Qwen3-VL: Open Source Multimodal AI with Advanced Vision

TL;DR — Qwen just released Qwen3‑VL, the newest open‑weight vision‑language series. The flagship Qwen3‑VL‑235B‑A22B (Instruct + Thinking) is open under Apache‑2.0, with native 256K context (extensible to 1M), stronger spatial/video reasoning, and OCR in 32 languages. It targets not just recognition but deeper multimodal reasoning and agentic UI control. It’s huge (~471 GB weights), so most teams will start via APIs or hosted inference. (GitHub (opens in a new tab))
What shipped (and why it matters)
Qwen3‑VL is the latest vision‑language family from the Qwen team. The repo and model cards highlight upgrades across text understanding, visual perception/reasoning, long‑context video comprehension, and agent interaction (e.g., operating PC/mobile GUIs). Architecturally, it introduces Interleaved‑MRoPE for long‑horizon video, DeepStack for multi‑level ViT fusion, and Text–Timestamp Alignment for precise video temporal modeling. (GitHub (opens in a new tab))
The first open‑weight release is the ≈235B‑parameter MoE model (A22B = ~22B experts active per token), provided in Instruct and Thinking editions and licensed Apache‑2.0. The model emphasizes STEM/multimodal reasoning, spatial perception/2D–3D grounding, long‑video understanding, and OCR across 32 languages. (Hugging Face (opens in a new tab))
Release date: Qwen lists the Qwen3‑VL‑235B‑A22B Instruct and Thinking weights as released on Sept 23, 2025. (GitHub (opens in a new tab))
Headline specs at a glance
| Capability | Qwen3‑VL detail |
|---|---|
| Open‑weight variants | 235B A22B Instruct and Thinking (Apache‑2.0) |
| Context length | 256K native, extendable to 1M (Qwen guidance) |
| Vision/Video | Enhanced spatial reasoning, long‑video temporal grounding |
| OCR | 32 languages, robust to low‑light/blur/tilt |
| Agentic | Can read GUIs and plan actions for PC/mobile tasks |
| Size | HF cards report ≈236B params; community notes ~471 GB weights |
| Framework support | Official Transformers integration as of mid‑Sept 2025 |
Sources: repo+cards for features/editions, context length and agent claims; HF docs for Transformers integration; Simon Willison for practical weight size note. (GitHub (opens in a new tab))
What’s new vs. Qwen2.5‑VL?
- Sharper temporal & spatial modeling: Interleaved‑MRoPE + Text–Timestamp Alignment aim to localize events across long videos more precisely than prior T‑RoPE approaches. DeepStack sharpens fine‑grained image–text alignment. (GitHub (opens in a new tab))
- Longer context and broader modality envelope: 256K tokens by default with 1M expansion path; better GUI, document, and long‑video comprehension. (GitHub (opens in a new tab))
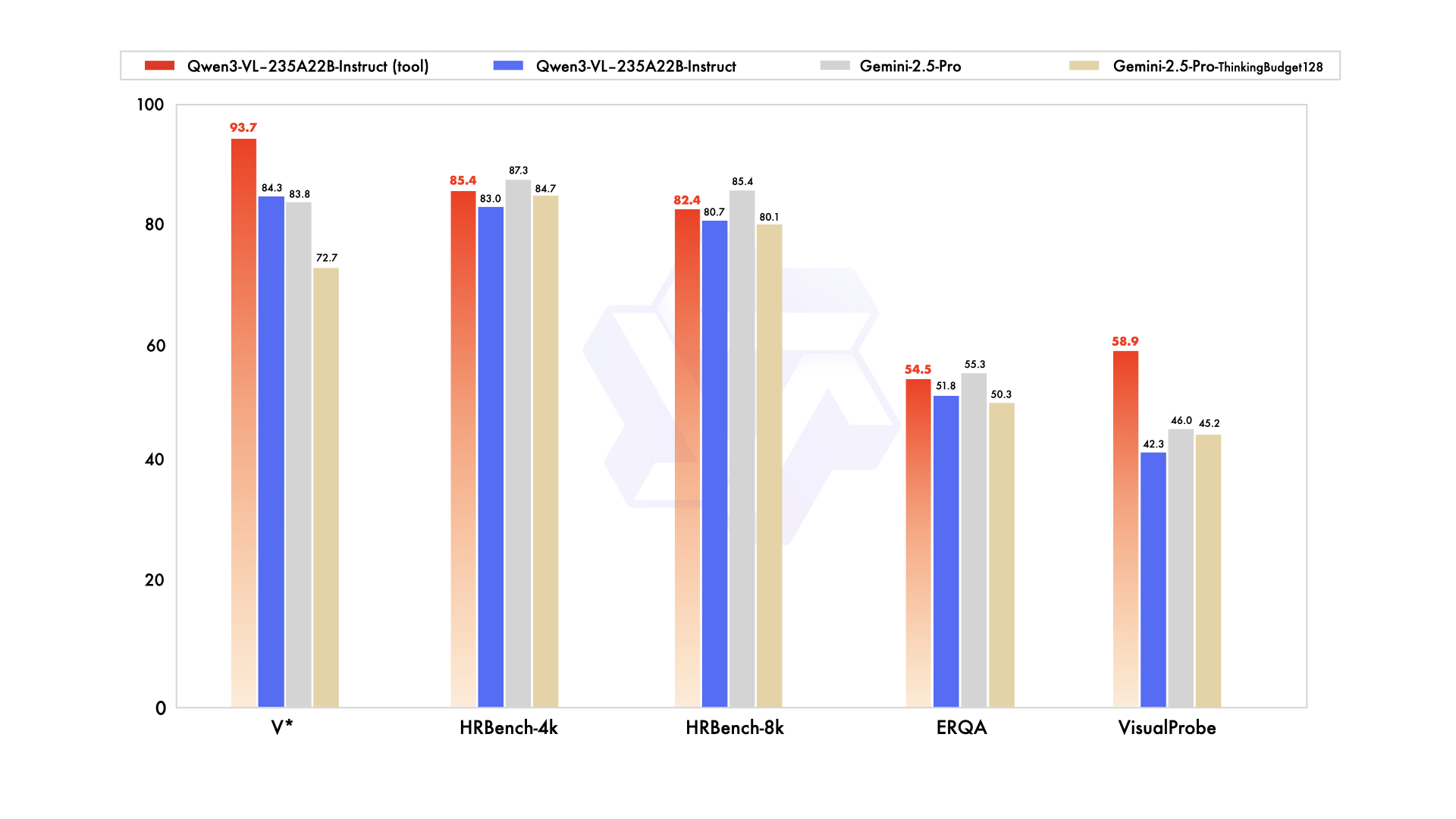
- Bigger, reasoning‑tuned editions: Thinking versions target multimodal reasoning tasks; Qwen claims performance competitive with or exceeding proprietary multimodal baselines on select benchmarks (self‑reported). (Simon Willison’s Weblog (opens in a new tab))
Qwen’s blog and social posts assert parity/lead over Gemini 2.5 Pro on key perception benchmarks and SOTA on several multimodal reasoning sets—worth independent verification. (Simon Willison’s Weblog (opens in a new tab))

Release artifacts & where to run it
-
GitHub: code snippets (Transformers), cookbooks (OCR, grounding, video, agents). Paper is “coming.” (GitHub (opens in a new tab))
-
Hugging Face:
- Qwen3‑VL‑235B‑A22B‑Instruct (Apache‑2.0) (Hugging Face (opens in a new tab))
- Qwen3‑VL‑235B‑A22B‑Thinking (Apache‑2.0) (Hugging Face (opens in a new tab))
-
Transformers support: Qwen3‑VL landed in Transformers docs mid‑Sept 2025. (Hugging Face (opens in a new tab))
-
Hosted options: OpenRouter lists Qwen3‑VL 235B for API use; Alibaba Cloud’s Model Studio offers Qwen‑Plus/Qwen3‑VL‑Plus API SKUs with thinking vs non‑thinking modes and pricing tiers. (OpenRouter (opens in a new tab))
Note on naming: HN readers point out that Qwen3‑VL‑Plus (API) and Qwen‑VL‑Plus (older series) are different, and that qwen‑plus‑2025‑09‑11 snapshot naming can confuse newcomers. You’re not alone. (Hacker News (opens in a new tab))
Benchmarks (read with care)
Qwen’s announcement channels claim that Instruct “matches/exceeds” Gemini 2.5 Pro on perception‑heavy tests and that Thinking achieves SOTA on several multimodal reasoning suites. These numbers are self‑reported; independent evals will matter, especially for chart/table understanding, diagram reasoning, and video QA where data curation can swing results. (Simon Willison’s Weblog (opens in a new tab))
That said, early community notes compare Qwen3‑Omni → Qwen3‑VL‑235B on shared sets (e.g., HallusionBench, MMMU‑Pro, MathVision) and suggest meaningful gains—again, not peer‑reviewed yet. (Reddit (opens in a new tab))
Why academia keeps picking Qwen (and will likely adopt Qwen3‑VL fast)
While many business apps default to GPT/Claude/Gemini for convenience and SLAs, research groups often need open weights for reproducibility, auditing, ablation, and domain fine‑tuning. Qwen’s catalog has made that easy:
- Open weights across scales (from sub‑2B to 235B+ MoE), enabling experiments that fit lab GPUs and scale up later. (Qwen (opens in a new tab))
- Permissive licensing (Apache‑2.0 across many checkpoints) reduces friction for academic/industry collaboration. (Hugging Face (opens in a new tab))
- Demonstrated use in papers: e.g., BioQwen biomedical bilingual models; RCP‑Merging that uses Qwen2.5 bases to study long CoT/domain merging; multiple medical VLM RL‑tuning works start from Qwen2.5. (ciblab.net (opens in a new tab))
With Qwen3‑VL adding long‑video and spatial grounding improvements while staying open‑weight, expect it to become a default baseline for multimodal academic projects, particularly in document intelligence, scientific diagrams, medical VQA, and embodied/agentic research.
For product teams: practical guidance
- Start hosted, then optimize: The flagship model is huge (community notes: ~471 GB weights). Unless you have multi‑GPU (A100/H100/MI300) clusters, begin via an API (e.g., OpenRouter, Alibaba Model Studio), then revisit local/edge deployment when smaller Qwen3‑VL sizes arrive (as happened with Qwen2.5‑VL 72B/32B/7B/3B). (Simon Willison’s Weblog (opens in a new tab))
- “Thinking” ≠ always better: Qwen’s APIs expose thinking vs non‑thinking modes with different token budgets and pricing. Use thinking selectively (e.g., long/ambiguous multimodal tasks). (AlibabaCloud (opens in a new tab))
- Mind context costs: 256K–1M contexts are powerful but expensive. Chunk documents/video smartly; rely on pre‑parsing (OCR/layout) and RAG to minimize prompt bloat. (GitHub (opens in a new tab))
- Agentic UX: If you need UI‑automation from screenshots or screen streams, Qwen3‑VL’s visual agent features are worth piloting—but invest in robust tool APIs and guardrails. (GitHub (opens in a new tab))
Quickstart (Transformers)
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor # HF >= 4.57
model_id = "Qwen/Qwen3-VL-235B-A22B-Instruct" # or ...-Thinking
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(model_id, dtype="auto", device_map="auto")
processor = AutoProcessor.from_pretrained(model_id)
messages = [{"role": "user", "content": [
{"type": "image", "image": "https://.../app-screenshot.png"},
{"type": "text", "text": "What button should I tap to turn on dark mode? Explain briefly."}
]}]
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(processor.batch_decode(outputs[:, inputs["input_ids"].shape[1]:], skip_special_tokens=True)[0])This mirrors Qwen’s model‑card example (enable FlashAttention‑2 if available). For multi‑image or video, pass multiple {"type": "image"} entries or a {"type": "video"} item with frame/pixel controls as shown in the repo. (Hugging Face (opens in a new tab))
Common pitfalls & gotchas
- Naming drift: “Qwen3‑VL‑Plus” (API) vs. Qwen‑VL‑Plus (older open‑weight line) are not the same. Check the Model Studio docs and the HF page you’re actually loading. (Hacker News (opens in a new tab))
- Memory illusions: The 235B MoE is open weights, but “MoE” doesn’t make it small for inference. Budget memory and bandwidth accordingly. Community notes peg the weights around 471 GB. (Simon Willison’s Weblog (opens in a new tab))
- Self‑reported leaderboards: Treat marketing charts as hypotheses. Re‑run your own evals—especially for charts/tables, docs, and video QA.
FAQ
Q: What does “A22B” mean in Qwen3‑VL‑235B‑A22B? A: It’s a Mixture‑of‑Experts model with ~235B total parameters and ~22B active per token—trading compute efficiency for capacity. (Qwen (opens in a new tab))
Q: Instruct vs Thinking—when should I pick each? A: Instruct is aligned for general use and tends to be faster/cheaper. Thinking adds reasoning traces internally (API exposes “thinking mode”), which can help on compositional or long‑horizon tasks but costs more tokens. Try both on your eval set. (Hugging Face (opens in a new tab))
Q: Is it really “better than Gemini 2.5 Pro”? A: Qwen claims wins on selected perception benchmarks and SOTA on several multimodal tasks, but those are self‑reported. Independent comparisons will take time—watch the community evals and your domain‑specific tests. (Simon Willison’s Weblog (opens in a new tab))
Q: Can I run it locally? A: Only if you have serious hardware (multi‑GPU with high‑RAM). Most teams will use hosted inference first (e.g., OpenRouter, Model Studio). For smaller local trials, consider older Qwen2.5‑VL sizes (72B/32B/7B/3B) until smaller Qwen3‑VL variants arrive. (OpenRouter (opens in a new tab))
Q: What’s the license situation? A: The released Qwen3‑VL‑235B‑A22B weights are under Apache‑2.0 per the HF model cards. Always confirm the specific checkpoint’s license. (Hugging Face (opens in a new tab))
Q: Why do researchers keep choosing Qwen? A: Open weights across sizes, permissive licensing, and strong multilingual capability—plus lots of examples of Qwen‑based fine‑tunes in the literature (e.g., BioQwen, long‑CoT model merging, medical VQA RL‑tuning starting from Qwen2.5). (ciblab.net (opens in a new tab))
Community reaction and discussion
The Hacker News thread quickly surfaced naming confusion (Qwen3‑VL‑Plus vs snapshots like qwen-plus-2025-09-11) and practical deployment questions, but also enthusiasm about the pace of open‑weight releases. It’s a good window into early‑adopter sentiment. (Hacker News (opens in a new tab))
For a concise write‑up from the developer community, see Simon Willison’s note—useful for a sanity check on model size and the likely cadence of smaller follow‑ups. (Simon Willison’s Weblog (opens in a new tab))
Final take
Qwen3‑VL raises the bar for open‑weight multimodal models by pushing beyond “recognize this image” toward reason‑about‑and‑act across images, documents, and videos—and it lands in a familiar open tooling stack (Transformers). For research, it’s an obvious new baseline. For product teams, the flagship is too big for most self‑hosting today, but it’s immediately valuable via APIs—especially for document intelligence, screen understanding, and video QA. Expect the real inflection when smaller Qwen3‑VL sizes follow the Qwen2.5 pattern.
References & further reading
- Repo: QwenLM/Qwen3‑VL — features, architecture notes, cookbooks, release log. (GitHub (opens in a new tab))
- Model cards: Instruct and Thinking (Apache‑2.0), with quickstarts and performance charts. (Hugging Face (opens in a new tab))
- Transformers docs: Qwen3‑VL integration. (Hugging Face (opens in a new tab))
- Qwen3 overview & MoE sizes (A22B explanation, open‑weighted line‑up). (Qwen (opens in a new tab))
- HN discussion: community impressions and naming confusion. (Hacker News (opens in a new tab))
- API/pricing: Alibaba Cloud Model Studio (thinking vs non‑thinking, token budgets). (AlibabaCloud (opens in a new tab))
- Examples from research using Qwen: BioQwen; RCP‑Merging; medical VQA RL‑tuning on Qwen2.5 bases. (ciblab.net (opens in a new tab))