Top 9 open-source DataFrame libraries for Python

Python has established itself as the go-to language for developers and data enthusiasts. A key reason for its popularity in the data processing is its extensive ecosystem of libraries, especially those focused on DataFrames. These powerful, table-like structures facilitate easy manipulation and analysis of structured data, making them indispensable for anyone working with datasets.
If you’ve ever used Python for data analysis, you’ve likely encountered Pandas, the most well-known and loved DataFrame library. But as data grows larger and more complex, new libraries have emerged to tackle the challenges of scale, speed, and performance. In this article, we’ll take a journey through some of the most popular open-source DataFrame libraries in Python, each offering unique features to help you get the most out of your data.
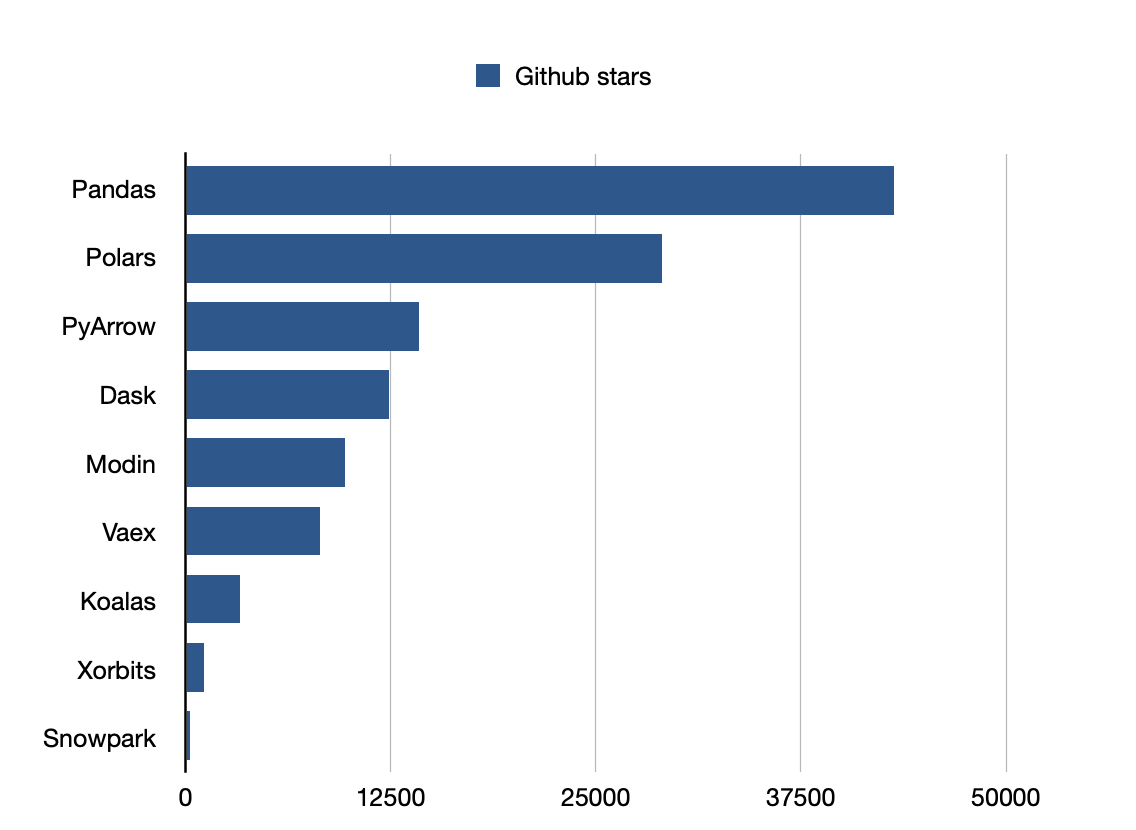
Pandas is the most popular library.
1. Pandas: The Veteran of Data Science
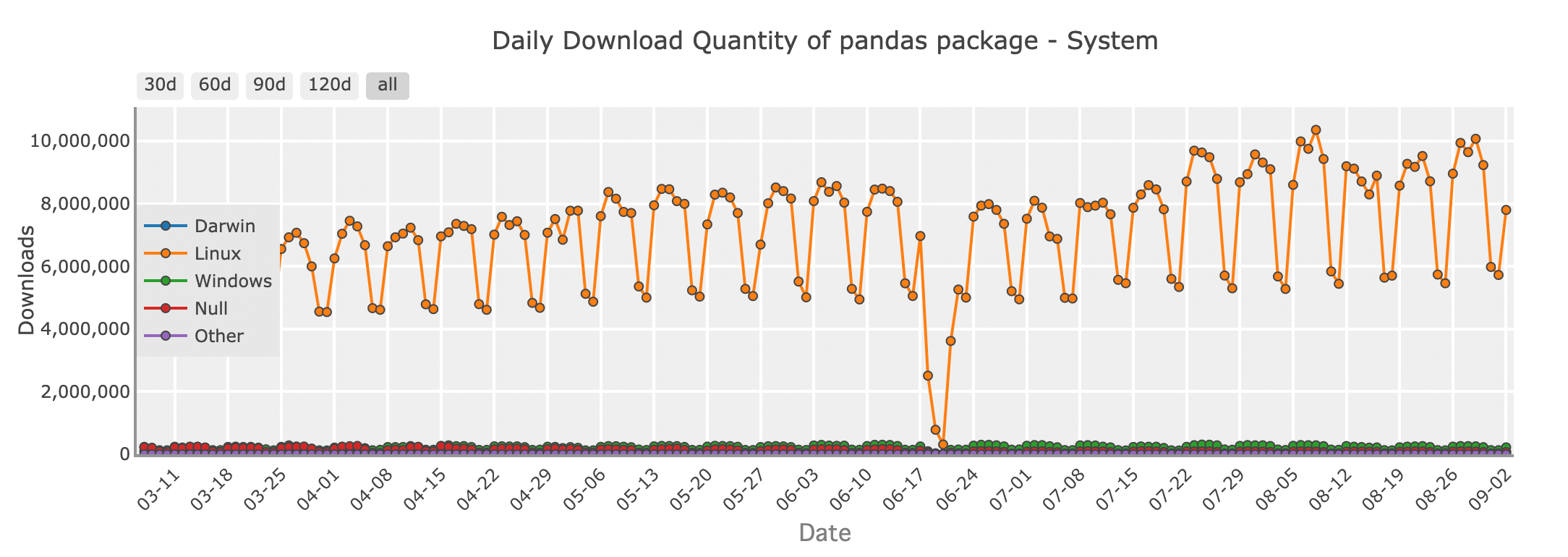
Daily download quantity of Pandas package - system
For many Python developers, Pandas is the first library that comes to mind when working with DataFrames. Its rich set of features and intuitive API make it easy to load, manipulate, and analyze data. Whether you're cleaning up a messy dataset, merging data from multiple sources, or performing statistical analysis, Pandas provides all the tools you need in a familiar, spreadsheet-like format.
import pandas as pd
# Creating a DataFrame
data = {
'Name': ['Amy', 'Bob', 'Cat', 'Dog'],
'Age': [31,27,16,28],
'Department': ['HR', 'Engineering', 'Marketing', 'Sales'],
'Salary': [70000, 80000, 60000, 75000]
}
df = pd.DataFrame(data)
# Displaying the DataFrame
print(df)Pandas excels in handling small to medium-sized datasets that fit comfortably in your computer’s memory. It's perfect for everyday data tasks, from exploring data in Jupyter notebooks to building more complex pipelines in production. However, as your datasets grow in size, Pandas may start to show its limitations. That’s where other DataFrame libraries come into play.
Github stars: 43200
2. Modin: Scaling Pandas to New Heights
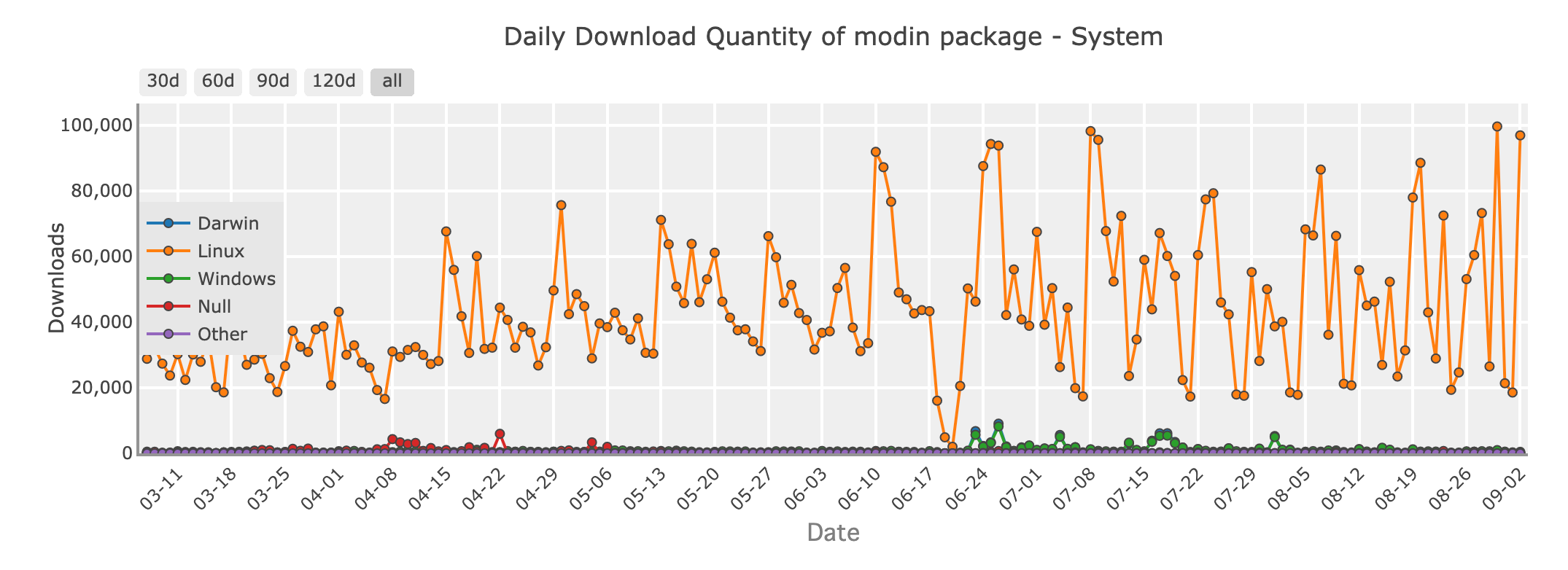
Daily download quantity of Modin package - system
Imagine working with a dataset too large for Pandas to handle efficiently. You don’t want to rewrite your entire codebase, but you need more speed and scalability. Enter Modin, a library designed to make your Pandas code run faster, without requiring major changes.
Modin is a drop-in replacement for Pandas, which means you can take your existing Pandas code and make it parallelized simply by changing the import statement. Behind the scenes, Modin uses powerful frameworks like Ray or Dask to distribute your computations across multiple cores or even a cluster of machines. It brings faster processing times for your data operations.
With Modin, you get the familiar Pandas API you know and love, but with the ability to handle larger datasets and take full advantage of your hardware.
Github stars: 9700
3. Polars: Speed and Efficiency Redefined
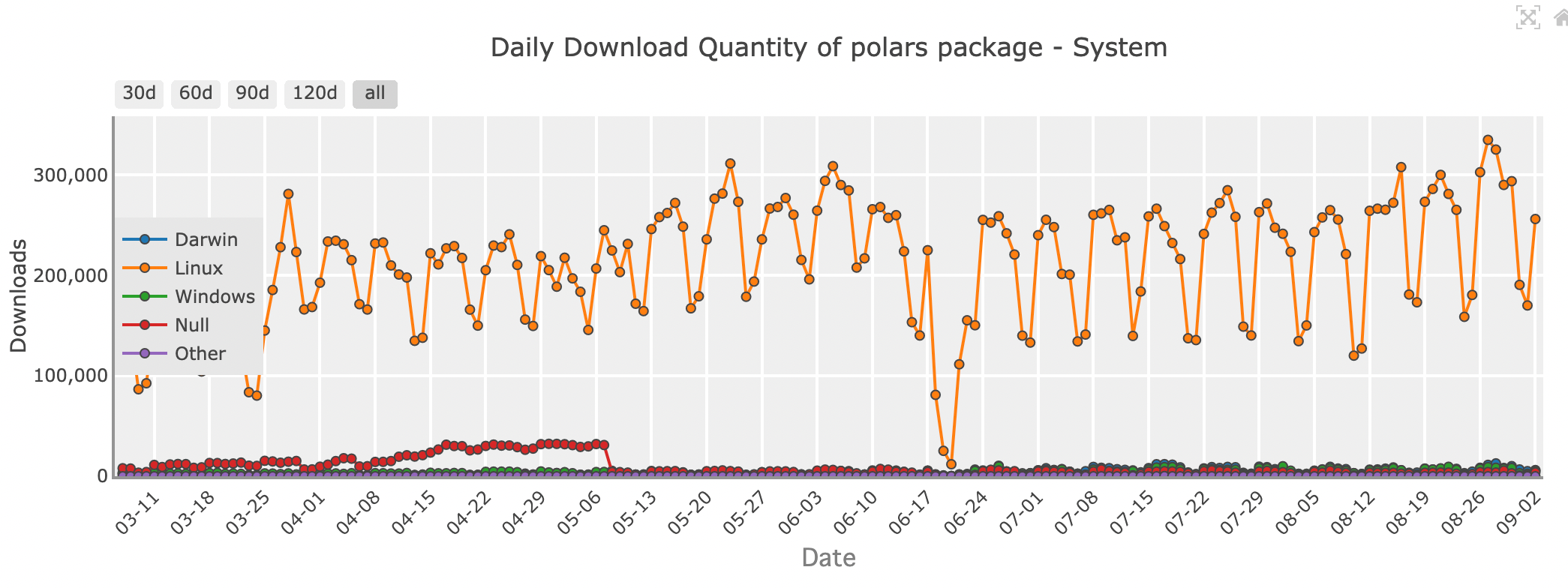
Daily download quantity of Polars package - system
When it comes to raw speed and efficiency, Polars is making waves in the data science community. Written in Rust, a programming language known for its performance and safety, Polars is designed to be fast—really fast. If you're dealing with large datasets or need to perform complex operations quickly, Polars might be the library for you.
Polars uses a technique called lazy evaluation, where operations are only executed when absolutely necessary. This allows it to optimize the entire computation pipeline, minimizing the time and resources required. Plus, Polars is built with multi-threading in mind, so it can efficiently use all the cores on your machine, making it an ideal choice for performance-critical tasks.
While Polars boasts impressive speed, it does come with a learning curve. Its API is different from Pandas, so it might take some time to get used to. However, for those willing to invest the time, Polars offers unparalleled performance and the ability to handle datasets that simply wouldn’t be feasible with other libraries.
Github stars: 29000
| Feature/Aspect | Pandas | Modin | Polars |
|---|---|---|---|
| Architecture | Single-threaded, Python/Cython | Multi-threaded, distributed (Ray/Dask) | Multi-threaded, written in Rust |
| Performance | Good for small to medium datasets | Scales across multiple cores or clusters | Extremely fast, handles large datasets |
| Memory Usage | High memory usage | Similar to Pandas | Lower memory usage, out-of-core support |
| Ease of Use | Very easy, extensive community support | Easy transition from Pandas | Intuitive but different API |
| Ecosystem | Mature, well-integrated with other libraries | Compatible with Pandas ecosystem | Smaller ecosystem, but growing |
| Use Cases | Small to medium datasets, data manipulation | Larger datasets, scaling Pandas operations | High-performance computing, large datasets |
| Installation | pip install pandas | pip install modin[all] | pip install polars |
4. Dask: A Distributed DataFrame for Big Data
Daily download quantity of Dask package - system
When your data grows so large that it can no longer fit in memory, Dask is able to serve as a powerful assistant. Dask is a parallel computing library that extends the Pandas API to handle datasets that are too big for a single machine.
Dask works by breaking your large DataFrame into smaller chunks and processing them in parallel, either on your local machine or across a cluster. This allows you to scale your computations without worrying about running out of memory. Whether you're working with big data or building data pipelines that need to scale to thousands of tasks, Dask provides the flexibility and power you need.
Github stars: 12400
5. PyArrow: Fast Data Interchange with Apache Arrow
Daily download quantity of PyArrow package - system
In the realm of data engineering, PyArrow shines as a crucial library for efficient data interchange between different systems. Built on top of the Apache Arrow format, PyArrow provides a wonderful columnar memory format that enables zero-copy reads for large datasets. This makes it a perfect choice for scenarios where performance and interoperability are key.
PyArrow is widely used to enable fast data transfer between languages like Python, R, and Java, and it plays a pivotal role in many big data processing frameworks. If you’re dealing with large-scale data pipelines, particularly where data needs to be shared across different tools or platforms, PyArrow is a valuable tool in your arsenal.
Github stars: 14200
6. Snowpark: DataFrames in the Cloud with Snowflake
Daily download quantity of Snowpark package - system
As more organizations move their data operations to the cloud, Snowpark emerges as an innovative solution for Python developers. Snowpark is a feature of Snowflake, a cloud-based data warehouse, that allows you to use DataFrame-style operations directly within the Snowflake environment. This means you can operate complex data transformations and analyses without moving your data out of Snowflake, reducing latency and increasing efficiency.
With Snowpark, you can write Python code that runs natively on Snowflake’s infrastructure, leveraging the power of the cloud to process massive datasets easily. It’s an excellent choice for teams already using Snowflake and looking to streamline their data processing workflows.
Github stars: 253
7. Xorbits: A Unified Solution for Scaling Data Science
Daily download quantity of Xorbits package - system
Xorbits is a powerful framework designed to scale data science operations across distributed environments. It offers a unified API that abstracts away the complexities of distributed computing, allowing you to scale your DataFrame operations across multiple nodes without needing to worry about the underlying infrastructure.
Xorbits integrates easily with existing tools like Pandas, Dask, and PyTorch, making it an ideal choice for machine learning and data science applications that require flexibility. Whether you’re training large models or processing vast amounts of data, Xorbits provides the flexibility and power to handle the job.
Github stars: 1100
8. Vaex: Out-of-Core DataFrames for Efficient Analysis
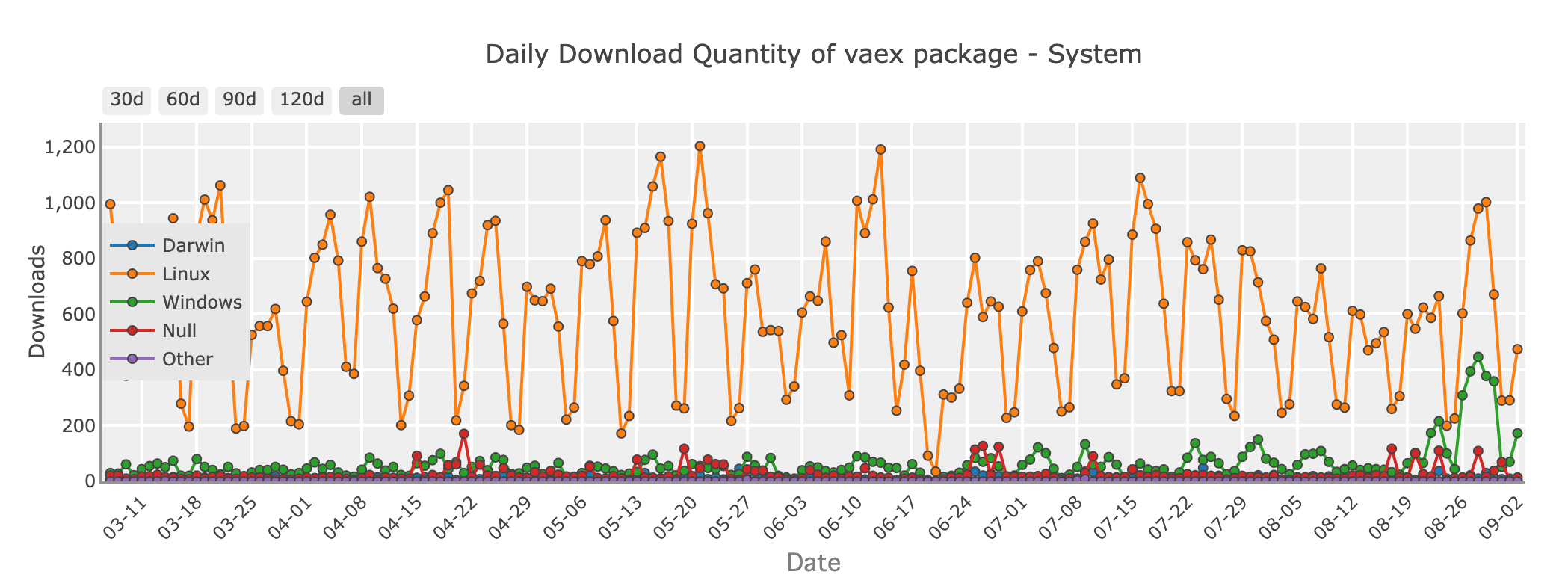
Daily download quantity of Vaex package - system
If you're dealing with huge datasets that exceed your system's memory but still want the simplicity of Pandas, Vaex is worth exploring. Vaex is designed for out-of-core computation, meaning it can handle datasets larger than your RAM by processing data in chunks, without loading everything into memory at once.
Vaex is optimized for speed and offers features like fast filtering, grouping, and aggregation, all while keeping memory usage to a minimum. It's especially useful for tasks like data exploration, statistical analysis, and even machine learning on large datasets.
Github stars: 8200
9. Koalas: Bringing Pandas to Big Data with Apache Spark
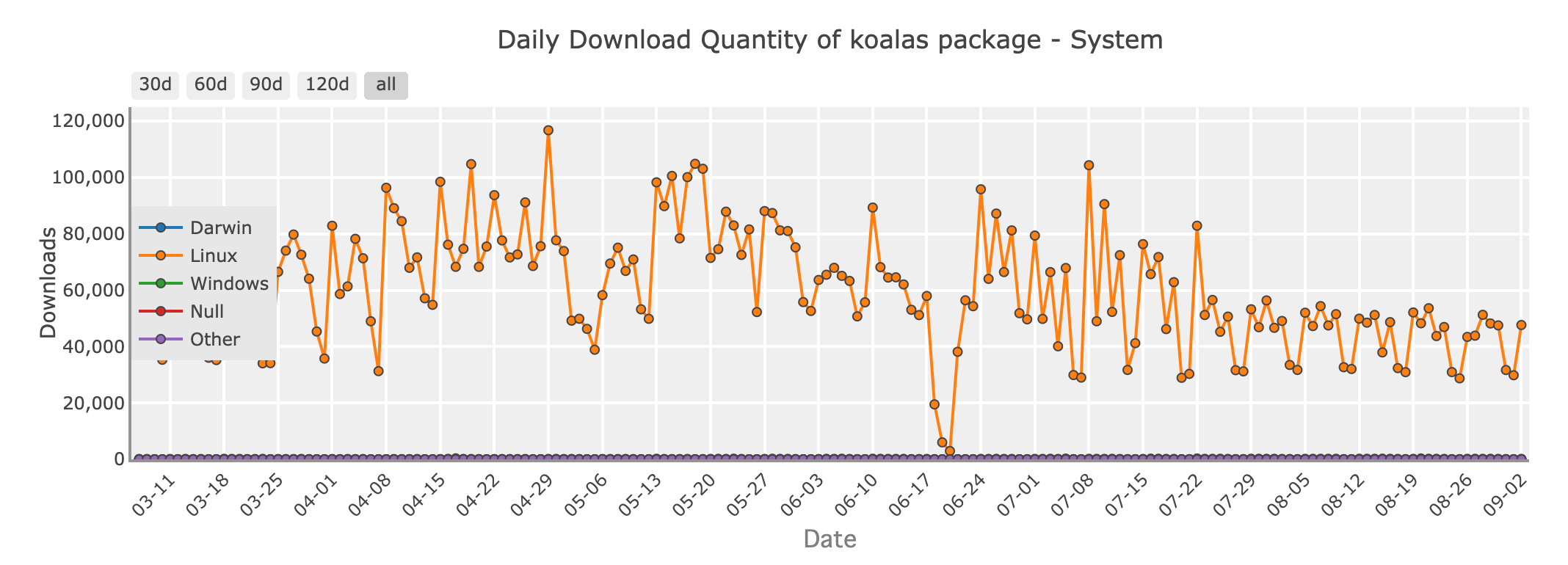
Daily download quantity of Koalas package - system
For Python developers working in the world of big data, Apache Spark is a familiar name. Koalas is a library that connect Pandas to Spark, allowing you to use Pandas-like syntax on distributed datasets managed by Spark. This means you can leverage the scalability of Spark while writing code that feels like Pandas.
Koalas is a great option if you're transitioning from Pandas to big data environments, as it minimizes the learning curve associated with Spark and lets you write code that scales without losing the simplicity of Pandas.
Github stars: 3300
Choosing the Right Tool for the Job
With so many options available, how do you choose the right DataFrame library for your project? Here are some guidelines:
- Small to Medium Datasets: If your data fits comfortably in memory, Pandas is still the best choice for its ease of use and rich functionality.
- Scaling Pandas: If you're hitting performance bottlenecks with Pandas, but don't want to change your code, Modin offers an easy path to faster execution.
- Performance-Critical Tasks: For high-performance needs and large datasets, Polars offers impressive speed and efficiency due to its lightweight design, making it particularly effective on local devices. However, it's important to note that Polars is not primarily designed for distributed large-scale data processing, where solutions like Modin might be more appropriate.
- Big Data and Distributed Computing: When working with big data, Dask, Koalas, and Xorbits are excellent choices for scaling your computations across multiple machines.
- Interoperability and Data Sharing: If you need efficient data interchange between different systems or languages, PyArrow is the go-to library.
- Cloud-Based Operations: For those leveraging cloud infrastructure, Snowpark offers smooth integration with Snowflake, enabling powerful in-database computations.
Whether you're working with small datasets or tackling massive, distributed data pipelines, there’s a Python library to suit your needs. By exploring these open-source DataFrame libraries, you’ll be better equipped to make full use of your data, no matter the size or complexity.
So, go ahead—dive into the world of DataFrames and unlock the power of Python for your next data-driven adventure!