Exploring Data and Sharing Findings with Pygwalker and Streamlit
In this article, we'll dive into how you can use Pygwalker with Streamlit to analyze and visualize your data. It's going to be a fun and interactive journey, so let's get started!
AI Agent In Jupyter Notebook
Let runcell AI take control of your notebook — automatically executing cells and completing complex data workflows while you focus on insights.
What is Pygwalker?
Pygwalker (opens in a new tab) is a Python library that turns your data into Visual Interface for Data Exploration. PyGWalker can simplify your Jupyter Notebook data analysis and data visualization workflow, by turning your Pandas/Polars/Modin dataframes into a no-code User Interface for visual exploration.
With Pygwalker, you can easily generate scatter plots, line plots, bar charts, and histograms with just a few simple drag-and-drop actions, without the need for coding skills. It's a powerful tool designed specifically for data scientists and analysts who want to explore and visualize their data quickly and effortlessly.
What is Streamlit?
Streamlit is another popular Python library when it comes to building and sharing data apps. It allows you to turn your data scripts into web apps in a matter of minutes, rather than weeks. With Streamlit, you don't have to worry about complex web development or spending endless hours writing code. It's a fast, open-source, and completely free way to create interactive and shareable data applications using Python.
So how to build a visual exploration app with the powerful visual analysis features of pygwalker and publish as a data app in Streamlit? Let's find out!
Getting Started to Use PyGWalker in Streamlit
Before getting started with running PyGWalker in Streamlit, let's make sure your computer is set up with a Python environment (version 3.6 or higher). Once that's done, follow these simple steps:
Installing Dependencies
To get started, open your command prompt or terminal and run the following commands to install the necessary dependencies:
pip install pandas
pip install pygwalker
pip install streamlitEmbedding Pygwalker in a Streamlit Application
Now that we have all the dependencies in place, let's create a Streamlit application that incorporates Pygwalker. Create a new Python script called pygwalker_demo.py and copy the following code into it:
from pygwalker.api.streamlit import StreamlitRenderer
import pandas as pd
import streamlit as st
# Adjust the width of the Streamlit page
st.set_page_config(
page_title="Use Pygwalker In Streamlit",
layout="wide"
)
# Import your data
df = pd.read_csv("https://kanaries-app.s3.ap-northeast-1.amazonaws.com/public-datasets/bike_sharing_dc.csv")
pyg_app = StreamlitRenderer(df)
pyg_app.explorer()
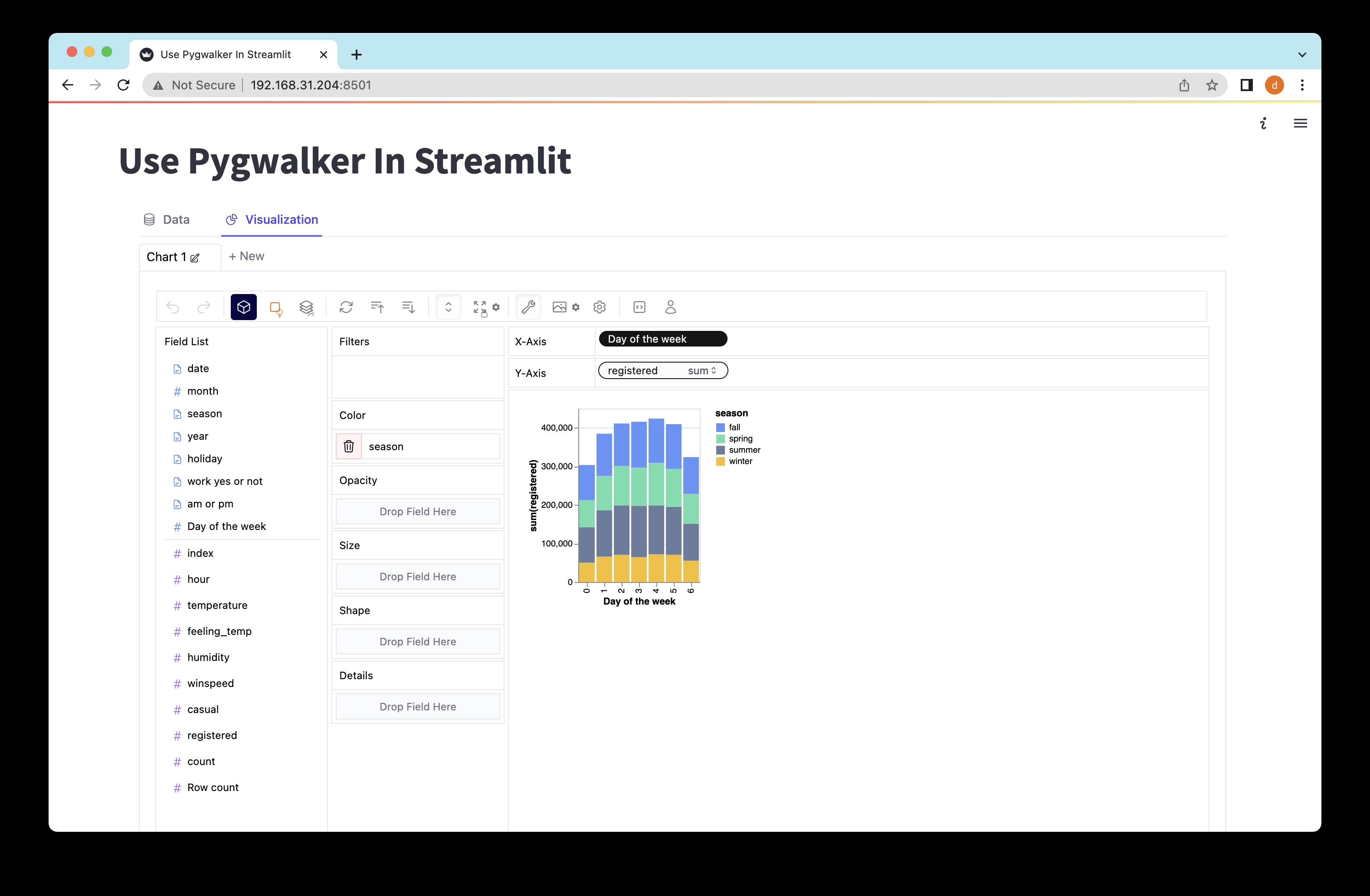
Exploring Data with Pygwalker in Streamlit
To launch the Streamlit application and start exploring your data, run the following command in your command prompt or terminal:
streamlit run pygwalker_demo.pyYou should see some information displayed:
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://xxx.xxx.xxx.xxx:8501Open the provided URL (http://localhost:8501) in your web browser, and voila! You can now interact with your data and visualize it using Pygwalker's intuitive drag-and-drop actions.
Saving Pygwalker Chart State
If you want to save the state of a Pygwalker chart, it's as easy as following these steps:
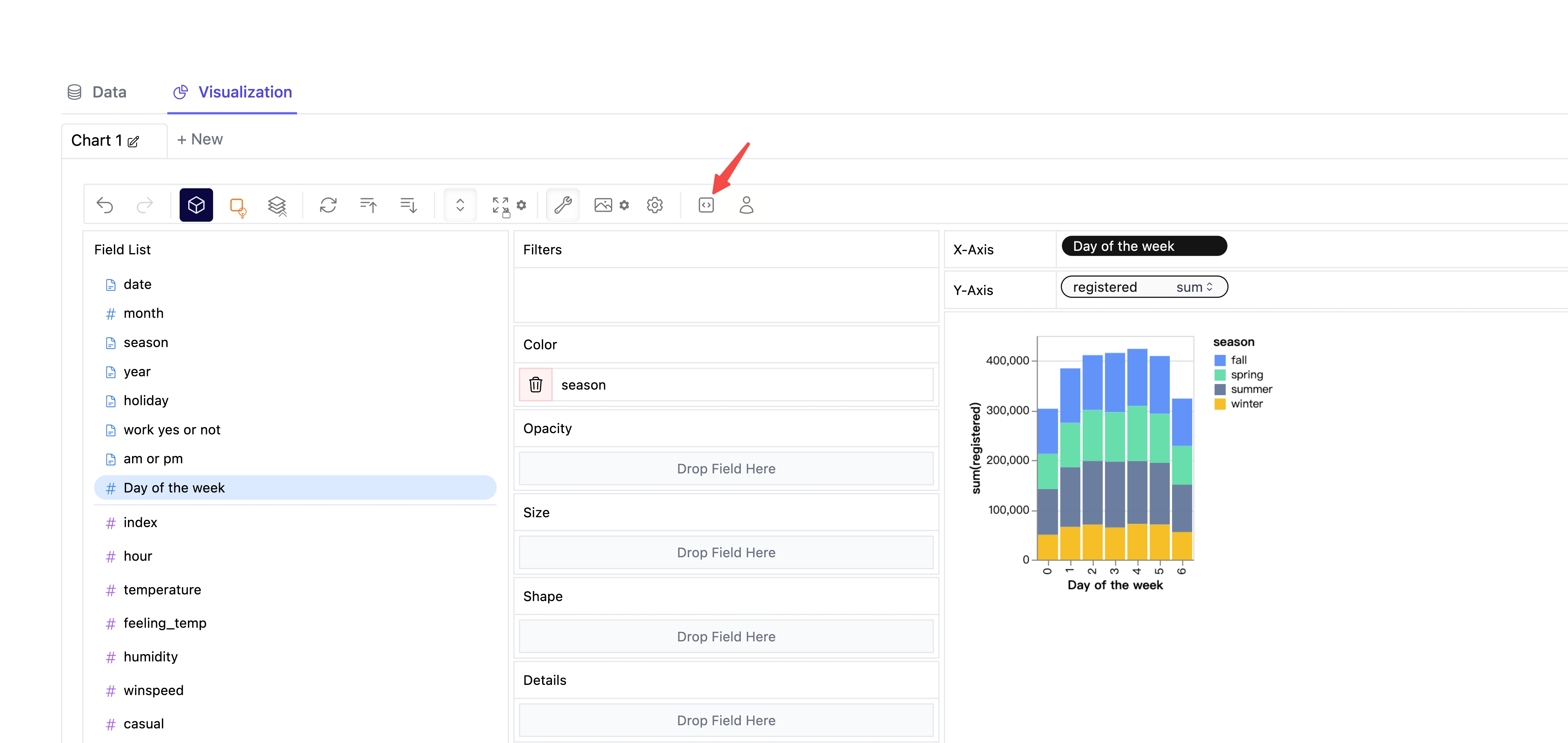
- Click the export button on the chart.
- Click the copy code button.
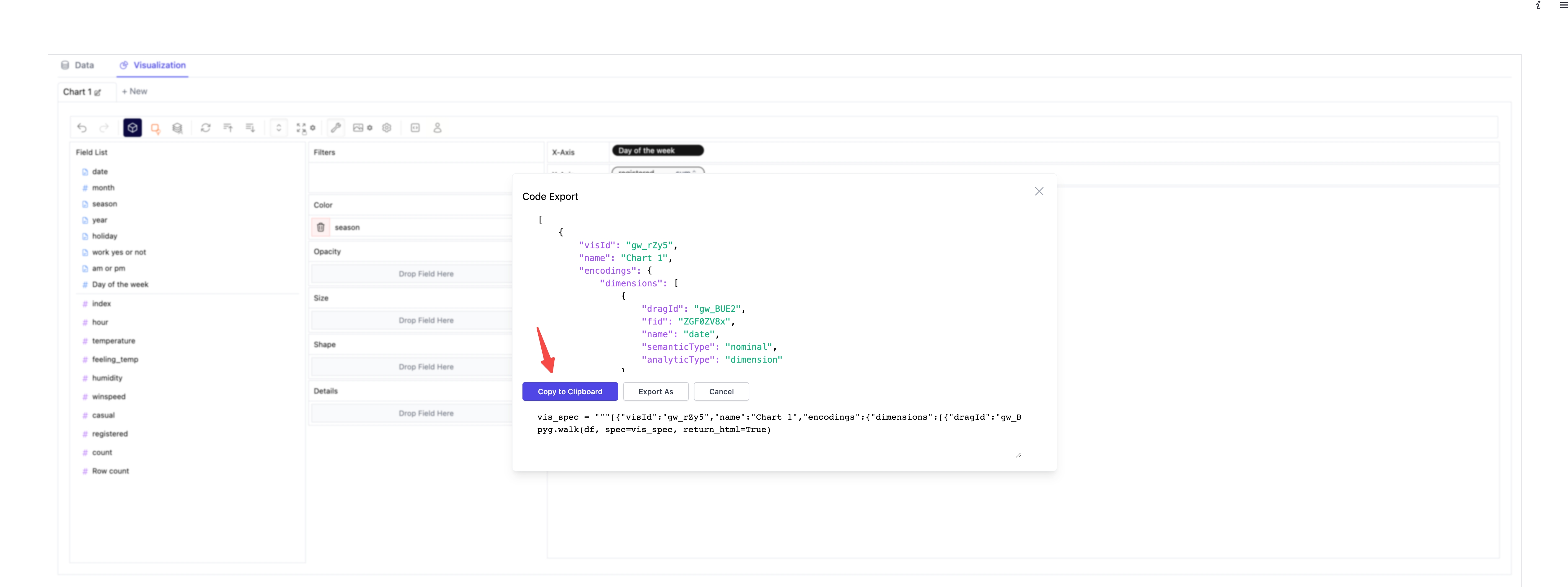
- Paste the copied code into your Python script, just where you need it.
import pygwalker as pyg
import pandas as pd
from pygwalker.api.streamlit import StreamlitRenderer
import streamlit as st
# Adjust the width of the Streamlit page
st.set_page_config(
page_title="Use Pygwalker In Streamlit",
layout="wide"
)
# Add Title
st.title("Use Pygwalker In Streamlit")
# Import your data
df = pd.read_csv("https://kanaries-app.s3.ap-northeast-1.amazonaws.com/public-datasets/bike_sharing_dc.csv")
# Paste the copied Pygwalker chart code here
vis_spec = """<PASTE_COPIED_CODE_HERE>"""
pyg_app = StreamlitRenderer(df, spec=vis_spec)
pyg_app.explorer()- Don't forget to reload the web page to see the saved state of your Pygwalker chart.
Pygwalker is based on graphic-walker which can be embeded in anywhere like excel, airtable. So your pygwalker app can benefit from this feature as well and make collaborations with users in other platforms containing graphic-walker/pygwalker.
Conclusion
Pygwalker and Streamlit are fantastic tools that make data exploration and sharing much easier.
With Pygwalker's intuitive interface and wide range of visualization options, and Streamlit's ability to simplify the process of building and sharing data apps, you can quickly build data apps with a visual UI for data visualization and exploration.
Whether you're a beginner or an experienced data scientist, Pygwalker and Streamlit can enhance your data analysis workflow and help you communicate your findings effectively. So go ahead, explore your data, and share your amazing insights with the world!
lab2.dev - Turn your ideas to python apps with AI. Build Streamlit apps with simple text prompts.→