How to Read CSV Files in Pandas - Essential Guide for Beginners

If you are a data scientist, you probably deal with large datasets in various formats. One of the most popular formats for storing data is CSV (Comma Separated Values) files. In this article, we will show you how to read CSV files in Pandas, a popular Python library for data manipulation and analysis.
- Runcell Science: An Open Source Alternative to Claude Science for Research Workflows
- How to Make Mac Not Sleep: Keep Codex, Claude Code, and AI Agents Running
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: Which AI Agent Stack Should You Choose in 2026?
- Can Claude Code Analyze Jupyter Notebooks for Data Science? What It Actually Does
- Claude Code Routines: Why AI Agent Cron Jobs Matter
- Claude Code Desktop Bypass Permissions: How to Enable It
- How to Build Two Python Agents with Google’s A2A Protocol - Step by Step Tutorial
- Top 10 growing data visualization libraries in Python in 2025
What is Pandas?
Pandas (opens in a new tab) is an open-source Python library that provides easy-to-use data structures and data analysis tools. It is built on top of the NumPy library and is designed to work with data in a variety of formats, including CSV, Excel, SQL databases, and more.
Read CSV Files in Pandas
To read a CSV file in Pandas, we use the read_csv() function. Here's an example:
import pandas as pd
df = pd.read_csv('data.csv')This code reads a CSV file named data.csv and stores it in a Pandas DataFrame named df. The read_csv() function automatically infers the data types of the columns and creates a DataFrame object that can be used for further analysis.
Select Columns
If you only need to read specific columns from the CSV file, you can use the usecols parameter to specify a list of column names or indices to read. Here's an example:
df = pd.read_csv('data.csv', usecols=['col1', 'col2'])In this code, we only read the col1 and col2 columns from the CSV file.
Skip Columns and Rows
In some cases, you may want to skip certain columns or rows while Read a CSV file in Pandas. You can do this using the usecols and skiprows parameters of the read_csv() function.
The usecols parameter is used to specify the columns to be read from the CSV file. It can take a list of column names or column indices.
import pandas as pd
# Read CSV file and select specific columns
df = pd.read_csv('data.csv', usecols=['column1', 'column3'])In this example, only the columns with names column1 and column3 will be read from the CSV file.
The skiprows parameter is used to skip a certain number of rows while Read the CSV file. It can take an integer value specifying the number of rows to skip or a list of row indices to be skipped.
import pandas as pd
# Read CSV file and skip first two rows
df = pd.read_csv('data.csv', skiprows=2)In this example, the first two rows of the CSV file will be skipped while Reading.
Specify Data Types
By default, Pandas infers the data types of the columns when Read a CSV file. However, you can also specify the data types manually using the dtype parameter. Here's an example:
dtypes = {'col1': 'int32', 'col2': 'float32', 'col3': 'object'}
df = pd.read_csv('data.csv', dtype=dtypes)In this code, we specify that col1 should be an integer, col2 should be a float, and col3 should be a string.
Encoding Issues
Sometimes, CSV files can have encoding issues that can cause problems when Read them in Pandas. To solve this problem, you can use the encoding parameter to specify the file encoding. Here's an example:
df = pd.read_csv('data.csv', encoding='utf-8')In this code, we specify that the CSV file is encoded in UTF-8.
Read CSV as String
By default, Pandas reads CSV files as numeric and string types. If you want to read the CSV file as a string, you can use the dtype parameter and set the data type of all columns to string. Here's an example:
dtypes = {col: 'str' for col in df.columns}
df = pd.read_csv('data.csvContinue writing from this sentence: By default, Pandas reads CSV files as numeric and string types. If you want to read the CSV file as a string, you can use the dtype parameter and set the data type of all columns to string. Here's an example:
Here's an example of how to read a CSV file as a string using the dtype parameter in Pandas:
import pandas as pd
# Read CSV file as string
df = pd.read_csv('data.csv', dtype=str)
# Display the data types of all columns
print(df.dtypes)This code will read the CSV file named data.csv and set the data type of all columns to string. The resulting DataFrame object df will have all the data in string format.
Read Multiple CSV Files
Pandas also allows you to read multiple CSV files at once using the read_csv() function. You can pass a list of file paths to the function, and it will return a list of DataFrames containing the data from all the files.
import pandas as pd
# Read multiple CSV files
files = ['data1.csv', 'data2.csv', 'data3.csv']
dataframes = [pd.read_csv(file) for file in files]In this example, three CSV files named data1.csv, data2.csv, and data3.csv will be read, and the resulting list dataframes will contain DataFrames with the data from all the files.
Visualize CSV Files With PyGWalker
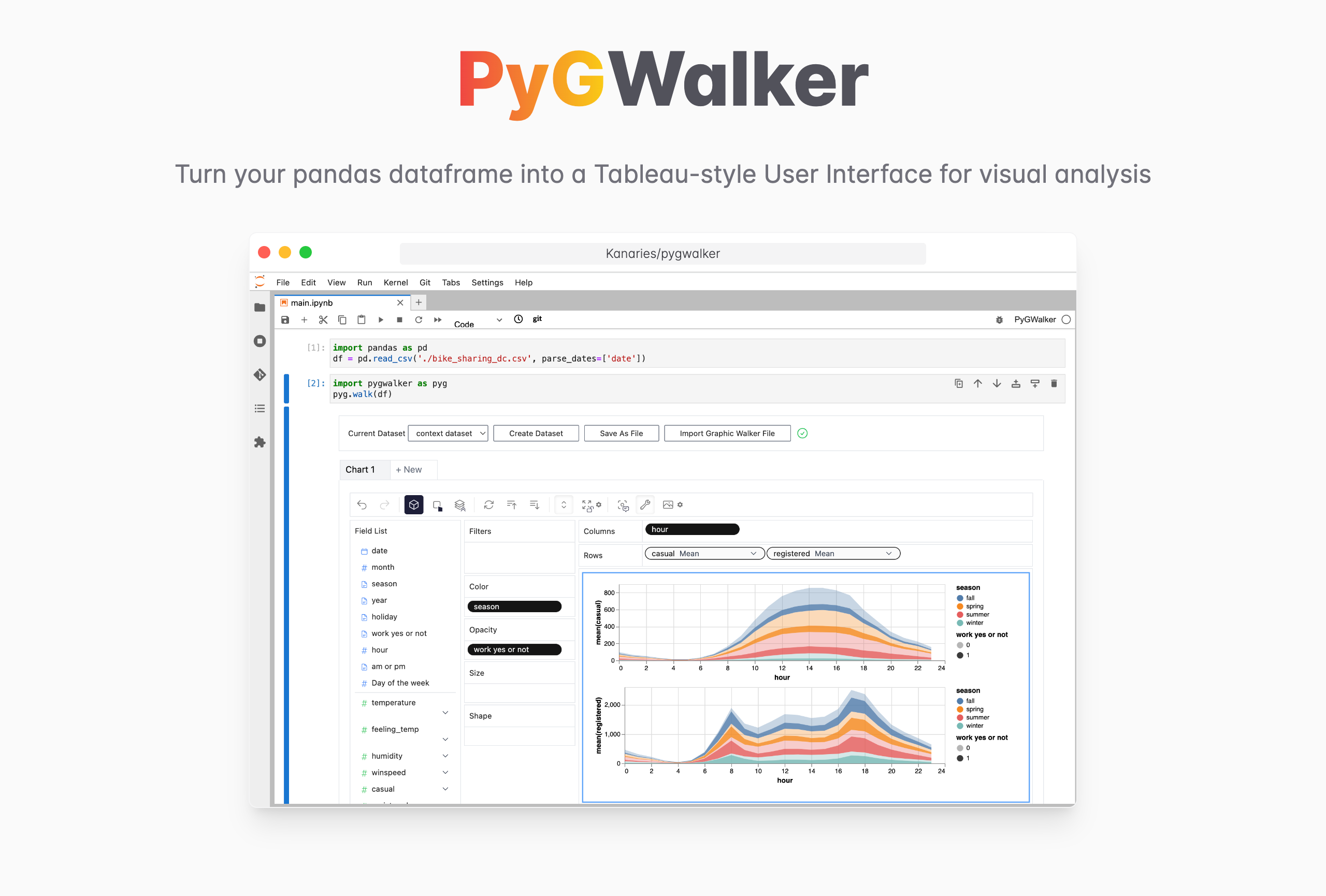
Why not just stop at reading a CSV file? You can easily create beautiful data visualization with a user-friendly interface without learning complicated codes, by using an Open Source tool named: PyGWalker (opens in a new tab).
PyGWalker (opens in a new tab) can simplify your data analysis and data visualization workflow, by turning your pandas dataframe (and polars dataframe) into a tableau-alternative User Interface for visual exploration. It integrates Jupyter Notebook (or other jupyter-based notebooks) with Graphic Walker, a different type of open-source alternative to Tableau. It allows data scientists to analyze data and visualize patterns with simple drag-and-drop operations.
| Run in Kaggle (opens in a new tab) | Run in Colab (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) |  (opens in a new tab) (opens in a new tab) |
Visit Google Colab (opens in a new tab), Kaggle Code (opens in a new tab), Binder (opens in a new tab) or Graphic Walker Online Demo (opens in a new tab) to test PyGWalker!
Use PyGWalker in Jupyter Notebook
Import PyGWalker and pandas to your Jupyter Notebook to get started.
import pandas as pd
import PyGWalker as pygYou can use PyGWalker without breaking your existing workflow. For example, you can load the Pandas Dataframe into a visual UI.
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)And you can use PyGWalker with polars (since PyGWalker>=0.1.4.7a0):
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)You can even try it online, simply visiting Binder (opens in a new tab), Google Colab (opens in a new tab) or Kaggle Code (opens in a new tab).
Conclusion
In this article, we learned how to read CSV files in Pandas using the read_csv() function. We also saw how to read CSV files as strings, skip columns and rows, and read multiple CSV files at once. Additionally, you have learned how to visualize data with PyGWalker (opens in a new tab), an Open Source tool to transform your Pandas datafame into Data visualization. With these techniques, you can start analyzing your data like a pro in no time!