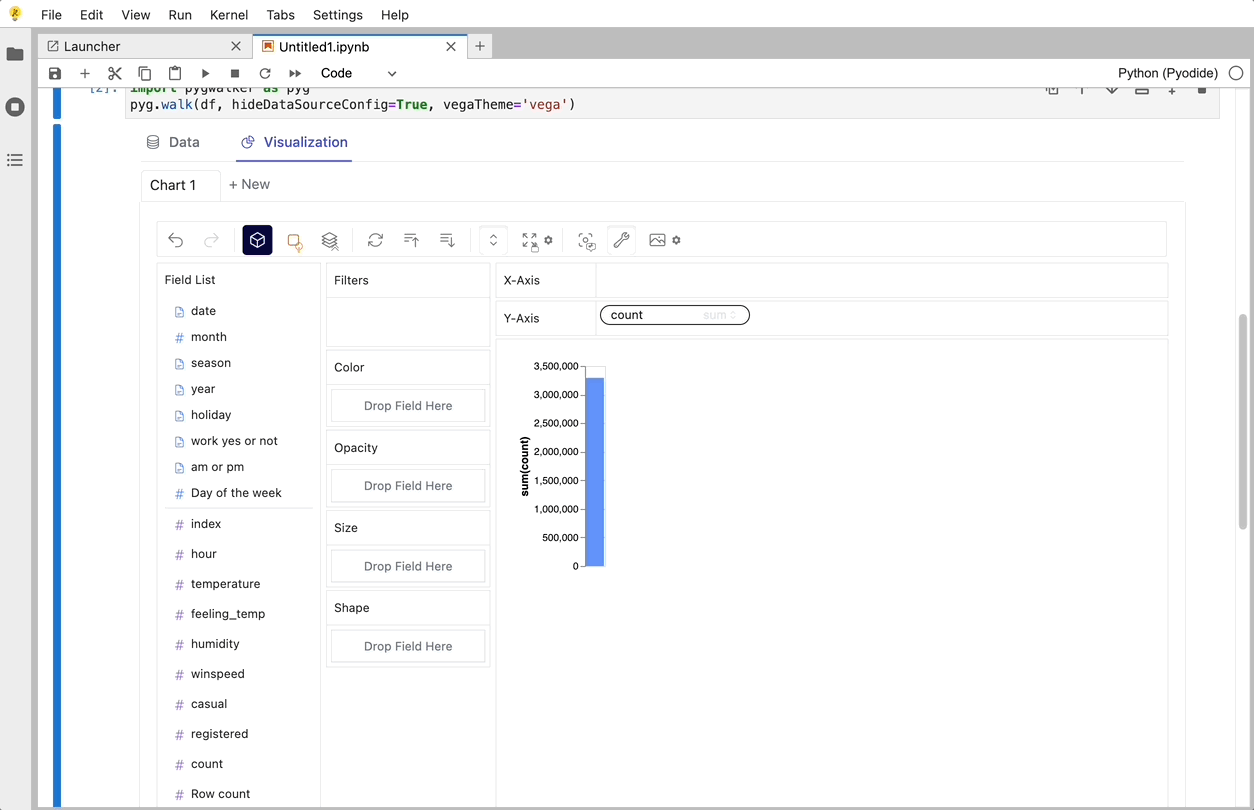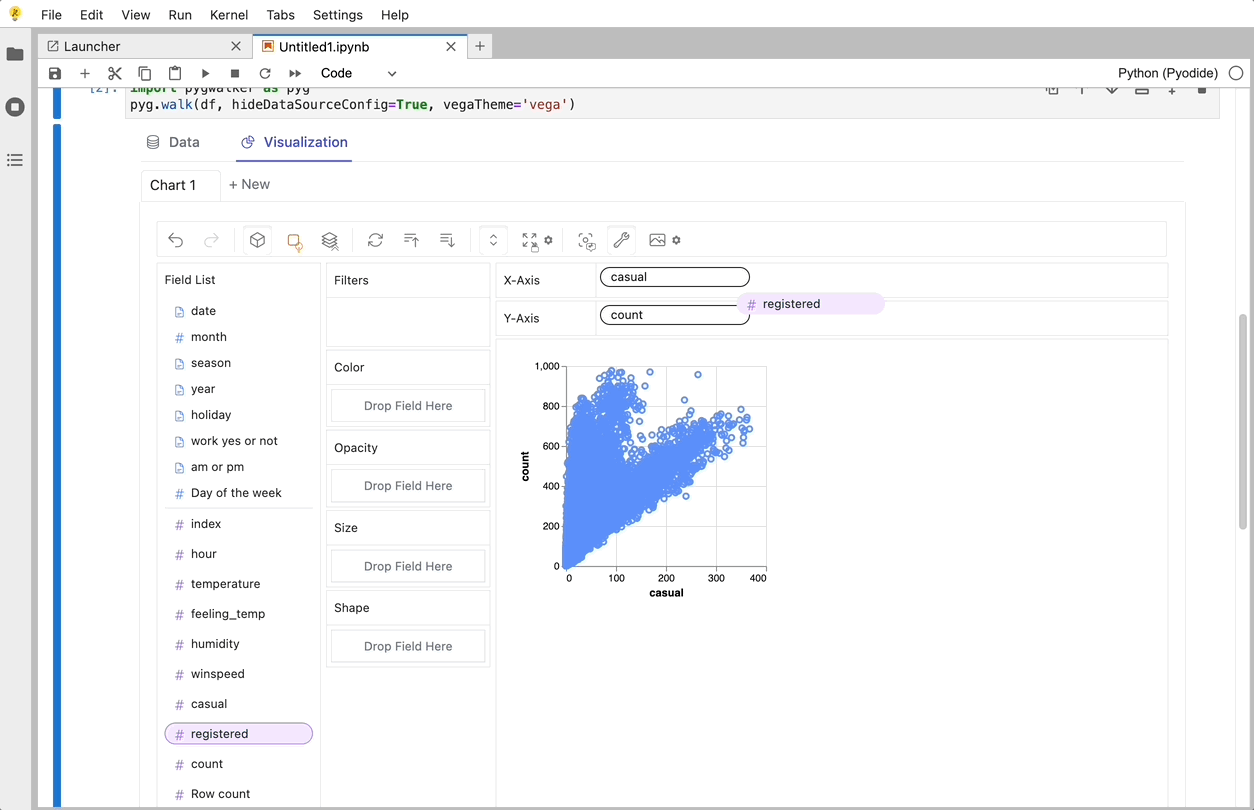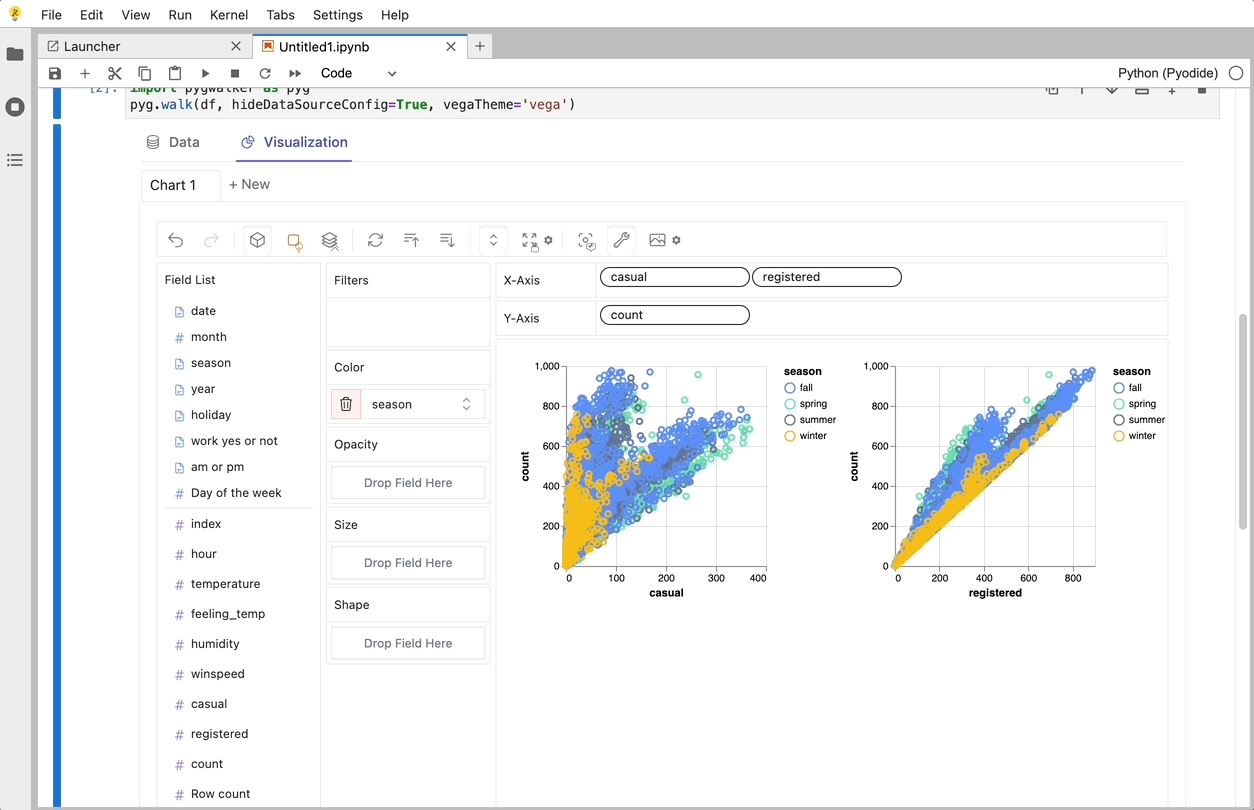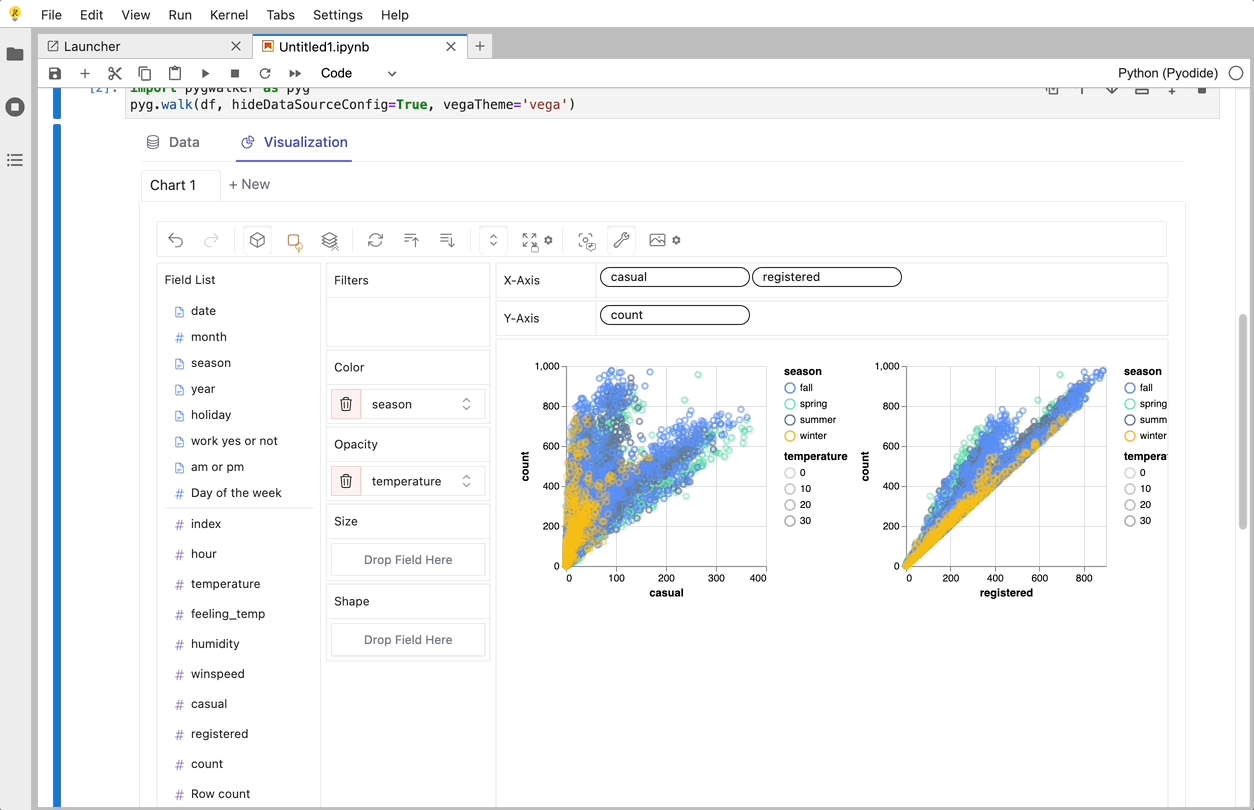
以下は、すぐに始める方法です:
Jupyter Notebookにpygwalkerとpandasをインポートして開始します。
import pandas as pd
import pygwalker as pyg既存のワークフローを壊さずにpygwalkerを使用することができます。例えば、次のようにデータフレームがロードされた状態でGraphic Walkerを呼び出すことができます。
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)また、polarsを使用してpygwalkerを使用することもできます( pygwalker>=0.1.4.7a0 以降):
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)これで、Pandasのデータフレームを読み込んだ準備が整いました。
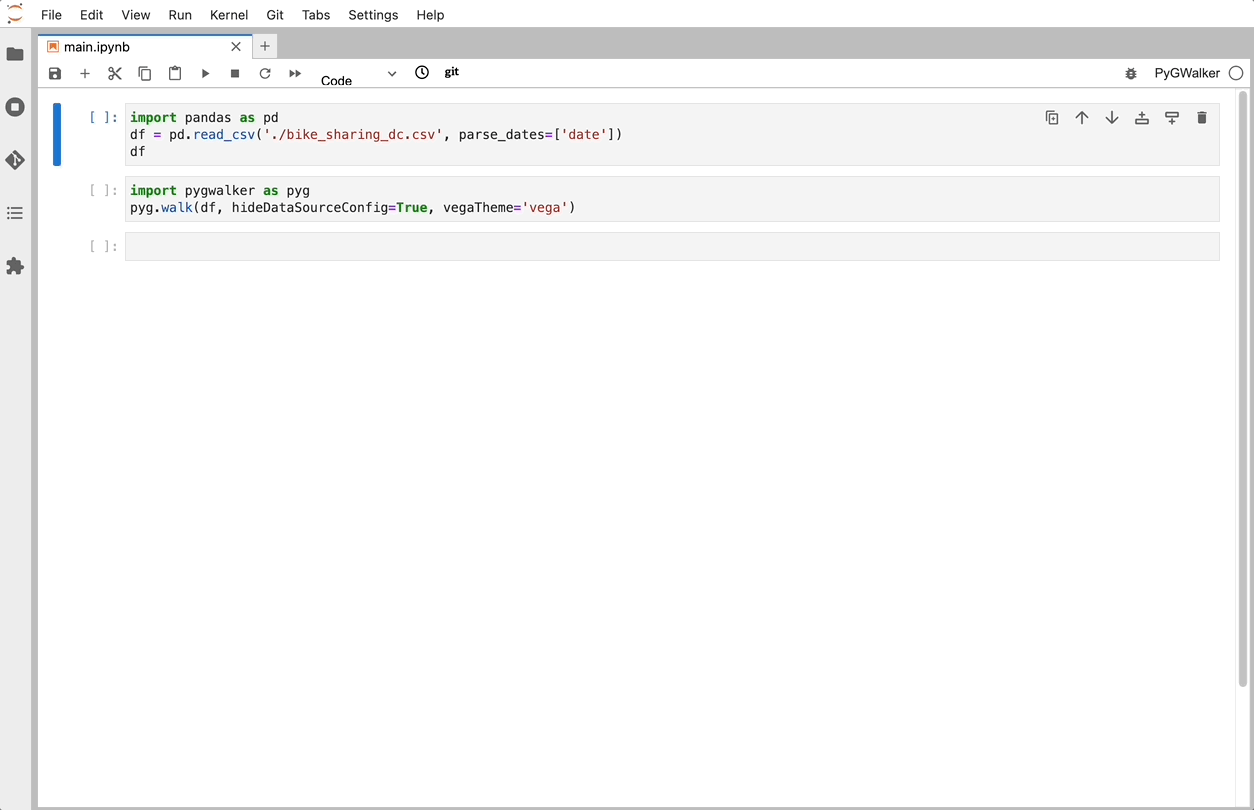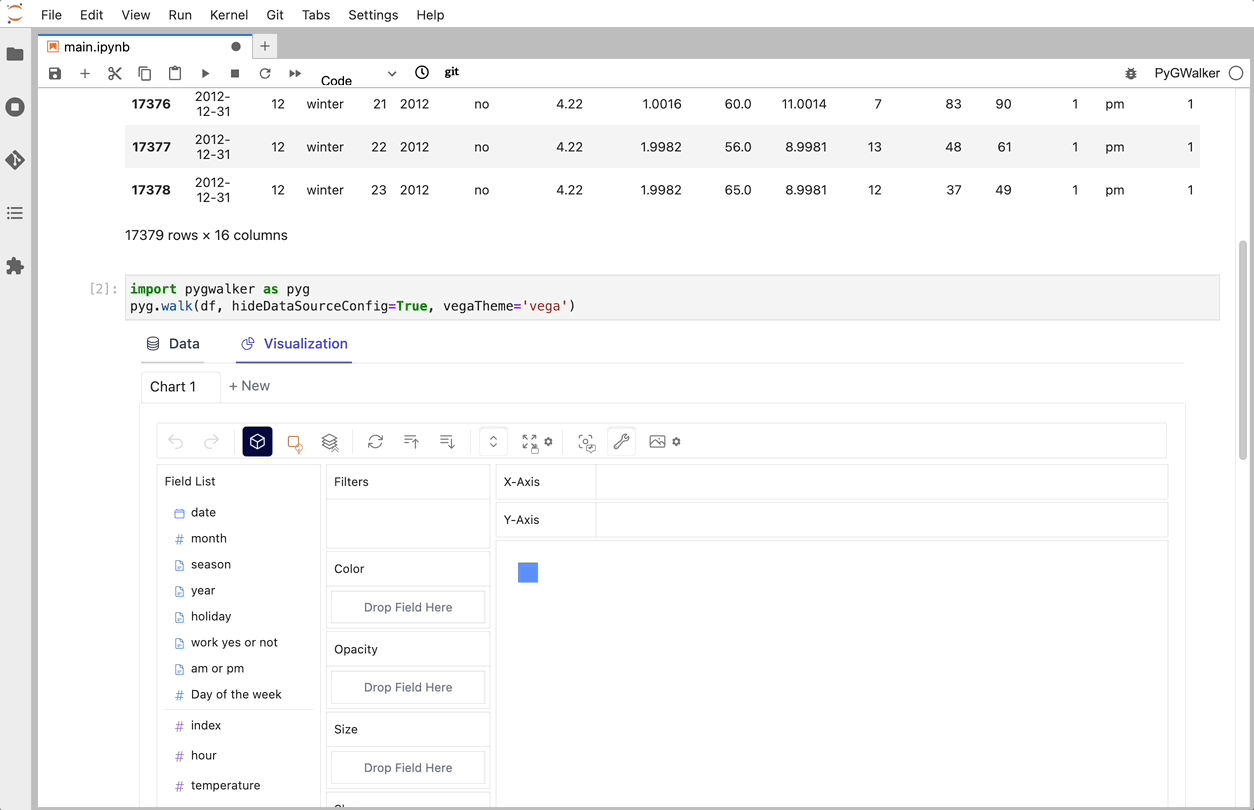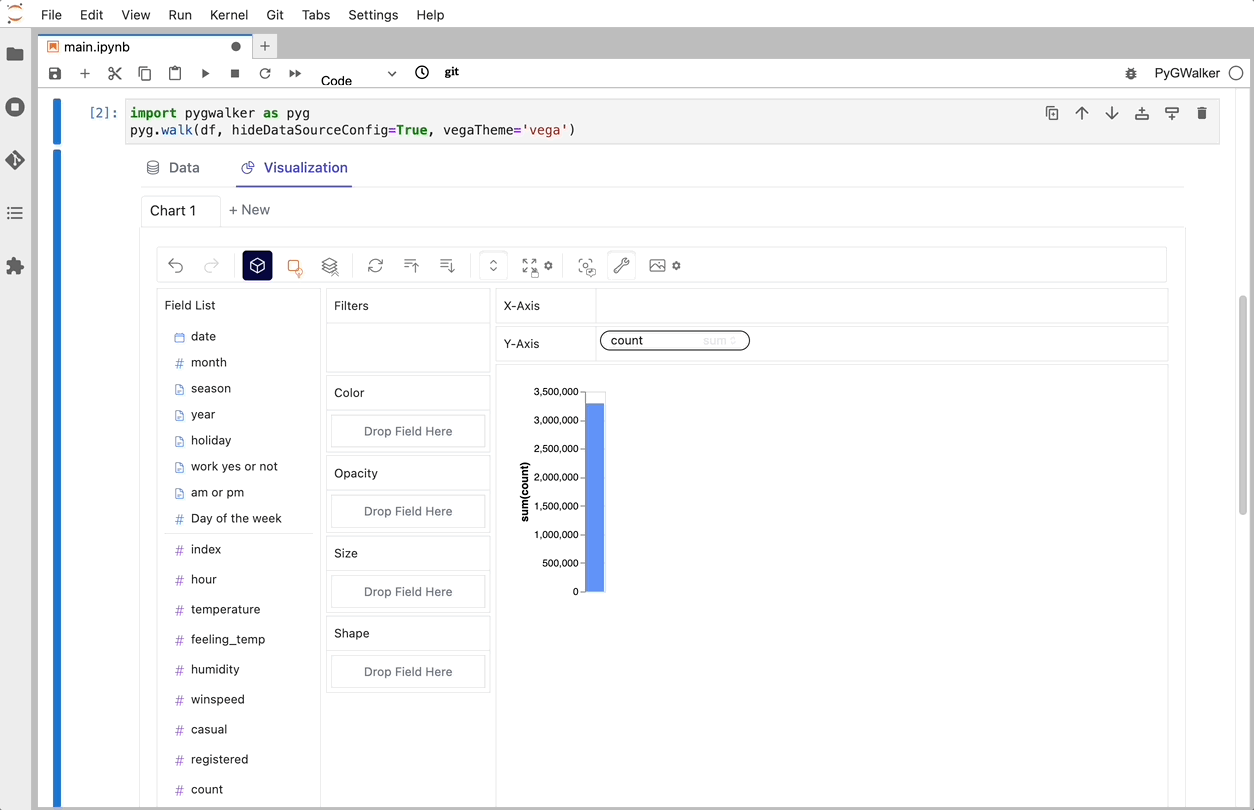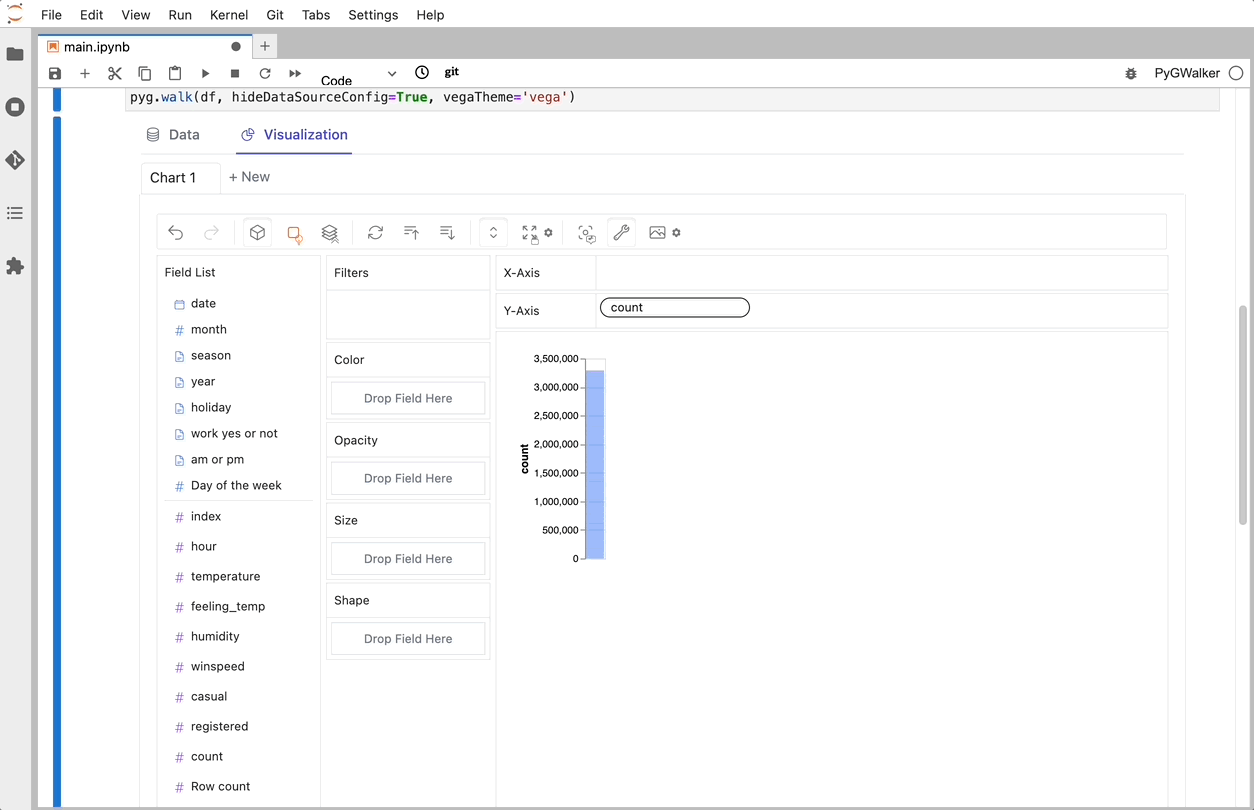
以上です。ドラッグアンドドロップするだけでデータを分析し可視化するためのTableauのようなユーザーインターフェースを利用することができます。
PyGWalkerは、活発な開発者とデータサイエンティストのコミュニティによってサポートされています。PyGWalkerのGitHub (opens in a new tab)を訪れ、⭐️を付けましょう!
Google ColabやKaggle NotebookでもPyGWalkerを試すことができます:
| Kaggleで実行する (opens in a new tab) | Colabで実行する (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) | 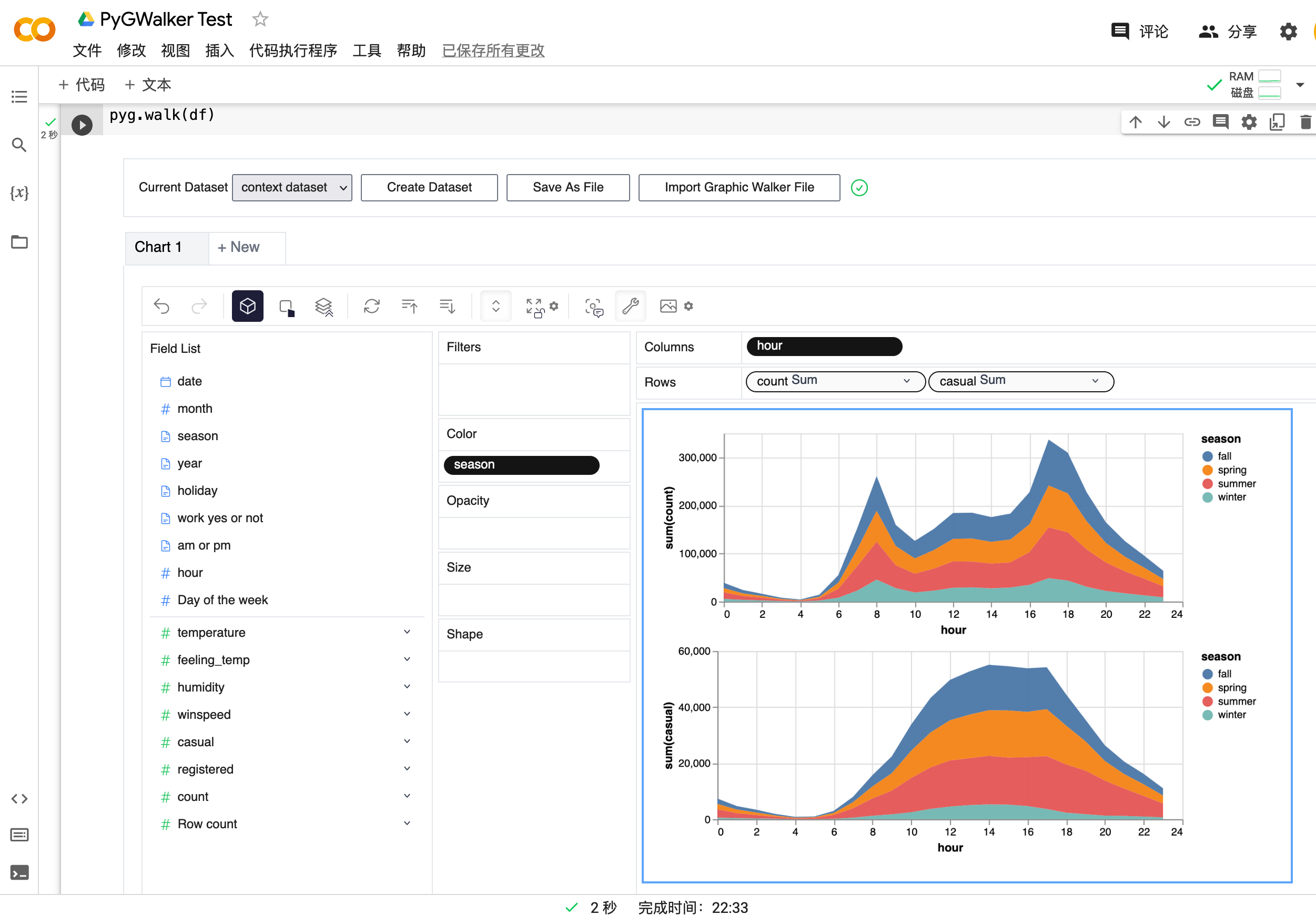 (opens in a new tab) (opens in a new tab) |
異なるプロットタイプへの深入り
Pandasはさまざまなプロットタイプを提供しており、それぞれが異なる種類のデータや異なる疑問に適しています。たとえば、ヒストグラムはデータの分布を概観するのに最適であり、スキャッタープロットは異なるデータポイント間の相関関係を見つけるのに役立ちます。
Pandasの各プロットタイプには、可視化をカスタマイズするための調整可能なパラメータセットが付属しています。これらのパラメータを理解し、適切に使用することで、意味のある可視化を作成する能力を大幅に向上させることができます。
以下は、ヒストグラムとスキャッタープロットの作成方法です:
# ヒストグラム
df['A'].plot(kind='hist')
# スキャッタープロット
df.plot(kind='scatter', x='A', y='B')最初のプロットでは、 'A' 列のヒストグラムを作成しています。2つ目のプロットでは、 'A' をx軸、 'B' をy軸にしたスキャッタープロットを作成しています。
Pandasでのカテゴリデータの扱い
カテゴリデータは、多くのデータセットで遭遇する一般的なデータの種類です。Pandasは、このようなデータを可視化するためのいくつかの強力なツールを提供しています。たとえば、バープロットは異なるカテゴリを比較するのに役立ち、パイプロットはカテゴリ間の比率を視覚化するのに優れています。
さらに、Pandasを使用すると、カテゴリに基づいてデータをグループ化することもできます。これは、データを集約し、カテゴリレベルの洞察を得るために非常に役立ちます。
以下は、バープロットとパイプロットの作成方法の例です:
# カテゴリデータを含むDataFrameの作成df = pd.DataFrame({
'果物': ['りんご', 'バナナ', 'さくらんぼ', 'りんご', 'さくらんぼ', 'バナナ', 'りんご', 'さくらんぼ', 'バナナ', 'りんご'],
'個数': np.random.randint(1, 10, 10)
})
# 棒グラフ
df.groupby('果物')['個数'].sum().plot(kind='bar')
# 円グラフ
df.groupby('果物')['個数'].sum().plot(kind='pie')このコードでは、まずカテゴリカルデータを持つDataFrameを作成します。その後、'果物'列でデータをグループ化し、各果物の'個数'を合計します。最後に、合計個数を持つ棒グラフと円グラフを作成します。
プロットのカスタマイズ
Pandasの可視化の最も強力な機能の一つは、プロットをカスタマイズすることができる点です。これには、プロットの色やスタイルの変更、ラベルやタイトルの追加などが含まれます。
以下は、ラインプロットのカスタマイズの例です:
# DataFrameの作成
df = pd.DataFrame({
'A': np.random.rand(10),
'B': np.random.rand(10)
})
# カスタマイズされたラインプロットの作成
df.plot(kind='line',
color=['red', 'blue'],
style=['-', '--'],
title='私のラインプロット',
xlabel='インデックス',
ylabel='値')このコードでは、まず2つの列を持つDataFrameをランダムな数値で作成します。その後、ラインプロットを作成し、ラインの色やスタイルを設定し、タイトルやx軸、y軸のラベルを追加してカスタマイズします。
より複雑なデータ構造の取り扱い
Pandasはシンプルなデータ構造の取り扱いに限られるわけではありません。マルチインデックスのDataFrameや時系列データなど、より複雑なデータ構造の取り扱いも可能です。
以下は、マルチインデックスのDataFrameからラインプロットを作成する例です:
# マルチインデックスのDataFrameの作成
index = pd.MultiIndex.from_tuples([(i,j) for i in range(5) for j in range(5)])
df = pd.DataFrame({
'A': np.random.rand(25),
'B': np.random.rand(25)
}, index=index)
# ラインプロットの作成
df.plot(kind='line')このコードでは、まず2つの列を持つマルチインデックスのDataFrameをランダムな数値で作成します。その後、このDataFrameからラインプロットを作成します。
Seabornによる高度な可視化
Pandasはデータ可視化のための堅牢な基盤を提供していますが、時にはより高度なツールが必要な場合もあります。SeabornはMatplotlibに基づいたPythonのデータ可視化ライブラリであり、美しい情報を提供する高レベルのインタフェースを提供します。
以下は、Pandas DataFrameからSeabornのプロットを作成する例です:
import seaborn as sns
# DataFrameの読み込み
df = pd.read_csv('bikesharing_dc.csv', parse_dates=['date'])
# Seabornのプロットの作成
sns.lineplot(data=df, x='date', y='count')このコードでは、まずSeabornライブラリをインポートします。その後、DataFrameを読み込み、'date'列をx軸、'count'列をy軸に配置してラインプロットを作成します。
Plotlyによるインタラクティブな可視化
インタラクティブな可視化には、Plotlyが素晴らしい選択肢です。Plotlyはインタラクティブで公開品質のグラフを作成するためのPythonグラフライブラリです。
以下は、Pandas DataFrameからPlotlyのプロットを作成する例です:
import plotly.express as px
# DataFrameの読み込み
df = pd.read_csv('bikesharing_dc.csv', parse_dates=['date'])
# Plotlyのプロットの作成
fig = px.line(df, x='date', y='count')
fig.show()このコードでは、まずPlotly Expressモジュールをインポートします。その後、DataFrameを読み込み、'date'列をx軸、'count'列をy軸に配置してラインプロットを作成します。fig.show()コマンドでインタラクティブなプロットが表示されます。
結論
PandasはPythonでのデータ分析と可視化のための強力なツールです。堅牢なプロット機能とMatplotlib、Seaborn、Plotly、PyGWalkerなど他の可視化ライブラリとの互換性を備えているため、データから洞察を得るためにさまざまな可視化を作成することができます。初心者から経験豊富なデータサイエンティストまで、Pandasの可視化をマスターすることは、データ分析ワークフローを向上させる貴重なスキルです。
FAQs
-
PythonのPandasとは何ですか?
- PandasはPythonプログラミング言語向けに作成されたデータ操作・分析のためのソフトウェアライブラリです。構造化データを操作するために必要なデータ構造と関数を提供します。
-
Pandasはどのようにデータ可視化に使用されますか?
- Pandasはplot()関数やさまざまなプロットメソッドを使用して、DataFrameやSeriesオブジェクトからデータをプロットすることでデータ可視化を提供します。
-
Pandasの人気のあるデータ可視化ライブラリはいくつかありますか?
- Pandasでのデータ可視化にはMatplotlib、Seaborn、Plotly、PyGWalkerなどの人気のあるライブラリがあります。これらのライブラリはPythonで静的、アニメーション、インタラクティブなプロットを作成するためのさまざまなツールと機能を提供します。