Beyond DropNA: A Comprehensive Guide to Handling Null Values

As a data analyst, one of the most common and crucial tasks you'll encounter is data cleaning. Handling null values is an essential part of this process. In this article, we'll explore techniques like PySpark DropNA, DropNA in R, and more to ensure you're equipped to manage null values in various programming languages and platforms, including SQL, JavaScript, and Databricks. We'll also discuss how RATH, an automated data analysis copilot, can assist you in this endeavor.
- Runcell Science: An Open Source Alternative to Claude Science for Research Workflows
- How to Make Mac Not Sleep: Keep Codex, Claude Code, and AI Agents Running
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: Which AI Agent Stack Should You Choose in 2026?
- Can Claude Code Analyze Jupyter Notebooks for Data Science? What It Actually Does
- Claude Code Routines: Why AI Agent Cron Jobs Matter
- Claude Code Desktop Bypass Permissions: How to Enable It
- How to Build Two Python Agents with Google’s A2A Protocol - Step by Step Tutorial
- Top 10 growing data visualization libraries in Python in 2025
How to Remove Null Values with One Click
Kanaries RATH (opens in a new tab) is your ally in Data Cleaning. Its powerful data preparation tools can enhance your data transformation workflow with No Code. Here is the steps to drop your null values with RATH:
Step 1. Launch RATH at RATH Online Demo (opens in a new tab). On the Data Connections page, choose the Files Option and upload your Excel or CSV data file.
Step 2. On the Data Source tab, you are granted a general overview of your data.
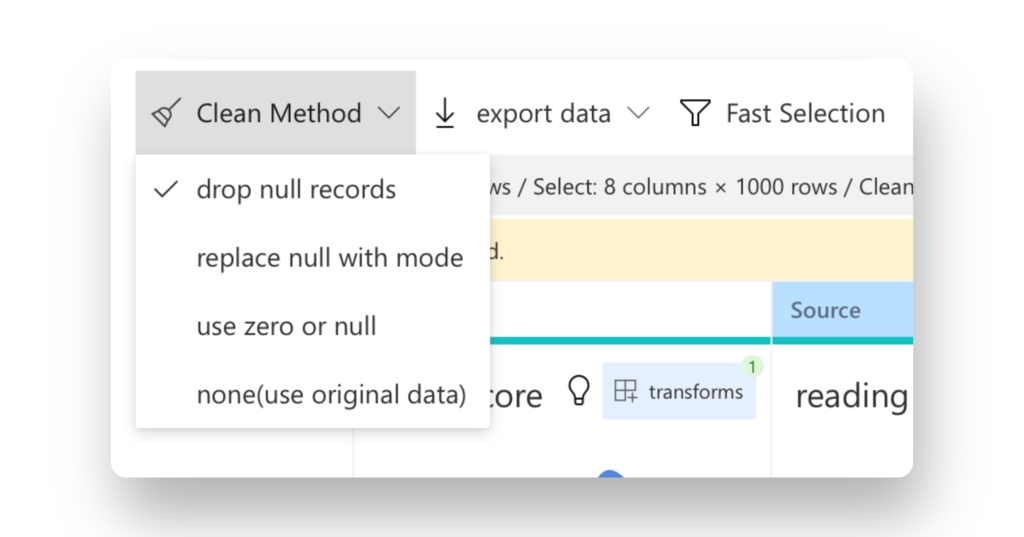
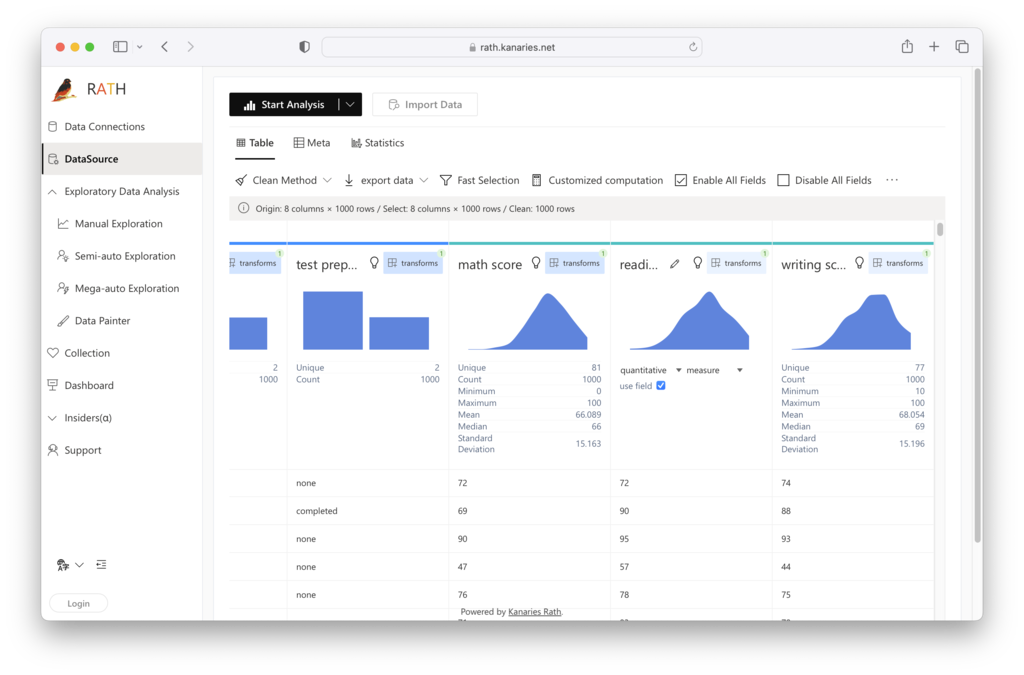 Choose the Clean Method option on the tab bar. You can drop the null values with one of the follwing options:
Choose the Clean Method option on the tab bar. You can drop the null values with one of the follwing options:
- Drop null records
- Fill Null values with Mode
- Use Zero or Null
- Use the Original Data.
That is all the prerequisites you need for data cleaning. You can try it out right now with RATH Online Demo (opens in a new tab):

Other Options to Drop Null Values
Databricks: Tackling Null Values on the Platform
Databricks is a widely used platform for data engineering and analytics, and it supports both PySpark and R languages. As such, you can leverage PySpark DropNA or DropNA in R for null value management on Databricks. Just make sure to configure your Databricks cluster with the necessary libraries and runtime environments.
Handling JSON Null Values and SQL Exclusion
In SQL, excluding null values is as simple as adding a WHERE clause to your query:
SELECT * FROM employees WHERE age IS NOT NULL;For JSON data, you can use a simple script in your preferred language to filter out null values, like the following Python example:
import json
data = '[{"name": "Alice", "age": null}, {"name": "Bob", "age": 35}]'
json_data = json.loads(data)
clean_data = [item for item in json_data if item["age"] is not None]
print(clean_data)This Python script reads JSON data, loads it into a list, and filters out objects with null ages using list comprehension.
PySpark DropNA
Apache PySpark is a powerful data processing library that allows you to work with large datasets effortlessly. When it comes to handling null values, PySpark DropNA is a handy function that helps you remove these pesky elements from your DataFrame. To illustrate, consider the following example:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("PySpark DropNA Example") \
.getOrCreate()
# Sample DataFrame with null values
data = [("Alice", 30, None),
("Bob", None, 5000),
(None, 40, 6000)]
columns = ["Name", "Age", "Salary"]
df = spark.createDataFrame(data, columns)
# Drop rows containing null values
df_clean = df.na.drop()
df_clean.show()In this example, we create a simple DataFrame with some null values and use the drop() method to remove rows containing these values. The result is a clean DataFrame without nulls.
Array Remove Null Values in JavaScript
JavaScript, a popular language for web development, also requires handling null values. To remove null values from an array, you can use the filter() method:
const data = [1, null, 3, null, 5];
const cleanData = data.filter(item => item !== null);
console.log(cleanData);This JavaScript code snippet demonstrates how to remove null values from an array using the filter() method.
DropNA in R: Null Value Management in R Language
R is another popular language for data analysts, with its rich ecosystem of packages for data manipulation and analysis. To handle null values in R, you can use the na.omit() or drop_na() functions from the base R package and the tidyverse package, respectively.
# Load the required libraries
library(tidyverse)
# Create a sample data frame
data <- tibble(Name = c("Alice", "Bob", "Cindy"),
Age = c(30, NA, 40),
Salary = c(NA, 5000, 6000))
# Remove null values using drop_na()
data_clean <- data %>% drop_na()
print(data_clean)This R code demonstrates how to use the drop_na() function from the tidyverse package to remove rows containing null values.
Conclusion
Handling null values is a critical aspect of data cleaning for every data analyst. Techniques like PySpark DropNA, DropNA in R, and other language-specific approaches can help you manage null values efficiently. Additionally, RATH offers a powerful, user-friendly solution for automated data analysis, ensuring your data is clean and ready for further exploration. Stay ahead of the curve by mastering these techniques and tools to enhance your data analysis capabilities.