Choose a Data Source
Before you start your exploratory data analysis journey with RATH, you need to establish a connection between RATH and your data source. This will allow you to import the necessary data for analysis.
To connect RATH to your data source, click on the Data Source tab, and choose one of the following options:
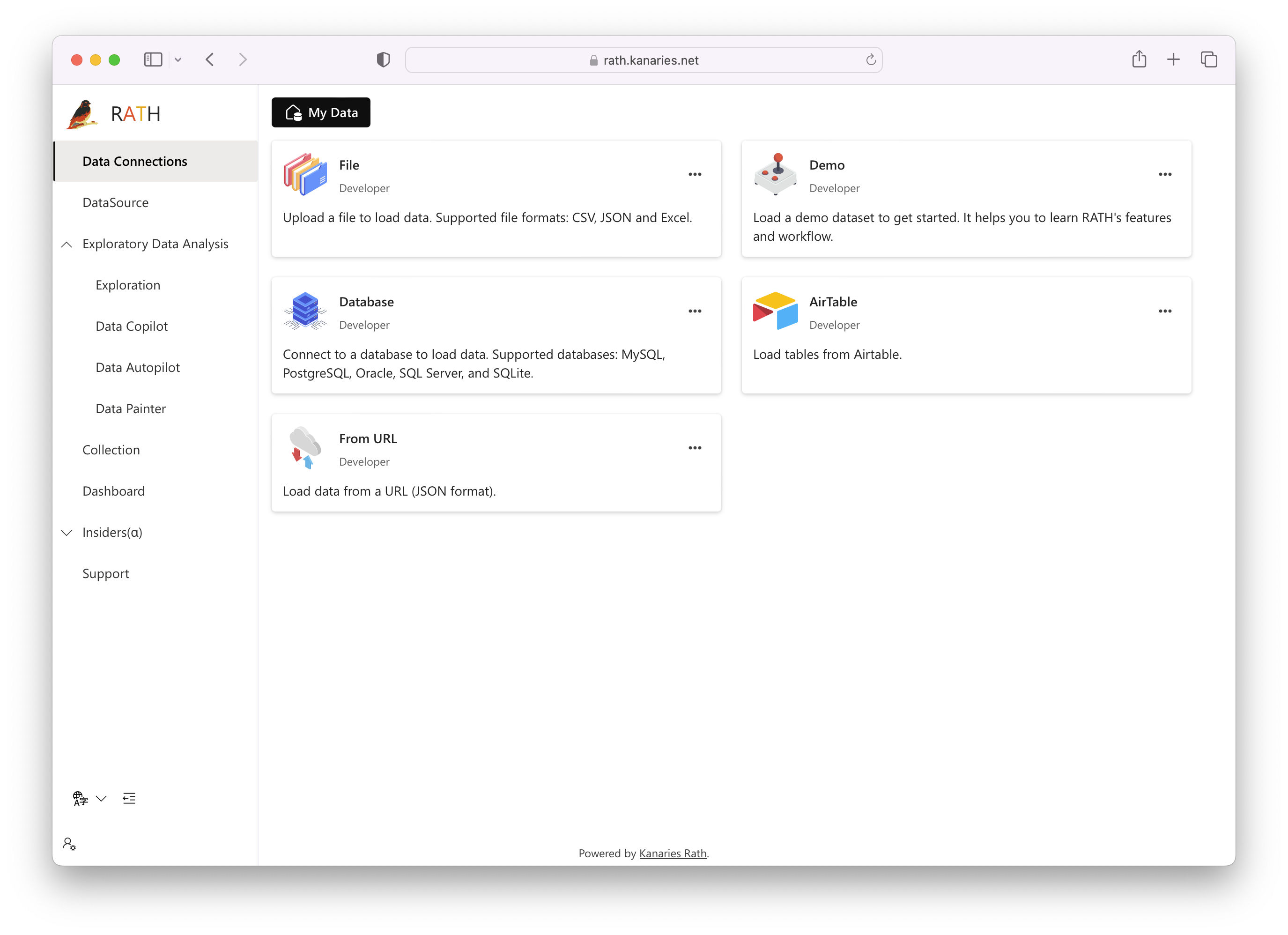
Upload a Local File
If your data is stored locally on your machine, you can easily upload it to RATH. On Data Source tab, click on the File button and upload your Excel or CSV file.
The following video explains the detailed steps:
For files larger than 500MB, it is suggested to use Sampling. Refer to the Best Practices chapter for more details.
Connect to a Demo Dataset
If you want a quick demonstration of RATH's features and capabilities, you can choose the Demo option. RATH provides several demo datasets for you to explore its functionalities without connecting to an external data source.
Connect to a Database
RATH supports various remote databases, allowing you to connect and analyze data directly from these sources. The following remote databases are supported by RATH:
 |  |  |  |
|---|---|---|---|
 |  |  |  |
 |  |  |  |
 |  |
If you are looking for support for additional databases, reach out to the RATH support team through the contact support page or submit an issue (opens in a new tab) on GitHub.
In RATH, the concept of data source and data engine aren't a clear-cut.
For example, we can connect RATH to a remote ClickHouse database. In this case, RATH functions as the data engine, and utilize ClickHouse as the data source.
For processing large volumes of data that exceed RATH's computational capacity, you can use ClickHouse Clusters as the data engine. In this scenario, RATH functions as the data source.
Connect to AirTable
You can easily import your AirTable data to RATH. For more details, refer to the Connect to AirTable chapter.
Next steps
- Data Profiling and Data Transformation
- Extract Text Patterns from your data soruce
- Generate Automated Data Insight